溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python中隨機User-Agent和ip代理池是什么,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
1. 前言
比如隨著我們爬蟲的速度越來越快,很多時候,有人發現,數據爬不了啦,打印出來一看。
不返回數據,而且還甩一句話

是不是很熟悉啊?
要想想看,人是怎么訪問網站的? 發請求,對,那么就會帶有request.headers,
那么當你瘋狂請求別人的網站時候,人家網站的管理人員就會 覺得有點不對勁了,
他看看請求的 header 信息,一看嚇一跳,結果看到的 headers 信息是這樣的:
Host: 127.0.0.1:3369 User-Agent: python-requests/3.21.0 Accept-Encoding: gzip, deflate Accept: */* Connection: keep-alive
看到:
User-Agent: python-requests/3.21.0
居然使用 python 的庫來請求,說明你已經暴露了,人家不封你才怪呢?
那么怎么辦呢?偽裝自己唄。
python 不可以偽裝,瀏覽器可以偽裝,所以可以修改瀏覽器的請求頭。
簡單來說,就是讓自己的 python 爬蟲假裝是瀏覽器。
2. 偽裝 Header的哪個地方?
要讓自己的 python 爬蟲假裝是瀏覽器,我們要偽裝headers,那么headers里面有很多字段,我們主要注意那幾個呢?
headers數據通常用這兩個即可,強烈推薦在爬蟲中為每個request都配個user-agent,而’Referer’如果需要就加,不需要就不用。(Referer是什么?后面補充知識點)
圖示:
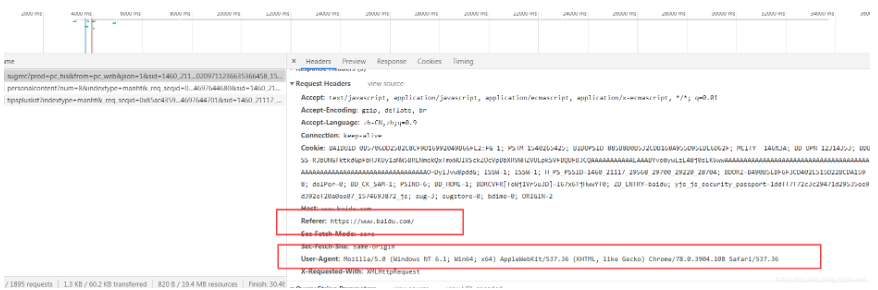
上面幾個重要點解釋如下:
Requests Headers:
? “吾是人!”——修改user-agent:里面儲存的是系統和瀏覽器的型號版本,通過修改它來假裝自己是人。
? “我從臺灣省來”——修改referer:告訴服務器你是通過哪個網址點進來的而不是憑空出現的,有些網站會檢查。
? “餅干!”:——帶上cookie,有時帶不帶餅干得到的結果是不同的,試著帶餅干去“賄賂”服務器讓她給你完整的信息。
3.headers的偽裝—隨機User-Agent
爬蟲機制:很多網站都會對Headers的User-Agent進行檢測,還有一部分網站會對Referer進行檢測(一些資源網站的防盜鏈就是檢測Referer)
隨機User-Agent生成 :生成一個隨機的User-Agent,這樣你就可以是很多不同的瀏覽器模樣。
(代碼現成的,復制拿去用即可)
#!/usr/bin/python3
#@Readme : 反爬之headers的偽裝
# 對于檢測Headers的反爬蟲
from fake_useragent import UserAgent # 下載:pip install fake-useragent
ua = UserAgent() # 實例化,需要聯網但是網站不太穩定-可能耗時會長一些
# 1.生成指定瀏覽器的請求頭
print(ua.ie)
print(ua.opera)
print(ua.chrome)
print(ua.google)
print(ua.firefox)
print(ua.safari)
# 隨機打印一個瀏覽器的User-Agent
print(ua.random)
print('完畢。')
# 2.在工作中常用的則是ua.random方式
import requests
ua = UserAgent()
print(ua.random) # 隨機產生
headers = {
'User-Agent': ua.random # 偽裝
}
# 請求
url = 'https://www.baidu.com/'
response = requests.get(url, headers=headers)
print(response.status_code)Referer的偽裝:
如果想爬圖片,圖片反盜鏈的話就要用到Referer了。
headers = {'User-Agent':ua.random,'Referer':'這里放入圖片的主頁面'}如果遇到防盜鏈的圖片,一般思路就是先爬到所有圖片的地址.jpg —–>將它們儲存在列表中 —–>遍歷訪問圖片地址,然后用 ‘wb’的格式打開文件寫入,文件名根據圖片地址動態改變。
這個基本上如果你的爬蟲對象不是很嚴肅的圖片網站,都不會用到。
4.ip要被封禁?ip代理的使用
有的時候,僅僅偽裝headers,使用隨機 User-Agent來請求也會被發現,同一個ip地址,訪問的次數太多,ip會被屏蔽,就用其他的ip繼續去訪問。
4.1 requests 的代理訪問
首先,在python中使用requests 庫來代理訪問為例。
使用代理 ip 來訪問網站如下:
首先要自己定義代理IP代理:
proxie = {
'http' : 'http://xx.xxx.xxx.xxx:xxxx',
'http' : 'http://xxx.xx.xx.xxx:xxx',
....
