溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Flask中sqlalchemy模塊的詳細簡介分析的內容。小編覺得挺實用的,因此分享給大家做個參考。一起跟隨小編過來看看吧。
一、安裝
$ pip install flask-sqlalchemy
二、配置
配置選項列表 :

SQLALCHEMY_NATIVE_UNICODE | 可以用于顯式禁用原生 unicode 支持。當使用 不合適的指定無編碼的數據庫默認值時,這對于 一些數據庫適配器是必須的(比如 Ubuntu 上某些版本的 PostgreSQL )。|
| SQLALCHEMY_POOL_SIZE | 數據庫連接池的大小。默認是引擎默認值(通常 是 5 ) |
| SQLALCHEMY_POOL_TIMEOUT | 設定連接池的連接超時時間。默認是 10 。 |
| SQLALCHEMY_POOL_RECYCLE | 多少秒后自動回收連接。這對 MySQL 是必要的, 它默認移除閑置多于 8 小時的連接。注意如果 使用了 MySQL , Flask-SQLALchemy 自動設定這個值為 2 小時。|
app.config["SQLALCHEMY_DATABASE_URI"] = DATABASE_URI app.config["SQLALCHEMY_COMMIT_ON_TEARDOWN"] = True/False # 每次請求結束后都會自動提交數據庫中的變動. app.config[""] = app.config[""] = app.config[""] = app.config[""] = DATABASE_URI : mysql : mysql://username:password@hostname/database pgsql : postgresql://username:password@hostname/database sqlite(linux) : sqlite:////absolute/path/to/database sqlite(windows) : sqlite:///c:/absolute/path/to/database
三、初始化示例
from flask import Flask from flask_sqlalchemy import SQLAlchemy base_dir = os.path.abspath(os.path.dirname(__file__)) app = Flask(__name__) app.config["SQLALCHEMY_DATABASE_URI"] = 'sqlite:///' + os.path.join(base_dir, 'data.sqlite') app.config["SQLALCHEMY_COMMIT_ON_TEARDOWN"] = True db = SQLAlchemy(app)
四、定義模型
