溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“HashMap面試會問的題目有哪些”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
在講 Map 之前,我們先來看看 Set。
集合的概念我們初中數學就學過了,就是里面不能有重復元素,這里也是一樣。
Set 在 Java 中是一個接口,可以看到它是 java.util 包中的一個集合框架類,具體的實現類有很多:
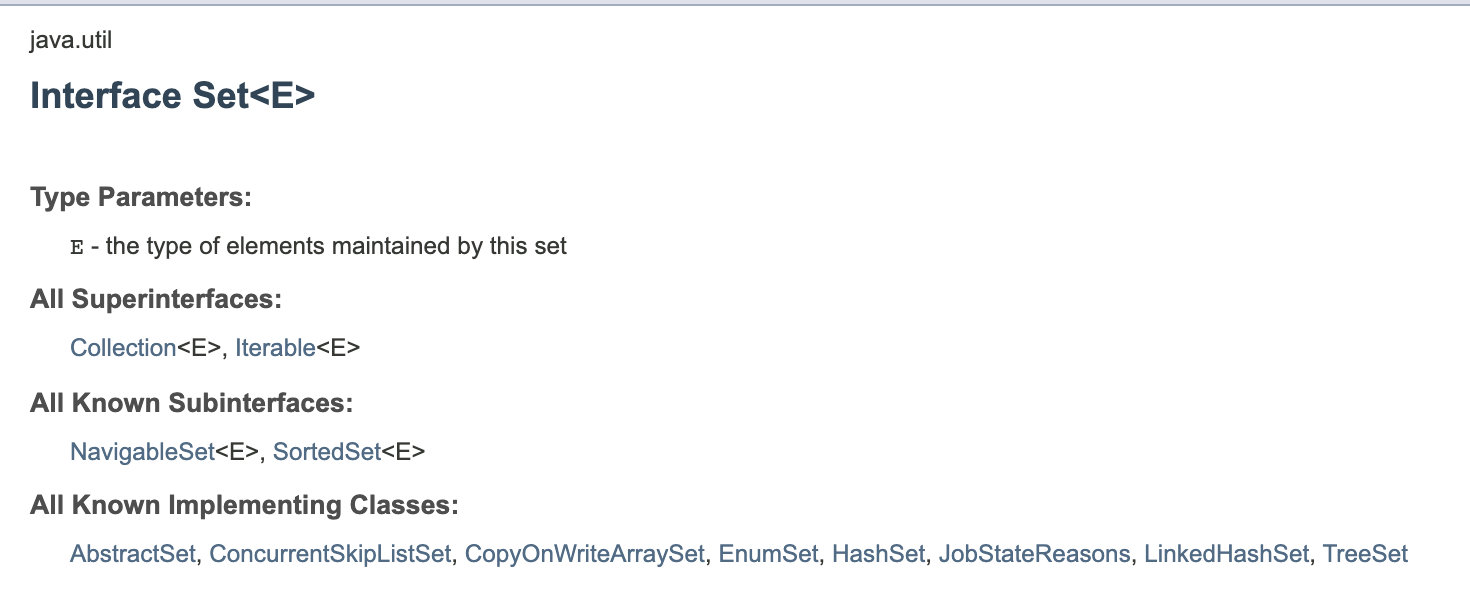
其中比較常用的有三種:
HashSet: 采用 Hashmap 的 key 來儲存元素,主要特點是無序的,基本操作都是 O(1) 的時間復雜度,很快。
LinkedHashSet: 這個是一個 HashSet + LinkedList 的結構,特點就是既擁有了 O(1) 的時間復雜度,又能夠保留插入的順序。
TreeSet: 采用紅黑樹結構,特點是可以有序,可以用自然排序或者自定義比較器來排序;缺點就是查詢速度沒有 HashSet 快。
Map 是一個鍵值對 (Key - Value pairs),其中 key 是不可以重復的,畢竟 set 中的 key 要存在這里面。
那么與 Set 相對應的,Map 也有這三個實現類:
HashMap: 與 HashSet 對應,也是無序的,O(1)。
LinkedHashMap: 這是一個「HashMap + 雙向鏈表」的結構,落腳點是 HashMap,所以既擁有 HashMap 的所有特性還能有順序。
TreeMap: 是有序的,本質是用二叉搜索樹來實現的。
對于 HashMap 中的每個 key,首先通過 hash function 計算出一個 hash 值,這個hash值就代表了在 buckets 里的編號,而 buckets 實際上是用數組來實現的,所以把這個數值模上數組的長度得到它在數組的 index,就這樣把它放在了數組里。