}然后使用requests+代理來請求網頁:
response = requests.get(url,proxies=proxies)
這樣就可以使用你定義的代理地址去訪問網站了。
但是,ip地址,是唯一的,從哪里去搞一堆ip地址來使用呢?
在網上有很多免費的代理,代理IP很不穩定。如果你有錢的話,直接去買就行了。
4.2 不花錢?那就是IP代理池
如果你又不想花錢,又想用ip爬蟲。那就只能整個ip代理池了。
4.2.1 自建的ip代理池—多線程爬蟲
就是自己去收集網上公開的免費ip,自建起 自己的ip代理池。
就是通過 python 程序去抓取網上大量免費的代理 ip , 然后定時的去檢測這些 ip 可不可以用,那么下次你要使用代理 ip 的時候,你只需要去自己的 ip 代理池里面拿就行了。
簡單來說:訪問免費代理的網站 —> 正則/xpath提取 ip和端口—> 測試ip是否可用 》》可用則保存 》》使用ip爬蟲 > 過期,拋棄ip。
這個過程可以使用多線程或異步的方式,因為檢測代理是個很慢的過程。
這是來源于網絡的一個西刺代理的多線程ip代理爬蟲:(我不用)
來自于:https://www.jianshu.com/p/2daa34a435df
#!/usr/bin/python3
#@Readme : IP代理==模擬一個ip地址去訪問某個網站(爬的次數太多,ip被屏蔽)
# 多線程的方式構造ip代理池。
from bs4 import BeautifulSoup
import requests
from urllib import request, error
import threading
import os
from fake_useragent import UserAgent
inFile = open('proxy.txt') # 存放爬蟲下來的ip
verifiedtxt = open('verified.txt') # 存放已證實的可用的ip
lock = threading.Lock()
def getProxy(url):
# 打開我們創建的txt文件
proxyFile = open('proxy.txt', 'a')
# 偽裝
ua = UserAgent()
headers = {
'User-Agent': ua.random
}
# page是我們需要獲取多少頁的ip,這里我們獲取到第9頁
for page in range(1, 10):
# 通過觀察URL,我們發現原網址+頁碼就是我們需要的網址了,這里的page需要轉換成str類型
urls = url + str(page)
# 通過requests來獲取網頁源碼
rsp = requests.get(urls, headers=headers)
html = rsp.text
# 通過BeautifulSoup,來解析html頁面
soup = BeautifulSoup(html,'html.parser')
# 通過分析我們發現數據在 id為ip_list的table標簽中的tr標簽中
trs = soup.find('table', id='ip_list').find_all('tr') # 這里獲得的是一個list列表
# 我們循環這個列表
for item in trs[1:]:
# 并至少出每個tr中的所有td標簽
tds = item.find_all('td')
# 我們會發現有些img標簽里面是空的,所以這里我們需要加一個判斷
if tds[0].find('img') is None:
nation = '未知'
locate = '未知'
else:
nation = tds[0].find('img')['alt'].strip()
locate = tds[3].text.strip()
# 通過td列表里面的數據,我們分別把它們提取出來
ip = tds[1].text.strip()
port = tds[2].text.strip()
anony = tds[4].text.strip()
protocol = tds[5].text.strip()
speed = tds[6].find('div')['title'].strip()
time = tds[8].text.strip()
# 將獲取到的數據按照規定格式寫入txt文本中,這樣方便我們獲取
proxyFile.write('%s|%s|%s|%s|%s|%s|%s|%s\n' % (nation, ip, port, locate, anony,
protocol, speed,
time))
def verifyProxyList():
verifiedFile = open('verified.txt', 'a')
while True:
lock.acquire()
