溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Python崗位必備的面試題目,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去探討吧!
Python面試(一)交換變量值
平時時不時會面面實習生,大多數的同學在學校里都已經掌握了Python。面試的時候要求同學們實現一個簡單的函數,交換兩個變量的值,大多數的同學給出的都是如下的答案:

實際上,Python中還有更簡潔的更具Python風格的實現,如下:
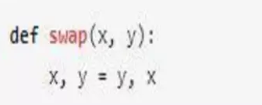
相比前一種方法,后一種方法節省一個中間變量,在性能上也優于前一種方法。
我們從Python的字節碼來深入分析一下原因。
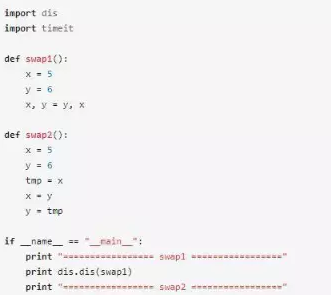
dis是個反匯編工具,將Python代碼翻譯成字節碼指令。這里的輸出如下:

通過字節碼可以看到,swap1和swap2最大的區別在于,swap1中通過ROT_TWO交換棧頂的兩個元素實現x和y值的互換,swap2中引入了tmp變量,多了一次LOAD_FAST, STORE_FAST的操作。執行一個ROT_TWO指令比執行一個LOAD_FAST+STORE_FAST的指令快,這也是為什么swap1比swap2性能更好的原因。
Python面試(二) is 和 == 的區別
面試實習生的時候,當問到 is 和 == 的區別時,很多同學都答不上來,搞不清兩者什么時候返回一致,什么時候返回不一致。本文我們來看一下這兩者的區別。
我們先來看幾個例子:
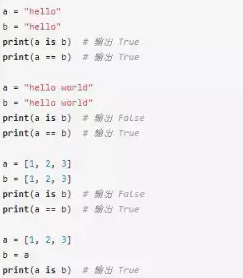
上面的輸出結果中為什么有的 is 和 == 的結果相同,有的不相同呢?我們來看下官方文檔中對于 is 和 == 的解釋。
官方文檔中說 is 表示的是對象標示符(object identity),而 == 表示的是相等(equality)。is 的作用是用來檢查對象的標示符是否一致,也就是比較兩個對象在內存中的地址是否一樣,而 == 是用來檢查兩個對象是否相等。
我們在檢查 a is b 的時候,其實相當于檢查 id(a) == id(b)。而檢查 a == b 的時候,實際是調用了對象 a 的 __eq()__ 方法,a == b 相當于 a.__eq__(b)。
一般情況下,如果 a is b 返回True的話,即 a 和 b 指向同一塊內存地址的話,a == b 也返回True,即 a 和 b 的值也相等。
好了,看明白上面的解釋后,我們來看下前面的幾個例子:
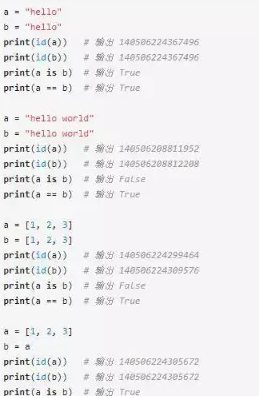
打印出 id(a) 和 id(b) 后就很清楚了。只要 a 和 b 的值相等,a == b 就會返回True,而只有 id(a) 和 id(b) 相等時,a is b 才返回 True。
這里還有一個問題,為什么 a 和 b 都是 "hello" 的時候,a is b 返回True,而 a 和 b都是 "hello world" 的時候,a is b 返回False呢?
這是因為前一種情況下Python的字符串駐留機制起了作用。對于較小的字符串,為了提高系統性能Python會保留其值的一個副本,當創建新的字符串的時候直接指向該副本即可。所以 "hello" 在內存中只有一個副本,a 和 b 的 id 值相同,而 "hello world" 是長字符串,不駐留內存,Python中各自創建了對象來表示 a 和 b,所以他們的值相同但 id 值不同。
同學指出:intern機制和字符串長短無關,在交互模式下,每行字符串字面量都會申請一個新字符串,但是只含大小寫字母、數字和下劃線的會被intern,也就是維護了一張dict來使得這些字符串全局唯一)
總結一下,is 是檢查兩個對象是否指向同一塊內存空間,而 == 是檢查他們的值是否相等。可以看出,is 是比 == 更嚴格的檢查,is 返回True表明這兩個對象指向同一塊內存,值也一定相同。
看到這里,大家是不是搞懂了 is 和 == 的區別呢?
讓我們深入一步來思考一下下面這個問題:
Python里和None比較時,為什么是 is None 而不是 == None 呢?
Python面試(三)可變對象和不可變對象
上一個面試題:Python面試之 is 和 == 的區別的最后留了一個問題:
Python里和None比較時,為什么是 is None 而不是 == None 呢?
這是因為None在Python里是個單例對象,一個變量如果是None,它一定和None指向同一個內存地址。而 == None背后調用的是__eq__,而__eq__可以被重載,下面是一個 is not None但 == None的例子:

