溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹pytorch如何加載自己的圖像數據集,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
之前學習深度學習算法,都是使用網上現成的數據集,而且都有相應的代碼。到了自己開始寫論文做實驗,用到自己的圖像數據集的時候,才發現無從下手 ,相信很多新手都會遇到這樣的問題。
下面代碼實現了從文件夾內讀取所有圖片,進行歸一化和標準化操作并將圖片轉化為tensor。最后讀取第一張圖片并顯示。
# 數據處理
import os
import torch
from torch.utils import data
from PIL import Image
import numpy as np
from torchvision import transforms
transform = transforms.Compose([
transforms.ToTensor(), # 將圖片轉換為Tensor,歸一化至[0,1]
# transforms.Normalize(mean=[.5, .5, .5], std=[.5, .5, .5]) # 標準化至[-1,1]
])
#定義自己的數據集合
class FlameSet(data.Dataset):
def __init__(self,root):
# 所有圖片的絕對路徑
imgs=os.listdir(root)
self.imgs=[os.path.join(root,k) for k in imgs]
self.transforms=transform
def __getitem__(self, index):
img_path = self.imgs[index]
pil_img = Image.open(img_path)
if self.transforms:
data = self.transforms(pil_img)
else:
pil_img = np.asarray(pil_img)
data = torch.from_numpy(pil_img)
return data
def __len__(self):
return len(self.imgs)
if __name__ == '__main__':
dataSet=FlameSet('./test')
print(dataSet[0])顯示結果:
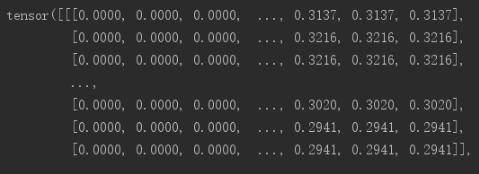
補充知識:使用Pytorch進行讀取本地的MINIST數據集并進行裝載
pytorch中的torchvision.datasets中自帶MINIST數據集,可直接調用模塊進行獲取,也可以進行自定義自己的Dataset類進行讀取本地數據和初始化數據。
1. 直接使用pytorch自帶的MNIST進行下載:
缺點: 下載速度較慢,而且如果中途下載失敗一般得是重新進行執行代碼進行下載:
# # 訓練數據和測試數據的下載 # 訓練數據和測試數據的下載 trainDataset = torchvision.datasets.MNIST( # torchvision可以實現數據集的訓練集和測試集的下載 root="./data", # 下載數據,并且存放在data文件夾中 train=True, # train用于指定在數據集下載完成后需要載入哪部分數據,如果設置為True,則說明載入的是該數據集的訓練集部分;如果設置為False,則說明載入的是該數據集的測試集部分。 transform=transforms.ToTensor(), # 數據的標準化等操作都在transforms中,此處是轉換 download=True # 瞎子啊過程中如果中斷,或者下載完成之后再次運行,則會出現報錯 ) testDataset = torchvision.datasets.MNIST( root="./data", train=False, transform=transforms.ToTensor(), download=True )
2. 自定義dataset類進行數據的讀取以及初始化。
其中自己下載的MINIST數據集的內容如下:
自己定義的dataset類需要繼承: Dataset
需要實現必要的魔法方法:
__init__魔法方法里面進行讀取數據文件
__getitem__魔法方法進行支持下標訪問
__len__魔法方法返回自定義數據集的大小,方便后期遍歷
示例如下:
class DealDataset(Dataset):
"""
讀取數據、初始化數據
"""
def __init__(self, folder, data_name, label_name,transform=None):
(train_set, train_labels) = load_minist_data.load_data(folder, data_name, label_name) # 其實也可以直接使用torch.load(),讀取之后的結果為torch.Tensor形式
self.train_set = train_set
self.train_labels = train_labels
self.transform = transform
def __getitem__(self, index):
img, target = self.train_set[index], int(self.train_labels[index])
if self.transform is not None:
img = self.transform(img)
return img, target
def __len__(self):
return len(self.train_set)其中load_minist_data.load_data也是我們自己寫的讀取數據文件的函數,即放在了load_minist_data.py中的load_data函數中。具體實現如下:
def load_data(data_folder, data_name, label_name):
"""