ll = inFile.readline().strip()
lock.release()
if len(ll) == 0: break
line = ll.strip().split('|')
ip = line[1]
port = line[2]
realip = ip + ':' + port
code = verifyProxy(realip)
if code == 200:
lock.acquire()
print("---Success成功:" + ip + ":" + port)
verifiedFile.write(ll + "\n")
lock.release()
else:
print("---Failure失敗:" + ip + ":" + port)
def verifyProxy(ip):
'''
驗證代理的有效性
'''
ua = UserAgent()
requestHeader = {
'User-Agent': ua.random
}
url = "http://www.baidu.com"
# 填寫代理地址
proxy = {'http': ip}
# 創建proxyHandler
proxy_handler = request.ProxyHandler(proxy)
# 創建opener
proxy_opener = request.build_opener(proxy_handler)
# 安裝opener
request.install_opener(proxy_opener)
try:
req = request.Request(url, headers=requestHeader)
rsq = request.urlopen(req, timeout=5.0)
code = rsq.getcode()
return code
except error.URLError as e:
return e
if __name__ == '__main__':
# 手動新建兩個文件
filename = 'proxy.txt'
filename2 = 'verified.txt'
if not os.path.isfile(filename):
inFile = open(filename, mode="w", encoding="utf-8")
if not os.path.isfile(filename2):
verifiedtxt = open(filename2, mode="w", encoding="utf-8")
tmp = open('proxy.txt', 'w')
tmp.write("")
tmp.close()
tmp1 = open('verified.txt', 'w')
tmp1.write("")
tmp1.close()
# 多線程爬蟲西刺代理網,找可用ip
getProxy("http://www.xicidaili.com/nn/")
getProxy("http://www.xicidaili.com/nt/")
getProxy("http://www.xicidaili.com/wn/")
getProxy("http://www.xicidaili.com/wt/")
all_thread = []
for i in range(30):
t = threading.Thread(target=verifyProxyList)
all_thread.append(t)
t.start()
for t in all_thread:
t.join()
inFile.close()
verifiedtxt.close()(代碼可以使用,貼出來是為了讓大家參考,以后可以修改為自己的。)
運行一下,效果:

爬出來的可用的很少或者很短:
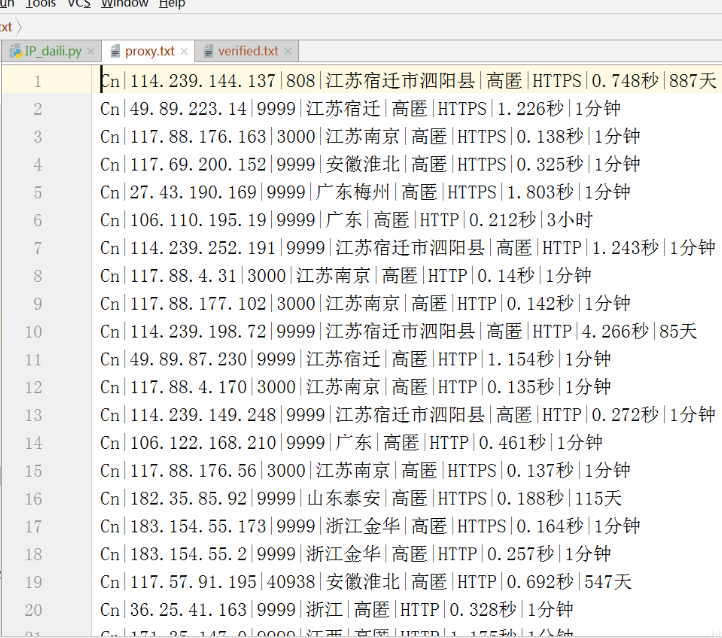
所以這種方式,不推薦。
4.2.2 開源庫的ip代理池—異步async-proxy-pool
開源庫 async-proxy-pool 是異步爬蟲代理池,以 Python asyncio 為基礎,旨在充分利用 Python 的異步性能。
異步處理比同步處理能提升成百上千倍的效率。
下載和使用教程:async-proxy-pool
運行環境
項目使用了 sanic,一個異步網絡框架。所以建議運行 Python 環境為 Python3.5+,并且sanic 不支持 Windows 系統,Windows 用戶(比如我 smile)可以考慮使用 Ubuntu on Windows。
這我就不開心了,這玩意兒不支持Windows 系統,如果你不是win的。那你可以繼續照著他的官網搞。(相信大多數人還是windows,我就不講了。)
4.2.3 開源 ip代理池—ProxyPool(吐血推薦)
類比線程池,進程池,懂了吧?