好了,解答就到這里,我們開始本篇的正題。
Python中有可變對象和不可變對象之分。可變對象創建后可改變但地址不會改變,即變量指向的還是原來的變量;不可變對象創建之后便不能改變,如果改變則會指向一個新的對象。
Python中dict、list是可變對象,str、int、tuple、float是不可變對象。
來看一個字符串的例子:
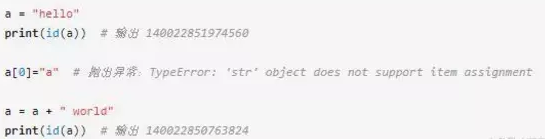
上面的例子里,修改a指向的對象的值會導致拋出異常。
執行 a = a + " world"時,先計算等號右邊的表達式,生成一個新的對象賦值到變量a,因此a指向的對象發生了改變,id(a) 的值也與原先不同。
再來看一個列表的例子:

上面對a修改元素、添加元素,變量a還是指向原來的對象。
將a賦值給b后,變量b和a都指向同一個對象,因此修改b的元素值也會影響a。
變量c是對b的切片操作的返回值,切片操作相當于淺拷貝,會生成一個新的對象,因此c指向的對象不再是b所指向的對象,對c的操作不會改變b的值。
理解了上面不可變對象和可變對象的區別后,我們再來看一個有趣的問題:
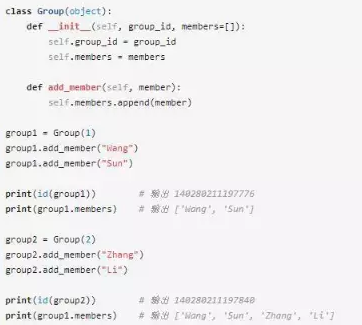
明明group1和group2是不同的對象(id值不同),為什么調用group2的add_member方法會影響group1的members?
其中的奧妙就在于__init__函數的第二個參數是默認參數,默認參數的默認值在函數創建的時候就生成了,每次調用都是用了這個對象的緩存。我們檢查id(group1.mebers)和id(group2.members),可以發現他們是相同的。
print(id(group1.members)) # 輸出 140127132522040 print(id(group2.members)) # 輸出 140127132522040
所以,group1.members和group2.members指向了同一個對象,對group2.members的修改也會影響group1.members。
那么問題來了,怎樣修改代碼才能解決上面默認參數的問題呢?
Python面試(四)連接字符串用join還是+
上一個面試題:Python面試之可變對象和不可變對象的最后留了一個問題:
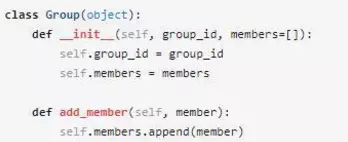
上述代碼中默認參數值對象會被緩存,造成Group類型的對象共享同一個members列表,怎樣才能解決這個問題呢?
其實很簡單,只要傳入None作為默認參數,在創建對象的時候動態生成列表,如下:
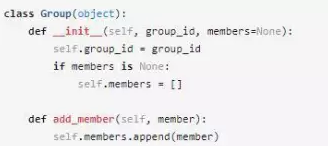
這樣對于不同的group對象,它們的members也是不同的對象,所以不會再出現更新一個group對象的members也會更新另外一個group對象的members了。
本篇要講的是,連接字符串的時候可以用join也可以用+,但這兩者有沒有區別呢?
我們先來看一下用join和+連接字符串的例子:
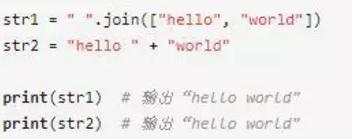
兩者的結果是一樣,那么考慮這樣一個問題,這兩者在性能上有區別嗎?
我們來做個實驗,比較下join和+的性能:
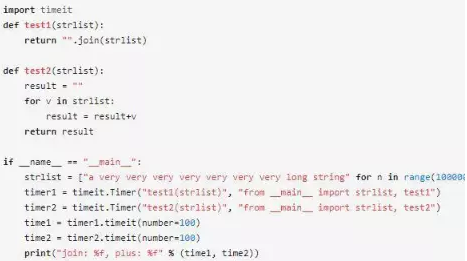
上面的程序有如下的輸出:
join: 0.116944, plus: 0.394379
可以看到,join的性能明顯好于+。這是為什么呢?
原因是這樣的,上一篇Python面試之可變對象和不可變對象中講過字符串是不可變對象,當用操作符+連接字符串的時候,每執行一次+都會申請一塊新的內存,然后復制上一個+操作的結果和本次操作的右操作符到這塊內存空間,因此用+連接字符串的時候會涉及好幾次內存申請和復制。而join在連接字符串的時候,會先計算需要多大的內存存放結果,然后一次性申請所需內存并將字符串復制過去,這是為什么join的性能優于+的原因。所以在連接字符串數組的時候,我們應考慮優先使用join。
Python面試(五)理解__new__和__init__的區別
很多同學都以為Python中的__init__是構造方法,但其實不然,Python中真正的構造方法是__new__。__init__和__new__有什么區別?本文就來探討一下。
我們先來看一下__init__的用法:
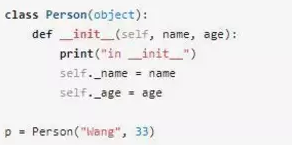
上面的代碼會輸出如下的結果:
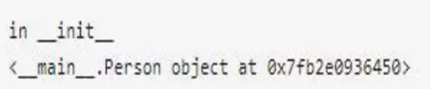
那么我們思考一個問題,Python中要實現Singleton怎么實現,要實現工廠模式怎么實現?
用__init__函數似乎沒法做到呢~
實際上,__init__函數并不是真正意義上的構造函數,__init__方法做的事情是在對象創建好之后初始化變量。真正創建實例的是__new__方法。
我們來看下面的例子:
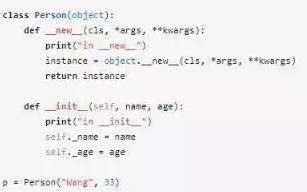
上面的代碼輸出如下的結果:

上面的代碼中實例化了一個Person對象,可以看到__new__和__init__都被調用了。__new__方法用于創建對象并返回對象,當返回對象時會自動調用__init__方法進行初始化。__new__方法是靜態方法,而__init__是實例方法。
好了,理解__new__和__init__的區別后,我們再來看一下前面提出的問題,用Python怎么實現Singleton,怎么實現工廠模式?
先來看Singleton:
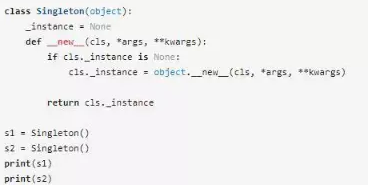
上面的代碼輸出:

可以看到s1和s2都指向同一個對象,實現了單例模式。
再來看下工廠模式的實現:

上面的代碼輸出:

看完上面兩個例子,大家是不是對__new__和__init__的區別有了更深入的理解?
Python面試(六)with與上下文管理器With基本語法
Python老司機應該對下面的語法不陌生:
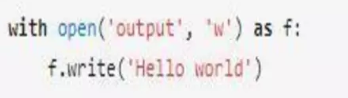
上面的代碼往output文件寫入了Hello world字符串,with語句會在執行完代碼塊后自動關閉文件。這里無論寫文件的操作成功與否,是否有異常拋出,with語句都會保證文件被關閉。
如果不用with,我們可能要用下面的代碼實現類似的功能:
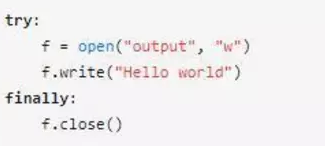
可以看到使用了with的代碼比上面的代碼簡潔許多。
上面的with代碼背后發生了些什么?我們來看下它的執行流程:
首先執行open('output', 'w'),返回一個文件對象;
調用這個文件對象的__enter__方法,并將__enter__方法的返回值賦值給變量f;
執行with語句體,即with語句包裹起來的代碼塊;
不管執行過程中是否發生了異常,執行文件對象的__exit__方法,在__exit__方法中關閉文件。
這里的關鍵在于open返回的文件對象實現了__enter__和__exit__方法。一個實現了__enter__和__exit__方法的對象就稱之為上下文管理器。
上下文管理器
上下文管理器定義執行 with 語句時要建立的運行時上下文,負責執行 with 語句塊上下文中的進入與退出操作。__enter__方法在語句體執行之前進入運行時上下文,__exit__在語句體執行完后從運行時上下文退出。
在實際應用中,__enter__一般用于資源分配,如打開文件、連接數據庫、獲取線程鎖;__exit__一般用于資源釋放,如關閉文件、關閉數據庫連接、釋放線程鎖。
自定義上下文管理器
既然上下文管理器就是實現了__enter__和__exit__方法的對象,我們能不能定義自己的上下文管理器呢?答案是肯定的。
我們先來看下__enter__和__exit__方法的定義:
__enter__() - 進入上下文管理器的運行時上下文,在語句體執行前調用。如果有as子句,with語句將該方法的返回值賦值給 as 子句中的 target。
__exit__(exception_type, exception_value, traceback) - 退出與上下文管理器相關的運行時上下文,返回一個布爾值表示是否對發生的異常進行處理。如果with語句體中沒有異常發生,則__exit__的3個參數都為None,即調用 __exit__(None, None, None),并且__exit__的返回值直接被忽略。如果有發生異常,則使用 sys.exc_info 得到的異常信息為參數調用__exit__(exception_type, exception_value, traceback)。出現異常時,如果__exit__(exception_type, exception_value, traceback)返回 False,則會重新拋出異常,讓with之外的語句邏輯來處理異常;如果返回 True,則忽略異常,不再對異常進行處理。
理解了__enter__和__exit__方法后,我們來自己定義一個簡單的上下文管理器。這里不做實際的資源分配和釋放,而用打印語句來表明當前的操作。