模型 表示程序使用的持久化實體. 在 ORM 中, 模型一般是一個 Python 類, 類中的屬性對應數據庫中的表.
Flaks-SQLAlchemy 創建的數據庫實例為模型提供了一個基類以及一些列輔助類和輔助函數, 可用于定義模型的結構.
db.Model # 創建模型, db.Column # 創建模型屬性.
模型屬性類型 :
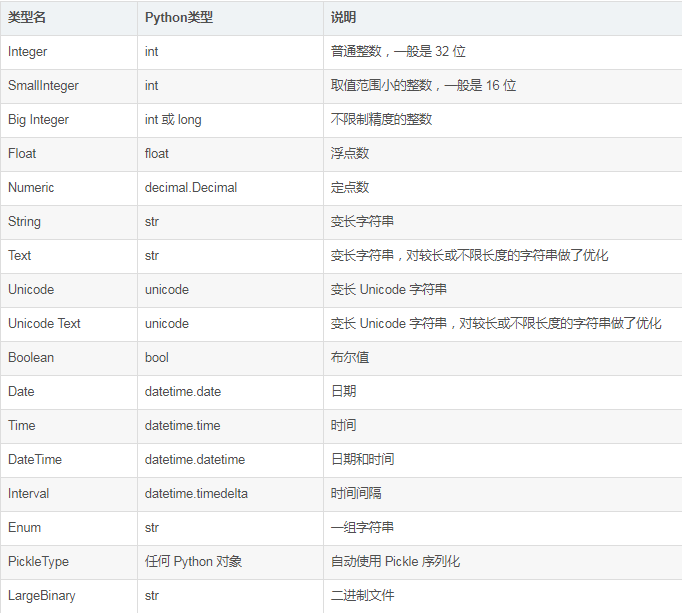
常用 SQLAlchemy 列選項
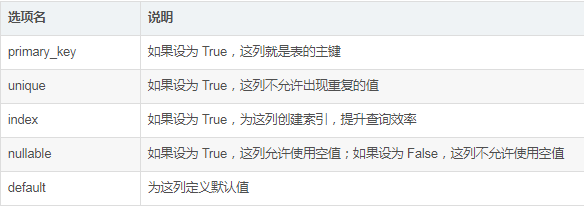
示例 :
class Role(db.Model): __tablename__ = "roles" id = db.Column(db.Integer, primary_key=True) name = db.Column(db.String(64), unique=True) def __repr__(self): """非必須, 用于在調試或測試時, 返回一個具有可讀性的字符串表示模型.""" return '<Role %r>' % self.name class User(db.Model): __tablename__ = 'users' id = db.Column(db.Integer, primary_key=True) username = db.Column(db.String(64), unique=True, index=True) def __repr__(self): """非必須, 用于在調試或測試時, 返回一個具有可讀性的字符串表示模型.""" return '<Role %r>' % self.username
五、關系
關系型數據庫使用關系把不同表中的行聯系起來。
常用 SQLAlchemy 關系選項:
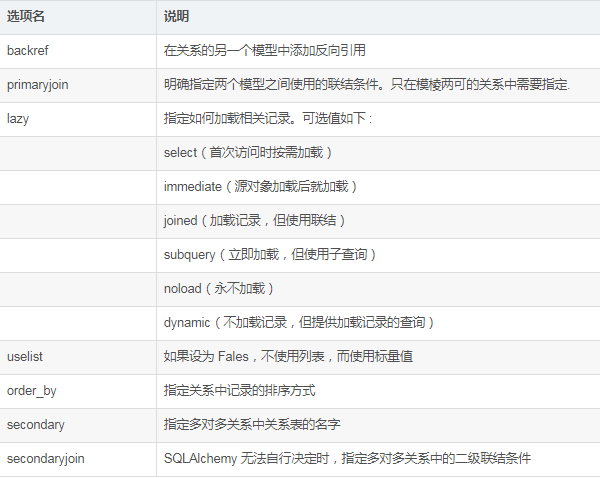
(1)一對多
原理 : 在 “多” 這一側加入一個外鍵, 指定 “一” 這一側聯結的記錄.
示例代碼 : 一個角色可屬于多個用戶, 而每個用戶只能有一個角色.
class Role(db.Model):
# ...
users = db.relationship('User', backref='role')
class User(db.Model):
# ...
role_id = db.Column(db.Integer, db.ForeignKey('roles.id')) # 外鍵關系.
###############
db.ForeignKey('roles.id') : 外鍵關系,
Role.users = db.relationship('User', backref='role') : 代表 外鍵關系的 面向對象視角. 對于一個 Role 類的實例,
其 users 屬性將返回與角色相關聯的用戶組成的列表.
db.relationship() 第一個參數表示這個關系的另一端是哪個模型.