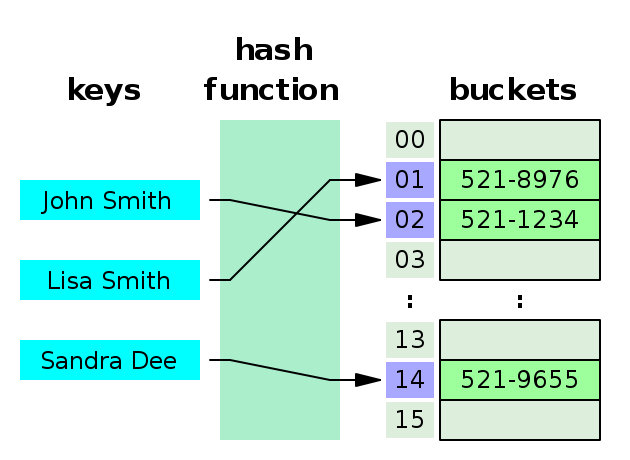
那么這里有幾個問題:
如果不同的元素算出了相同的哈希值,那么該怎么存放呢?
答:這就是哈希碰撞,即多個 key 對應了同一個桶。
HashMap 中是如何保證元素的唯一性的呢?即相同的元素會不會算出不同的哈希值呢?
答:通過 hashCode() 和 equals() 方法來保證元素的唯一性。
如果 pairs 太多,buckets 太少怎么破?
答:Rehasing. 也就是碰撞太多的時候,會把數組擴容至兩倍(默認)。所以這樣雖然 hash 值沒有變,但是因為數組的長度變了,所以算出來的 index 就變了,就會被分配到不同的位置上了,就不用擠在一起了,小伙伴們我們江湖再見~
那什么時候會 rehashing 呢?也就是怎么衡量桶里是不是足夠擁擠要擴容了呢?
答:load factor. 即用 pair 的數量除以 buckets 的數量,也就是平均每個桶里裝幾對。Java 中默認值是 0.75f,如果超過了這個值就會 rehashing.
如果 key 的 hashCode() 值相同,那么有可能是要發生 hash collision 了,也有可能是真的遇到了另一個自己。那么如何判斷呢?繼續用 equals() 來比較。
也就是說,
hashCode() 決定了 key 放在這個桶里的編號,也就是在數組里的 index;
equals() 是用來比較兩個 object 是否相同的。
那么該如何回答這道<span >經典面試題</span>:
<span >為什么重寫 equals() 方法,一定要重寫 hashCode() 呢?
答:首先我們有一個假設:任何兩個 object 的 hashCode 都是不同的。
那么在這個條件下,有兩個 object 是相等的,那如果不重寫 hashCode(),算出來的哈希值都不一樣,就會去到不同的 buckets 了,就迷失在茫茫人海中了,再也無法相認,就和 equals() 條件矛盾了,證畢。
撒花~~????????????