data_folder: 文件目錄
data_name: 數據文件名
label_name:標簽數據文件名
"""
with gzip.open(os.path.join(data_folder,label_name), 'rb') as lbpath: # rb表示的是讀取二進制數據
y_train = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(os.path.join(data_folder,data_name), 'rb') as imgpath:
x_train = np.frombuffer(
imgpath.read(), np.uint8, offset=16).reshape(len(y_train), 28, 28)
return (x_train, y_train)編寫完自定義的dataset就可以進行實例化該類并裝載數據:
# 實例化這個類,然后我們就得到了Dataset類型的數據,記下來就將這個類傳給DataLoader,就可以了。
trainDataset = DealDataset('MNIST_data/', "train-images-idx3-ubyte.gz","train-labels-idx1-ubyte.gz",transform=transforms.ToTensor())
testDataset = DealDataset('MNIST_data/', "t10k-images-idx3-ubyte.gz","t10k-labels-idx1-ubyte.gz",transform=transforms.ToTensor())
# 訓練數據和測試數據的裝載
train_loader = dataloader.DataLoader(
dataset=trainDataset,
batch_size=100, # 一個批次可以認為是一個包,每個包中含有100張圖片
shuffle=False,
)
test_loader = dataloader.DataLoader(
dataset=testDataset,
batch_size=100,
shuffle=False,
)構建簡單的神經網絡并進行訓練和測試:
class NeuralNet(nn.Module):
def __init__(self, input_num, hidden_num, output_num):
super(NeuralNet, self).__init__()
self.fc1 = nn.Linear(input_num, hidden_num)
self.fc2 = nn.Linear(hidden_num, output_num)
self.relu = nn.ReLU()
def forward(self,x):
x = self.fc1(x)
x = self.relu(x)
y = self.fc2(x)
return y
# 參數初始化
epoches = 5
lr = 0.001
input_num = 784
hidden_num = 500
output_num = 10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 產生訓練模型對象以及定義損失函數和優化函數
model = NeuralNet(input_num, hidden_num, output_num)
model.to(device)
criterion = nn.CrossEntropyLoss() # 使用交叉熵作為損失函數
optimizer = optim.Adam(model.parameters(), lr=lr)
# 開始循環訓練
for epoch in range(epoches): # 一個epoch可以認為是一次訓練循環
for i, data in enumerate(train_loader):
(images, labels) = data
images = images.reshape(-1, 28*28).to(device)
labels = labels.to(device)
output = model(images) # 經過模型對象就產生了輸出
loss = criterion(output, labels.long()) # 傳入的參數: 輸出值(預測值), 實際值(標簽)
optimizer.zero_grad() # 梯度清零
loss.backward()
optimizer.step()
if (i+1) % 100 == 0: # i表示樣本的編號
print('Epoch [{}/{}], Loss: {:.4f}'
.format(epoch + 1, epoches, loss.item())) # {}里面是后面需要傳入的變量
# loss.item
# 開始測試
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.reshape(-1, 28*28).to(device) # 此處的-1一般是指自動匹配的意思, 即不知道有多少行,但是確定了列數為28 * 28
# 其實由于此處28 * 28本身就已經等于了原tensor的大小,所以,行數也就確定了,為1
labels = labels.to(device)
output = model(images)
_, predicted = torch.max(output, 1)
total += labels.size(0) # 此處的size()類似numpy的shape: np.shape(train_images)[0]
correct += (predicted == labels).sum().item()
print("The accuracy of total {} images: {}%".format(total, 100 * correct/total))以上是pytorch如何加載自己的圖像數據集的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