backref 參數, 向 User 模型添加了一個 role 數據屬性, 從而定義反向關系. 這一屬性可替代 role_id 訪問 Role 模型,
此時獲取的是模型對象, 而不是外鍵的值.(2)多對多
最復雜的關系類型,需要用到第三章表,即關聯表,這樣多對多關系可以分解成原表和關聯表之間的兩個一對多關系。
查詢多對多關系分兩步 : 遍歷兩個關系來獲取查詢結果。
代碼示例:
registrations = db.Table("registrations",
db.Column("student_id", db.Integer, db.ForeignKey("students.id")),
db.Column("class_id", db.Integer, db.ForeignKey("classes.id"))
)
class Student(db.Model):
__tablename__ = "students"
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String)
classes = db.relationship("Class",
secondary=registrations,
backref=db.backref("students", lazy="dynamic"),
lazy="dynamic")
class Class(db.Model):
__tablename__ = "classes"
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String)多對多關系仍然使用定義一對多關系的 db.relationship() 方法進行定義, 但在多對多關系中, 必須把 secondary 參數設為關聯表。
多對多關系可以在任何一個類中定義, backref 參數會處理好關系的另一側。
關聯表就是一個簡單的表, 不是模型, SQLAlchemy 會自動接管這個表。
classes 關系使用列表語義, 這樣處理多對多關系比較簡單。
Class 模型的 students 關系有 參數 db.backref() 定義. 這個關系還指定了 lazy 參數, 所以, 關系兩側返回的查詢都可接受額外的過濾器。
自引用關系
自引用關系可以理解為多對多關系的特殊形式 : 多對多關系的兩邊由兩個實體變為一個實體。
高級多對多關系
使用多對多關系時,往往需要存儲所聯兩個實體之間的額外信息。這種信息只能存儲在關聯表中,對用戶之間的關注來說,可以存儲用戶關注另一個用戶的日期,這樣就能按照時間順序列出所有關注者。
為了能在關系中處理自定義的數據,必須提升關聯表的地位,使其變成程序可訪問的模型。
關注關聯表模型實現:
class Follow(db.Model):
__tablename__ = "follows"
follower_id = db.Column(db.Integer, db.ForeignKey("users.id"), primary_key=True)
followed_id = db.Column(db.Integer, db.ForeignKey("users.id"), primary_key=True)
timestamp = db.Column(db.DateTime, default=datetime.utcnow)
# SQLAlchemy 不能直接使用這個關聯表, 因為如果這個做程序就無法訪問其中的自定義字段. 相反的, 要把這個多對多關系的左右
兩側拆分成兩個基本的一對多關系, 而且要定義成標準的關系。使用兩個一對多關系實現的多對多關系:
class User(UserMixin, db.Model):
# ...
followd = db.relationship("Follow",
foreign_keys=[Follow.follower_id],
backref=db.backref("follower", lazy="joined"),
lazy="dynamic",
cascade="all, delete-orphan")
followrs = db.relationship("Follow",
foreign_keys=[Follow.followed_id],
backref=db.backref("followed", lazy="joined"),
lazy="dynamic",
cascade="all, delete-orphan")
# 這段代碼中, followed 和 follower 關系都定義為 單獨的 一對多關系.
# 注意: 為了消除外鍵歧義, 定義關系是必須使用可選參數 foreign_keys 指定的外鍵. 而且 db.backref() 參數并不是指定這兩個
關系之間的引用關系, 而是回引 Follow 模型. 回引中的 lazy="joined" , 該模式可以實現立即從連接查詢中加載相關對象.
# 這兩個關系中, user 一側設定的 lazy 參數作用不一樣. lazy 參數都在 "一" 這一側設定, 返回的結果是 "多" 這一側中的記錄.
dynamic 參數, 返回的是查詢對象.
# cascade 參數配置在父對象上執行的操作相關對象的影響. 比如, 層疊對象可設定為: 將用戶添加到數據庫會話后, 要自定把所有
關系的對象都添加到會話中. 刪除對象時, 默認的層疊行為是把對象聯結的所有相關對象的外鍵設為空值. 但在關聯表中, 刪除記錄
后正確的行為是把執行該記錄的實體也刪除, 因為這樣才能有效銷毀聯結. 這就是 層疊選項值 delete-orphan 的作用. 設為 all,
delete-orphan 的意思是啟動所有默認層疊選項, 并且還要刪除孤兒記錄。(3)一對一
可以看做特殊的 一對多 關系. 但調用 db.relationship() 時 要把 uselist 設置 False, 把 多變為 一。
(4)多對一
將一對多關系,反過來即可,也是一對多關系。
六、數據庫操作
(1)創建數據庫及數據表
創建數據庫
db.create_all()
示例 :
$ python myflask.py shell > from myflask import db > db.create_all()
如果使用 sqlite , 會在 SQLALCHEMY_DATABASE_URI 指定的目錄下 多一個文件,文件名為該配置中的文件名。
如果數據庫表已經存在于數據庫中, 那么 db.create_all() 不會創建或更新這個表。
更新數據庫
方法一 :
先刪除, 在創建 –> 原有數據庫中的數據, 都會消失.