運行上面的代碼,會得到如下的輸出:

我們在with語句體中人為地拋出一個異常:
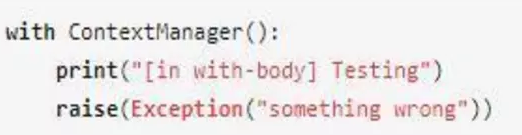
會得到如下的輸出:

如我們所期待,with語句體中拋出異常,__exit__方法中exception_type不為None,__exit__方法返回False,異常被重新拋出。
以上,我們通過實現__enter__和__exit__方法來實現了一個自定義的上下文管理器。
contextlib庫
除了上面的方法,我們也可以使用contextlib庫來自定義上下文管理器。如果用contextlib來實現,可以用下面的代碼來實現類似的上下文管理器:
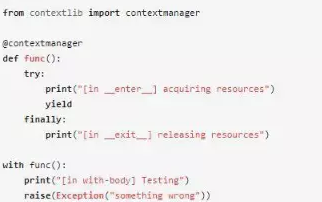
上面的代碼涉及到裝飾器(@contextmanager),生成器(yield),有點難讀。這里yield之前的代碼相當于__enter__方法,在進入with語句體之前執行,yield之后的代碼相當于__exit__方法,在退出with語句體的時候執行。
Python面試(七)你真的理解finally了嗎?
無論try語句中是否拋出異常,finally中的語句一定會被執行。我們來看下面的例子:
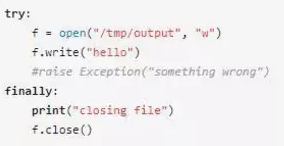
不論try中寫文件的過程中是否有異常,finally中關閉文件的操作一定會執行。由于finally的這個特性,finally經常被用來做一些清理工作。
我們再來看下面的例子:

這個例子中 func1() 和 func2() 返回什么呢?
答案是 func1() 返回2, func2() 返回3。為什么是這樣的呢?我們先來看一段Python官網上對于finally的解釋:
A finally clause is always executed before leaving the try statement, whether an exception has occurred or not. When an exception has occurred in the try clause and has not been handled by an except clause (or it has occurred in a except or else clause), it is re-raised after the finally clause has been executed. The finally clause is also executed “on the way out” when any other clause of the try statement is left via a break, continue or return statement.
重點部分用粗體標出了,翻成中文就是try塊中包含break、continue或者return語句的,在離開try塊之前,finally中的語句也會被執行。
所以在上面的例子中,func1() 中,在try塊return之前,會執行finally中的語句,try中的return被忽略了,最終返回的值是finally中return的值。func2() 中,try塊中拋出異常,被except捕獲,在except塊return之前,執行finally中的語句,except中的return被忽略,最終返回的值是finally中return的值。
我們在上面的例子中加入print語句,可以更清楚地看到過程:
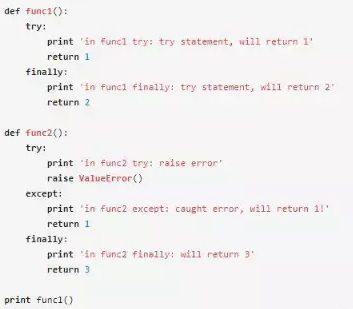
上面的代碼輸出:

我們對上面的func2做一些修改,如下:

輸出如下:

try中拋出的異常是ValueError類型的,而except中定位的是IndexError類型的,try中拋出的異常沒有被捕獲到,所以except中的語句沒有被執行,但不論異常有沒有被捕獲,finally還是會執行,最終函數返回了finally中的返回值3。
這里還可以看到另外一個問題。try中拋出的異常沒有被捕獲到,按理說當finally執行完畢后,應該被再次拋出,但finally里執行了return,導致異常被丟失。
可以看到在finally中使用return會導致很多問題。實際應用中,不推薦在finally中使用return返回。
看完了這篇文章,相信你對Python崗位必備的面試題目有了一定的了解,想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





