溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python中numpy優勢是什么,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
1.Numpy的優勢
Python已經提供了很多豐富的內置包,我們為什么還要學習NumPy呢?先看一個例子,找尋學習 NumPy 的必要性和重要性。如下:
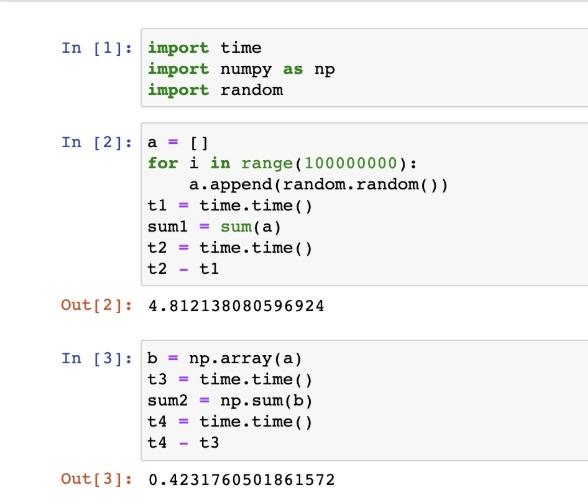
完成同樣的都對元素相加的操作,NumPy比Python快了11倍之多。這就是我們要學好NumPy的一個重要理由,它在處理更大數據量時,處理效率明顯快于Python。并且內置的向量化運算和廣播機制,使得使用NumPy更加簡潔,會少寫很多嵌套的for循環,因此代碼的可讀性大大增強。NumPy計算為什么這么快呢?原因如下:
1)Python 的 list是一個通用結構。它能包括任意類型的對象,并且是動態類型。
2)NumPy 的 ndarray 是 靜態、同質 的類型,當ndarray對象被創建時,元素的類型就確定。由于是靜態類型,所以ndarray間的加、減、乘、除用 C 和 Fortran 實現才成為可能,所以運行起來就會更快。根據官方介紹,底層代碼用 C語言 和 Fortran 語言實現,實現性能無限接近 C 的處理效率。
3)支持并行化運算,也叫向量化運算。當然向量是數學當中的概念,我們不過多解釋,只需要知道他的優勢即可。也就是說 NumPy 底層使用 BLAS 做向量,矩陣運算。
numpy的許多函數不僅是用C實現了,還使用了BLAS(一般Windows下link到MKL的,下link到OpenBLAS)
基本上那些BLAS實現在每種操作上都進行了高度優化
例如使用AVX向量指令集,甚至能比你自己用C實現快上許多,更不要說和用Python實現的比
由此可見,NumPy 就非常適合做大規模的數值計算和數據分析。
2. 數組屬性
數組屬性反映了數組本身固有的信息。
屬性名字 屬性解釋
ndarray.shape 數組維度的元組
ndarray.flags 有關陣列內存布局的信息
ndarray.ndim 數組維數
ndarray.size 數組中的元素數量
ndarray.itemsize 一個數組元素的長度(字節)
ndarray.nbytes 數組元素消耗的總字節數
示例代碼如下:
import numpy as np # 數組的屬性 # 1.創建數組 這里先不用管 后續會詳細講解數組的創建方法 a = np.array([[1,2,3],[4,5,6]]) b = np.array([1,2,3,4]) c = np.array([[[1,2,3],[4,5,6]],[[1,2,3],[4,5,6]]]) # 創建數組的時候指定類型 # dtype更多取值: int complex bool object # 還可以顯示的定義數據位數的類型,如: int64、int16、float128、complex128。 d = np.array([1,2,3,4], dtype=np.float) # 2.測試數組屬性 print(a.shape) # 數組形狀 (2, 3): 二維數組 print(b.shape) # (4,) 一維數組: 有4個元素 print(c.shape) # (2, 2, 3): 三維數組 print(a.ndim) # 數組維數 2 print(a.size) # 元素的數量 6 print(a.itemsize) # 每一個元素占的位數(字節) 8 print(a.nbytes) # 總共占的字節數 6*8 ==> 48 print(a.flags) # 陣列內存布局 print(a.dtype) # 數組類型 int64 print(d.dtype) # float64
上述代碼執行結果如下:

3. 創建數組
1) 創建0和1的數組 示例代碼如下:

2)從現有的數據中創建 示例代碼如下:
num_list = [[1,2,3], [4,5,6]] a = np.array(num_list) a1 = np.array(a) # 創建了一個新的數組 a2 = np.asarray(a) # 還是引用原來的數組 print(a) print(a1) print(a2) a[0] = 10 a, a1, a2
上述代碼執行結果如下:

3)創建固定范圍的數組,語法格式如下:
np.linspace(start, stop, num, endpoint, retstep, dtype) 生成等間隔的序列
start:序列的起始值
stop:序列的終止值
num:要生成的等間隔樣例數量,默認為50
endpoint:序列中是否包含stop值,默認為True
retstep:如果為True,返回樣例,以及連續數字之間的步長
dtype:輸出ndarray的數據類型
示例代碼如下:
arr = np.linspace(0, 10, 10) arr
執行結果如圖所示:

其它的還有:
1)numpy.arange(start,stop, step, dtype)
示例代碼如下:
np.arange(1, 10, 2)
運行結果如圖所示:

2)numpy.logspace(start,stop, num, endpoint, base, dtype) 構造一個從10的-2次方 到 10的2次方 的等比數列,這個等比數列的長度是 10 個元素,示例代碼如下:
np.logspace(-2,2,10)
運行結果如圖所示:

如果不想是10的次方,也就是想改變基數,那么可以這么寫,代碼如下:
np.logspace(-2,2,10,base=2)
運行結果如圖所示:

4. 創建隨機數組
np.random 模塊生成隨機數組,更加方便,示例代碼如下:
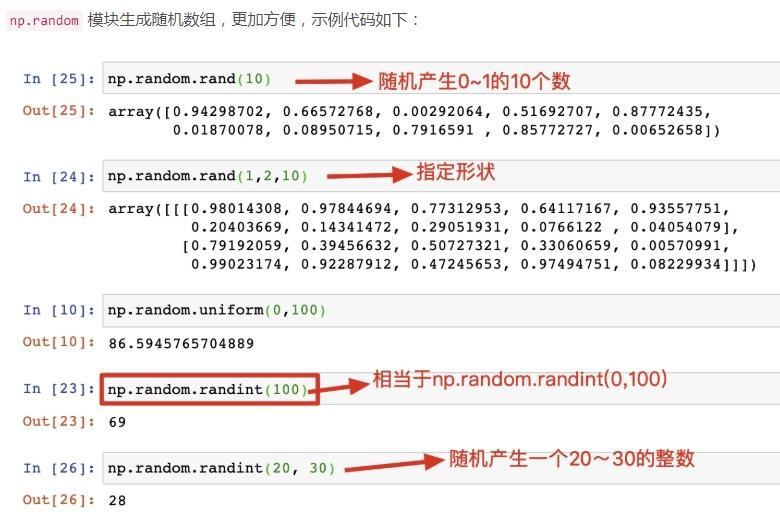
上面產生的數據是屬于一個均勻分布。那么什么是均勻分布呢?在概率論和統計學中,均勻分布也叫矩形分布,它是對稱概率分布,在相同長度間隔的分布概率是等可能的。 均勻分布由兩個參數a和b定義,它們是數軸上的最小值和最大值,通常縮寫為U(a,b)。
正態分布?給定均值/標準差/維度的正態分布,示例代碼如下:
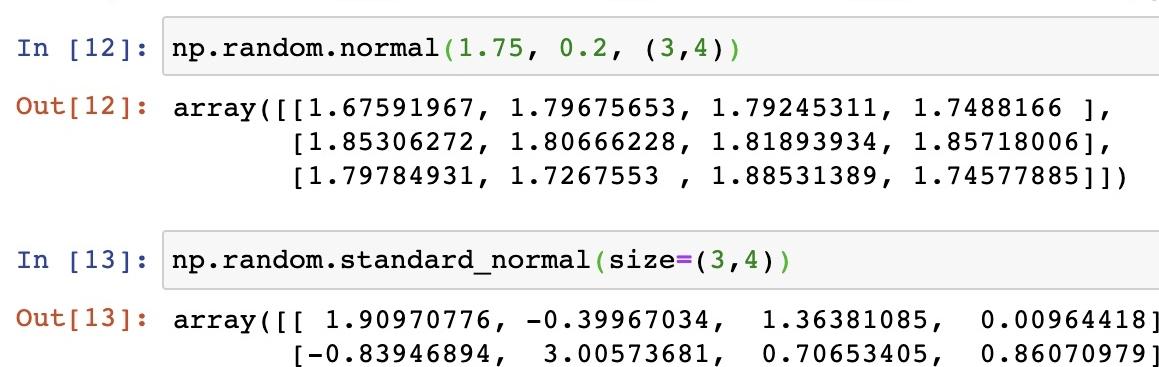
正態分布是一種概率分布。正態分布是具有兩個參數μ和σ的連續型隨機變量的分布,第一參數μ是服從正態分布的隨機變量的均值,第二個參數σ是此隨機變量的方差,所以正態分布記作N(μ,σ )。
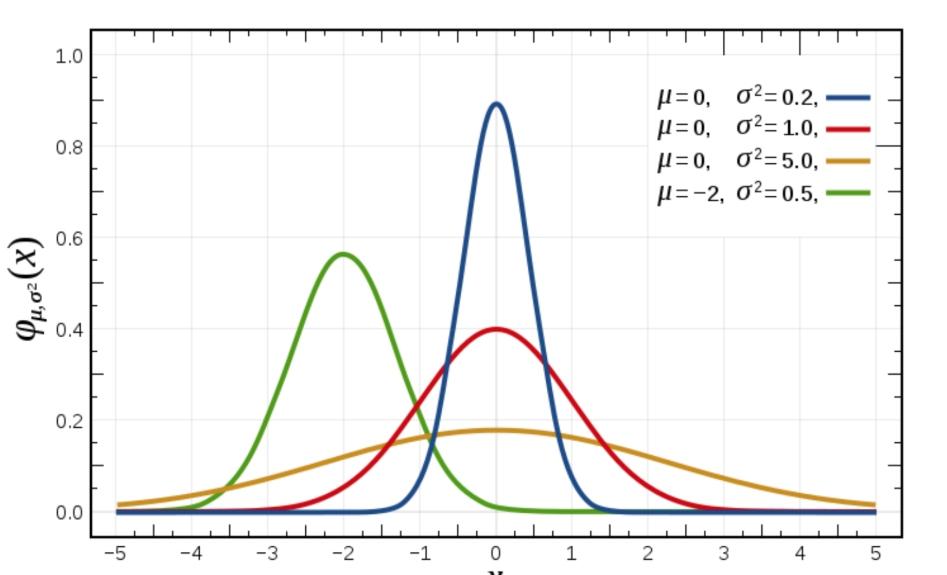
生活、生產與科學實驗中很多隨機變量的概率分布都可以近似地用正態分布來描述。μ決定了其位置,其標準差σ。決定了分布的幅度。當μ = 0,σ = 1時的正態分布是標準正態分布。
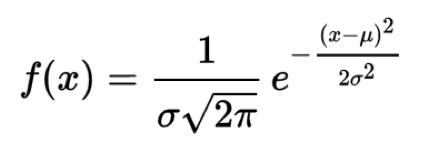
標準差如何來?方差是在概率論和統計方差衡量一組數據時離散程度的度量。
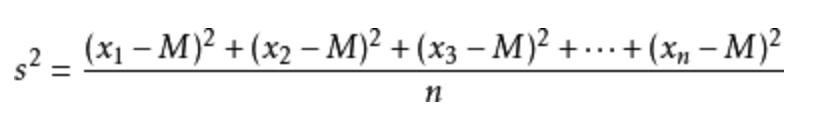
其中M為平均值,n為數據總個數,s為標準差,s^2可以理解一個整體為方差。
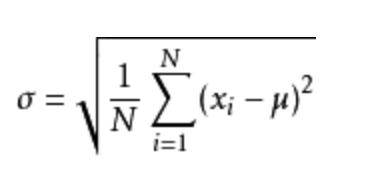
通過索引切片等獲取數組中的值,一維數組示例代碼如下:

二維數組示例代碼如下:

三維數組示例代碼如下:

5. 數組形狀與類型變化
1)ndarray.reshape(shape[, order]) Returns an array containing the same data with a new shape. 示例代碼如下:

2)ndarray.resize(new_shape[, refcheck]) Change shape and size of array in-place. 示例代碼如下:

3)修改類型 ndarray.astype(type) 示例代碼如下:

4)修改小數位數 ndarray.round(arr, out) Return a with each element rounded to the given number of decimals. 示例代碼如下:
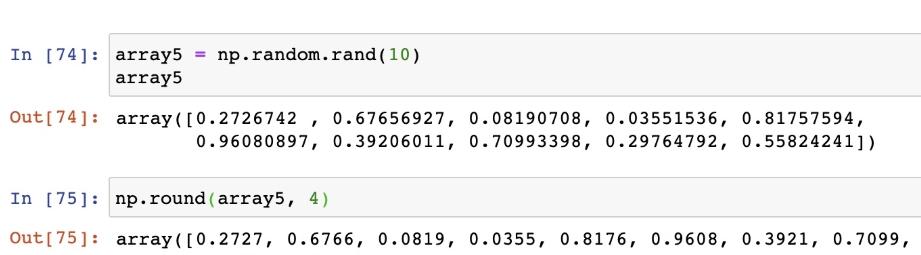
5)ndarray.flatten([order]) Return a copy of the array collapsed into one dimension. 示例代碼如下:
6)ndarray.T 數組的轉置 將數組的行、列進行互換 示例代碼如下:

7) ndarray.tostring([order])或者ndarray.tobytes([order]) Construct Python bytes containing the raw data bytes in the array. 轉換成bytes

8)ndarray.copy([order]) Return a copy of the array. 當我們不想修改某個數據的時候,就可以去進行拷貝操作。在拷貝的數據上進行操作,示例代碼如下:

關于Python中numpy優勢是什么就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