這是俺發現的一個不錯的開源 ip 代理池ProxyPool,可以用windows系統的,至少Python3.5以上環境喲,還需要將Redis服務開啟。
現成的代理池,還不用起來?
ProxyPool下載地址:https://github.com/Python3WebSpider/ProxyPool.git
(可以手動下載也可以使用git下來。)
1.ProxyPool的使用:
首先使用 git clone 將源代碼拉到你本地,
git clone https://github.com/Python3WebSpider/ProxyPool.git
2.接著打開項目中的 setting.py,在這里可以配置相關信息,比如 Redis 的地址密碼相關。
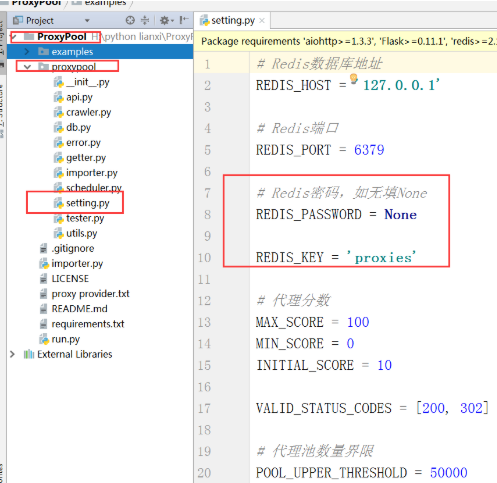
3.進入proxypool目錄,修改settings.py文件,PASSWORD為Redis密碼,如果為空,則設置為None。(新裝的redis一般沒有密碼。)
(如果你沒 redis 的話,可以先去下載了安裝了再來看吧。)
(假設你的redis已經安裝完成。)
4.接著在你 clone 下來的文件目錄中(就是這個ProxyPool存的電腦路徑 )
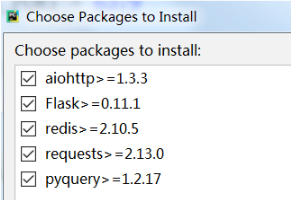
5.安裝相關所需的 依賴包:
(pip或pip3)
pip install -r requirements.txt
(如果你把ProxyPool導入在pycharm里面,那就一切都在pycharm里面搞就可以了。)
需要下載的都是:
6.接下來開啟你的 redis服務,
直接cmd 打開dos窗口,運行:redis-server.exe
即可開啟redis服務器。redis 的默認端口就是 6379
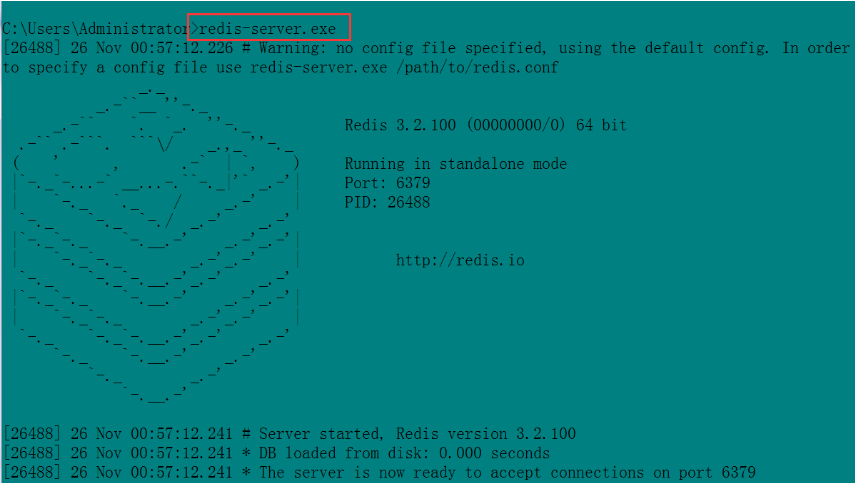
7.接著就可以運行 run.py 了。
可以在cmd里面命令方式運行,也可以導入pycharm里面運行。
圖示:
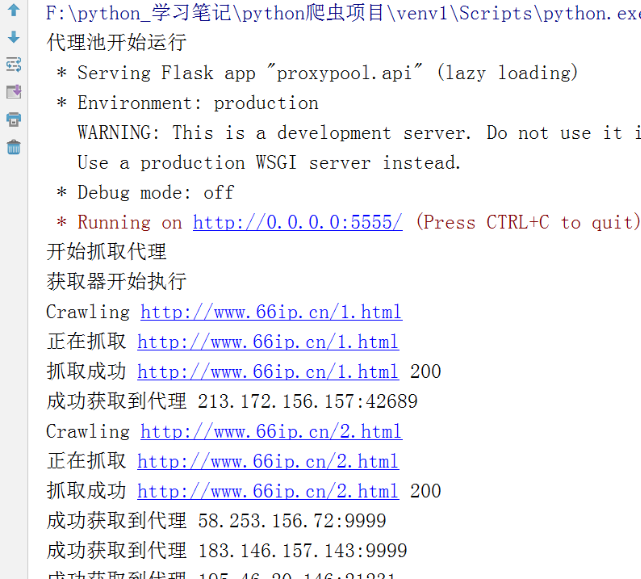
8.運行 run.py 以后,你可以打開你的redis管理工具,或者進入redis里面查看,這時候在你的 redis 中就會存入很多已經爬取到的代理 ip 了:
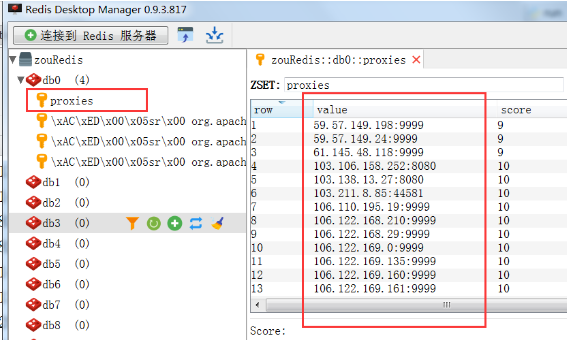
9.項目跑起來之后,【不要停止】,此時redis里面存了ip,就可以訪問這個代理池了。
在上面的圖中,可以看到有這么一句話
Running on http://0.0.0.0:5555/ (Press CTRL+C to quit)
這就是告訴我們隨機訪問地址URL是多少。
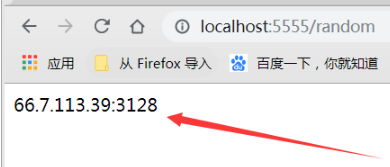
10.在瀏覽器中隨機獲取一個代理 ip 地址:
你就瀏覽器輸入:
http://0.0.0.0:5555/random
這樣訪問之后就會獲取到一個隨機的代理 ip。
圖示:
11.在代碼中隨機獲取一個ip代理
就這樣:
import requests # 隨機ip代理獲取 PROXY_POOL_URL = 'http://localhost:5555/random' def get_proxy(): try: response = requests.get(PROXY_POOL_URL) if response.status_code == 200: return response.text except ConnectionError: return None if __name__ == '__main__': print(get_proxy())
圖示:
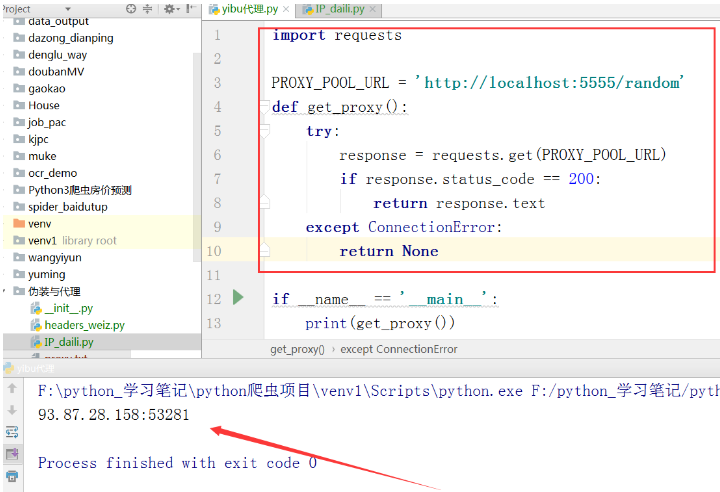
好了,到此結束了。
使用這個 ip代理池,目前來說是最好的了,又免費又高效唉~~~
5.報錯解決
安裝的時候,如果報錯類似于如下:
AttributeError: ‘int’ object has no attribute 'items
更新一下 對應的xxx軟件版本,比如redis 版本:
pip install redis==3.33.1
好了,到這里,我們成功的在代理池中獲取代理 ip 了,再也不用怕被封ip了,因為我們有很多ip可以用了。
關于Python中隨機User-Agent和ip代理池是什么就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