> db.drop_all() > db.create_all()
方法二 :
數據庫遷移框架 : 可以跟自動數據庫模式的變化,然后增量式的把變化應用到數據庫中。
SQLAlchemy 的主力開發人員編寫了一個 遷移框架 Alembic, 除了直接使用 Alembic wait, Flask 程序還可使用 Flask-Migrate 擴展, 該擴展對 Alembic 做了輕量級包裝, 并集成到 Flask-Script 中, 所有操作都通過 Flaks-Script 命令完成。
① 安裝 Flask-Migrate
$ pip install flask-migrate
② 配置
from flask_migrate import Migrate, MigrateCommand
# ...
migrate = Migrate(app, db)
manager.add_command('db', MigrateCommand)③ 數據庫遷移
a. 使用 init 自命令創建遷移倉庫.
$ python myflask.py db init # 該命令會創建 migrations 文件夾, 所有遷移腳本都存在其中.
b. 創建數據路遷移腳本. $ python myflask.py db revision # 手動創建 Alemic 遷移 創建的遷移只是一個骨架, upgrade() 和 downgrade() 函數都是空的. 開發者需要使用 Alembic 提供的 Operations 對象 指令實現具體操作. $ python myflask.py db migrate -m COMMONT # 自動創建遷移. 自動創建的遷移會根據模型定義和數據庫當前的狀態之間的差異生成 upgrade() 和 downgrade() 函數的內容. ** 自動創建的遷移不一定總是正確的, 有可能漏掉一些細節, 自動生成遷移腳本后一定要進行檢查. c. 更新數據庫 $ python myflask.py db upgrade # 將遷移應用到數據庫中.
(2)插入行
模型的構造函數,接收的參數是使用關鍵字參數指定的模型屬性初始值。注意,role 屬性也可使用,雖然他不是真正的數據庫列,但卻是一對多關系的高級表示。這些新建對象的 id 屬性并沒有明確設定,因為主鍵是由 Flask-SQLAlchemy 管理的。現在這些對象只存在于 Python 解釋器中,尚未寫入數據庫。
>> from myflask import db, User, Role >> db.create_all() >> admin_role = Role(name="Admin") >> mod_role = Role(name="Moderator") >> user_role = Role(name="User") >> user_john = User(username="john", role=admin_role) >> user_susan = User(username="susan", role=mod_role) >> user_david = User(username="david", role=user_role) >> admin_role.name 'Admin' >> admin_role.id None --------- >> db.session.add_all([admin_role, mod_role, user_role, user_john, user_susan, user_david]) # 把對象添加到會話中. >> db.session.commit() # 把對象寫入數據庫, 使用 commit() 提交會話.
(3)修改行
>> admin_role = "Administrator" >> db.session.add(admin_role) >> db.session.commit()
(4)刪除行
>> db.session.delete(mod_role) >> db.session.commit()
(5)查詢行
Flask-SQLAlchemy 為每個模型類都提供了 query 對象.
獲取表中的所有記錄
>> Role.query.all() [<Role u'Admin'>, <Role u'Moderator'>, <Role u'User'>] >> User.query.all() [<Role u'john'>, <Role u'susan'>, <Role u'david'>]
查詢過濾器
filter_by() 等過濾器在 query 對象上調用, 返回一個更精確的 query 對象. 多個過濾器可以一起調用, 直到獲取到所需的結果.