接下來我們再對這兩個方法一探究竟:
其實 hashCode() 和 equals() 方法都是在 Object class 這個老祖宗里定義的,Object 是所有 Java 中的 class 的鼻祖,默認都是有的,甩不掉的。
那既然是白給的,我們先來看看大禮包里有什么,谷歌 Object 的 Oracle 文檔:
所以這些方法都是可以直接拿來用的呢~
回到 hashCode() 和 equals(),那么如果這個新的 class 里沒有重寫 (override) 這兩個方法,就是默認繼承 Object class 里的定義了。
那我們點進去來看看 equals() 是怎么定義的:
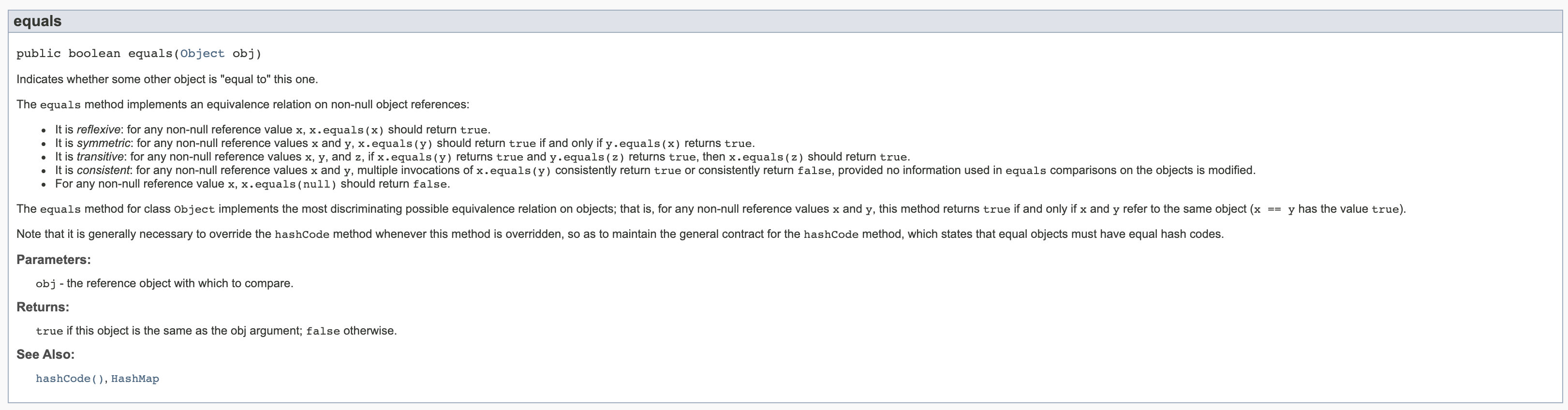
記筆記:
equals() 方法就是比較這兩個 references 是否指向了同一個 object.
嗯???你在逗我嗎??那豈不是和 == 一樣了??
補充:
我們常用的比較大小的符號之==
如果是 primitive type,那么 == 就是比較數值的大小;
如果是 reference type,那么就比較的是這兩個 reference 是否指向了同一個 object。
再補充:
Java 的數據類型可以分為兩種:
Primitive type 有且僅有8種:byte, short, int, long, float, double, char, boolean.
其他都是 Reference type.
所以雖然 Java 聲稱 “Everything is object”,但是還是有非 object 數據類型的存在的。
我不信,我要去源碼里看看它是怎么實現的。

哈,還真是的,繞了這么半天,equals() 就是用 == 來實現的!
那為什么還弄出來這么個方法呢?
<span >答:為了讓你 override~
比如一般來說我們比較字符串就是想比較這兩個字符串的內容的,那么:
str1 = “tianxiaoqi”; str2 = new String(“tianxiaoqi”); str1 == str2; // return false str1.equals(str2); // return true
因為 String 里是重寫了 equals() 方法的:

老祖宗留給你就是讓你自己用的,如果你不用,那人家也提供了默認的方法,也是夠意思了。
好了,我們再去看 hashCode() 的介紹:
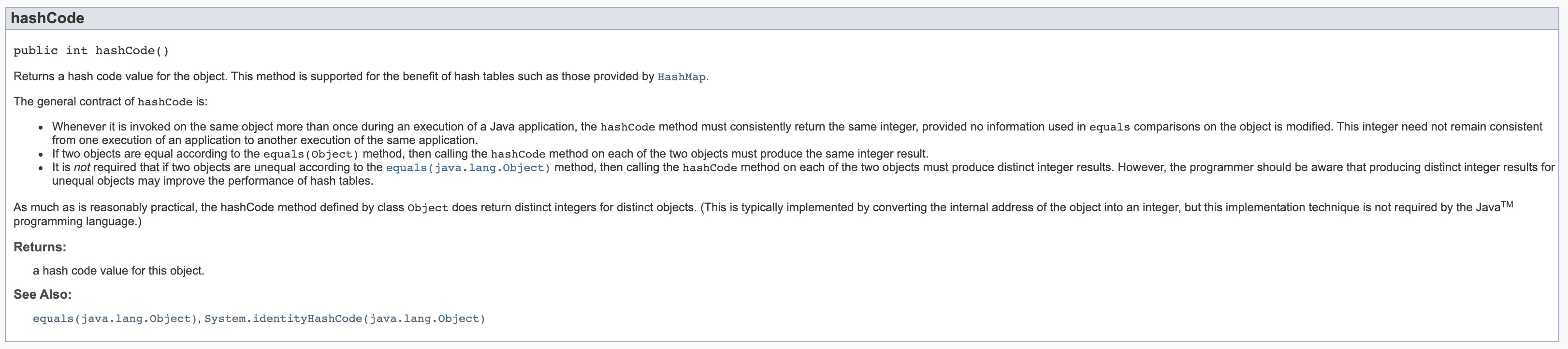
那至于 hashCode() 返回的究竟是什么,和本文關聯不太大,有興趣的同學可以看參考這篇文章,結論就是:
返回的并不一定是對象的(虛擬)內存地址,具體取決于運行時庫和JVM的具體實現。
但無論是怎么實現的,都需要遵循文檔上的約定,也就是對不同的 object 會返回唯一的哈希值。