>> User.query.filter_by(role=user_role).all() # 以列表形式,返回所有結果, >> User.query.filter_by(role=user_role).first() # 返回結果中的第一個.
filter() 對查詢結果過濾,比”filter_by()”方法更強大,參數是布爾表達式
# WHERE age<20
users = User.query.filter(User.age<20)
# WHERE name LIKE 'J%' AND age<20
users = User.query.filter(User.name.startswith('J'), User.age<20)查詢過濾器 :

查詢執行函數 :
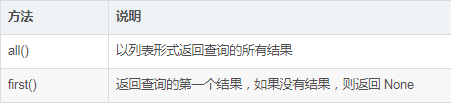
first_or_404() | 返回查詢的第一個結果,如果沒有結果,則終止請求,返回 404 錯誤響應 | |
| get() | 返回指定主鍵對應的行,如果沒有對應的行,則返回 None |
get_or_404() | 返回指定主鍵對應的行,如果沒找到指定的主鍵,則終止請求,返回 404 | |錯誤響應
| count() | 返回查詢結果的數量 |
| paginate() | 返回一個 Paginate 對象,它包含指定范圍內的結果 |
(6)會話管理,事務管理
單個提交
>> db.session.add(ONE) >> db.session.commit()
多個提交
>> db.session.add_all([LIST_OF_MEMBER]) >> db.session.commit()
刪除會話
>> db.session.delete(mod_role) >> db.session.commit()
事務回滾 : 添加到數據庫會話中的所有對象都會還原到他們在數據庫時的狀態.
>> db.session.rollback()
七、視圖函數中操作數據庫
@app.route('/', methods=['GET', 'POST'])
def index():
form = NameForm()
if form.validate_on_submit():
user = User.query.filter_by(username=form.name.data).first()
if user is None:
user = User(username=form.name.data)
db.session.add(user)
session["known"] = False
else:
session["known"] = True
session["name"] = form.name.data
form.name.data = "" # why empty it ?
return redirect(url_for("index"))
return render_template("index.html", current_time=datetime.utcnow(), form=form, name=session.get("name"),
known=session.get("known"))八、分頁對象 Pagination
1. paginate() 方法
paginate() 方法的返回值是一個 Pagination 類對象,該類在 Flask-SQLAlchemy 中定義,用于在模板中生成分頁鏈接。
paginate(頁數[,per_page=20, error_out=True]) 頁數 : 唯一必須指定的參數, per_page : 指定每頁現實的記錄數量, 默認 20. error_out : True 如果請求的頁數超出了返回, 返回 404 錯誤; False 頁數超出范圍時返回一個,空列表.
示例代碼:
@main.route("/", methods=["GET", "POST"])
def index():
# ...
page = request.args.get('page', 1, type=int) # 渲染的頁數, 默認第一頁, type=int 保證參數無法轉換成整數時,
返回默認值.
pagination = Post.query.order_by(Post.timestamp.desc()).paginate(page, per_page=current_app.config
["FLASKY_POSTS_PER_PAGE"], error_out=False)
posts = pagination.items
return render_template('index.html', form=form, posts=posts,pagination=pagination)2. 分頁對象的屬性及方法:
Flask_SQLAlchemy 分頁對象的屬性:

在分頁對象可調用的方法:
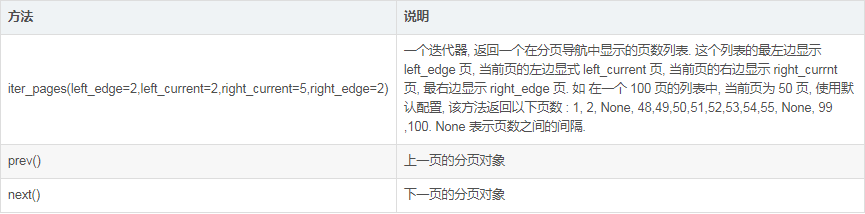
3. 在模板中與 BootStrap 結合使用示例
使用 Flaks-SQLAlchemy 的分頁對象與 Bootstrap 中的分頁 CSS, 可以輕松的構造出一個 分頁導航.