一般來說哈希沖突有兩大類解決方式
Separate chaining
Open addressing
Java 中采用的是第一種 Separate chaining,即在發生碰撞的那個桶后面再加一條“鏈”來存儲,那么這個“鏈”使用的具體是什么數據結構,不同的版本稍有不同:
在 JDK1.6 和 1.7 中,是用鏈表存儲的,這樣如果碰撞很多的話,就變成了在鏈表上的查找,worst case 就是 O(n);
在 JDK 1.8 進行了優化,當鏈表長度較大時(超過 8),會采用紅黑樹來存儲,這樣大大提高了查找效率。
(話說,這個還真的喜歡考,已經在多次面試中被問過了,還有面試官問為什么是超過“8”才用紅黑樹????)
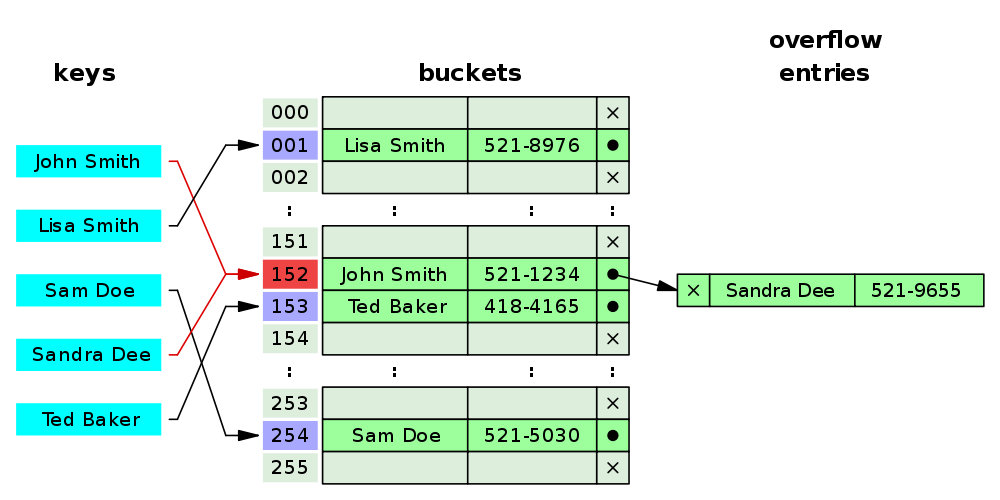
第二種方法 open addressing 也是非常重要的思想,因為在真實的分布式系統里,有很多地方會用到 hash 的思想但又不適合用 seprate chaining。
這種方法是順序查找,如果這個桶里已經被占了,那就按照“某種方式”繼續找下一個沒有被占的桶,直到找到第一個的。
 空的
空的
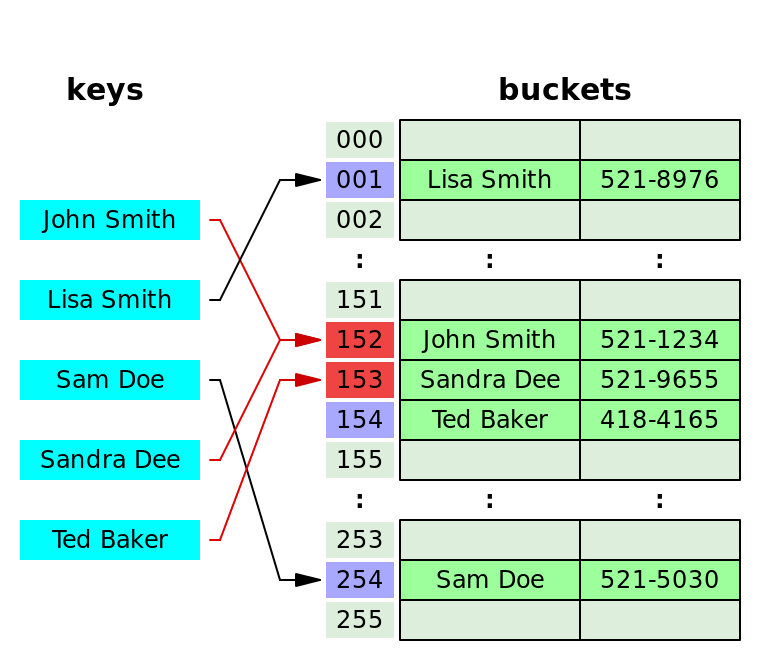
如圖所示,John Smith 和 Sandra Dee 發生了哈希沖突,都被計算到 152 號桶,于是 Sandra 就去了下一個空位 - 153 號桶,當然也會對之后的 key 發生影響:Ted Baker 計算結果本應是放在 153 號的,但鑒于已經被 Sandra 占了,就只能再去下一個空位了,所以到了 154 號。
這種方式叫做 Linear probing 線性探查,就像上圖所示,一個個的順著找下一個空位。當然還有其他的方式,比如去找平方數,或者 Double hashing.
每種數據結構的基本操作都無外乎<span >增刪改查</span>這四種,具體到 HashMap 來說,
增:put(K key, V value)
刪:remove(Object key)
改:還是用的 put(K key, V value)
查:get(Object key) / containsKey(Object key)
細心的同學可能發現了,為什么有些 key 的類型是 Object,有些是 K 呢?這還不是因為 equals()...
這是因為,在 get/remove 的時候,不一定是用的同一個 object。
還記得那個 str1 和 str2 都是田小齊的例子嗎?那比如我先 put(str1, value),然后用 get(str2) 的時候,也是想要到 tianxiaoqi 對應的 value 呀!不能因為我換了身衣服就不認得我了呀!所以在 get/remove 的時候并沒有很限制 key 的類型,方便另一個自己相認。