分頁模板宏 _macros.html : 創建一個 Bootstrap 分頁元素, 即一個有特殊樣式的無序列表.
{% macro pagination_widget(pagination,endpoint) %}
<ul class="pagination">
<li {% if not pagination.has_prev %} class="disabled" {% endif %}>
<a href="{% if pagination.has_prev %}{{url_for(endpoint, page=paginatin.page - 1, **kwargs)}}{% else %}
#{% endif %}">
«
</a>
</li>
{% for p in pagination,.iter_pages() %}
{% if p %}
{% if p == pagination.page %}
<li class="active">
<a href="{{ url_for(endpoint, page=p, **kwargs) }}">{{p}}</a>
</li>
{% else %}
<li>
<a href="{{ url_for(endpoint, page = p, **kwargs) }}">{{p}}</a>
</li>
{% endif %}
{% else %}
<li class="disabled"><a href="#">…</a> </li>
{% endif %}
{% endfor %}
<li {% if not pagination.has_next %} class="disabled" {% endif%}>
<a href="{% if paginatin.has_next %}{{ url_for(endpoint, page=pagination.page+1, **kwargs) }}{% else %}
#{% endif %}">
»
</a>
</li>
</ul>
{% endmacro %}導入使用分頁導航
{% extends "base.html" %}
{% import "_macros.html" as macros %}
...
<div class="pagination">
{{ macro.pagination_widget(pagination, ".index")}}
</div>九、監聽事件
1. set 事件
示例代碼 :
from markdown import markdown import bleach class Post(db.Model): # ... body = db.Colume(db.Text) body_html = db.Column(db.Text) # ... @staticmethod def on_changeed_body(target, value, oldvalue, initiator): allowed_tags = ["a", "abbr", "acronym", "b", "blockquote", "code", "em", "i", "li", "ol", "pre", "strong", "ul", "h2", "h3","h4","h5","p"] target.body_html = bleach.linkify(bleach.clean(markdown(value, output_format="html"), tags=allowed_tags, strip=True)) db.event.listen(Post.body, "set", Post.on_changeed_body) # on_changed_body 函數注冊在 body 字段上, 是 SQLIAlchemy "set" 事件的監聽程序, # 這意味著只要這個類實例的 body 字段設了新值, 函數就會自動被調用. # on_changed_body 函數把 body 字段中的文本渲染成 HTML 格式, # 結果保存在 body_html 中, 自動高效的完成 Markdown 文本到 HTML 的轉換
十、記錄慢查詢
十一、Binds 操作多個數據庫
十二、其他
1. ORM 在查詢時做初始化操作
當 SQLIAlchemy ORM 從數據庫查詢數據時, 默認不調用__init__ 方法, 其底層實現了 Python 類的 __new__() 方法, 直接實現 對象實例化, 而不是通過 __init__ 來實例化對象.
如果需要在查詢時, 依舊希望實現一些初始化操作, 可以使用 orm.reconstructor() 裝飾器或 實現 InstanceEvents.load() 監聽事件。
# orm.reconstructor from sqlalchemy import orm class MyMappedClass(object): def __init__(self, data): self.data = data # we need stuff on all instances, but not in the database. self.stuff = [] @orm.reconstructor def init_on_load(self): self.stuff = [] # InstanceEvents.load() from sqlalchemy import event ## standard decorator style @event.listens_for(SomeClass, 'load') def receive_load(target, context): "listen for the 'load' event" # ... (event handling logic) ...
如果只是希望在從數據庫查詢生成的對象中包含某些屬性, 也可以使用 property 實現:
class AwsRegions(db.Model):
name=db.Column(db.String(64))
...
@property
def zabbix_api(self):
return ZabbixObj(zabbix_url)
@zabbix_api.setter
def zabbix_api(self):
raise ValueError("zabbix can not be setted!")感謝各位的閱讀!關于Flask中sqlalchemy模塊的詳細簡介分析就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