其實這些 API 的操作流程大同小異,我們以最復雜的 put(K key, V value) 來講:
首先要拿到 array 中要放的位置的 index
怎么找 index 呢,這里我們可以單獨用 getIndex() method 來做這件事;
具體怎么做,就是通過 hash function 算出來的值,模上數組的長度;
那拿到了這個位置的 Node,我們開始 traverse 這個 LinkedList,這就是在鏈表上的操作了,
如果找的到,就更新一下 value;
如果沒找到,就把它放在鏈表上,可以放頭上,也可以放尾上,一般我喜歡放頭上,因為新加入的元素用到的概率總是大一些,但并不影響時間復雜度。
代碼如下:
public V put(K key, V value) {
int index = getIndex(key);
Node<K, V> node = array[index];
Node<K, V> head = node;
while (node != null) {
// 原來有這個 key,僅更新值
if (checkEquals(key, node)) {
V preValue = node.value;
node.value = value;
return preValue;
}
node = node.next;
}
// 原來沒有這個 key,新加這個 node
Node<K, V> newNode = new Node(key, value);
newNode.next = head;
array[index] = newNode;
return null;
}這是一個年齡暴露貼,HashMap 與 Hashtable 的關系,就像 ArrayList 與 Vector,以及 StringBuilder 與 StringBuffer。
Hashtable 是早期 JDK 提供的接口,HashMap 是新版的; 它們之間最顯著的區別,就是 Hashtable 是線程安全的,HashMap 并非線程安全。
這是因為 Java 5.0 之后允許數據結構不考慮線程安全的問題,因為實際工作中我們發現沒有必要在數據結構的層面上上鎖,加鎖和放鎖在系統中是有開銷的,內部鎖有時候會成為程序的瓶頸。
所以 HashMap, ArrayList, StringBuilder 不再考慮線程安全的問題,性能提升了很多,當然,線程安全問題也就轉移給我們程序員了。
另外一個區別就是:HashMap 允許 key 中有 null 值,Hashtable 是不允許的。這樣的好處就是可以給一個默認值。
“HashMap面試會問的題目有哪些”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





