溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹用Python爬取彩票信息的步驟,文中示例代碼介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
一、爬取網頁數據所使用到的庫
1、獲取網絡請求
requests、BeautifulSoup
2、寫入excel文件
openpyxl、pprint、column_index_from_string
注意column_index_from_string是openpyxl.utils的子庫
二、詳細處理
1、第一步我們要考慮的自然是將要爬取的url獲取,并使用get方法發起請求,返回接收的內容使用BeautifulSoup進行處理。為了方便重復利用,將其封裝到函數體當中
def get_soup(url): response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') return soup
2、返回soup對象,利用soup對象找出網頁源碼中的詳細信息
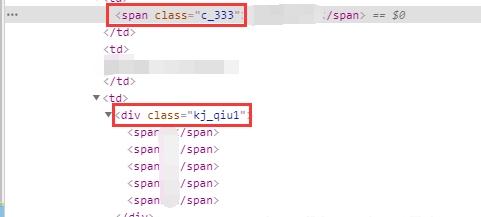
# 準備空列表用于存放期號和中獎號碼
info = []
num = []
def run_url(url):
global info, num, qihao, zhongjiang
res = get_soup(url) # 返回soup對象
# 獲取期號和中獎號碼數據
qihao = res.find_all('span', class_='c_333')
zhongjiang = res.find_all('div', class_='kj_qiu1')
# 期號列表
for i in qihao:
info.append(str(i.text))
# 中獎號碼
for i in zhongjiang:
a = i.text.split('\n')
num.append(a)調用函數找到具體代碼塊中的數據之后,將其進行適當處理分別添加到期號列表和中獎號碼列表中,進行存儲
3、簡單循環批量訪問url,并自動去替換頁數
for i in range(1, 101):
url = '相應的URL,p=%s'%i
run_url(url)
# 將最后的數據進行壓縮處理成字典格式存儲,寫入單獨文件當中
data = dict(zip(info,num))
response = open(r'D:\res_data.py', 'w', encoding='utf-8')
response.write('allData=' + pprint.pformat(data))
print('寫入結束')三、使用生成的文件中的數據,寫入excel文件當中
1、先創建工作簿對象,將excel的sheet的格式提前設置
import openpyxl import res_data # 寫入excel表格 # 創建新的工作簿 wb = openpyxl.Workbook() sheet = wb.active sheet.title = 'Data' ws = wb['Data'] # 選中表單 ws.cell(row = 1, column = 1).value = '期號' ws.cell(row = 1, column = 2).value = '中獎號碼' # 設置列寬 ws.column_dimensions['A'].width = 20 ws.column_dimensions['D'].width = 20
2、將期號寫入文件
# 寫入期號 num = [] for key in res_data.allData.keys(): num.append(key) num_sort = num[::-1] for rowNum in range(2, len(res_data.allData)+2): ws.cell(row = rowNum, column = 1).value = num_sort[rowNum-2]
3、寫入中獎號碼
# 寫入中獎號碼
num_zhong = []
for value in res_data.allData.values():
num_zhong.append(''.join(value))
num_zhong_sort = num_zhong[::-1]
for rowNum in range(2, len(res_data.allData)+2):
ws.cell(row = rowNum, column = 2).value = num_zhong_sort[rowNum-2]4、計算某一位的中間概率,并分析前一期的概率
# 萬位
count0_0, count0_1, count0_2, count0_3, count0_4, count0_5, count0_6, count0_7,count0_8,count0_9= 0,0,0,0,0,0,0,0,0,0
for i in num_zhong:
# 萬位
if i[0] == '0':
count0_0 += 1
elif i[0] == '1':
count0_1 += 1
elif i[0] == '2':
count0_2 += 1
elif i[0] == '3':
count0_3 += 1
elif i[0] == '4':
count0_4 += 1
elif i[0] == '5':
count0_5 += 1
elif i[0] == '6':
count0_6 += 1
elif i[0] == '7':
count0_7 += 1
elif i[0] == '8':
count0_8 += 1
elif i[0] == '9':
count0_9 += 1
# 萬位
res0_0, res0_1 = round(count0_0/len(num_zhong)*100,2) ,round(count0_1/len(num_zhong)*100,2)
res0_2, res0_3 = round(count0_2/len(num_zhong)*100,2) ,round(count0_3/len(num_zhong)*100,2)
res0_4, res0_5 = round(count0_4/len(num_zhong)*100,2) ,round(count0_5/len(num_zhong)*100,2)
res0_6, res0_7 = round(count0_6/len(num_zhong)*100,2) ,round(count0_7/len(num_zhong)*100,2)
res0_8, res0_9 = round(count0_8/len(num_zhong)*100,2) ,round(count0_9/len(num_zhong)*100,2)
res_wan = {
'0':res0_0,
'1':res0_1,
'2':res0_2,
'3':res0_3,
'4':res0_4,
'5':res0_5,
'6':res0_6,
'7':res0_7,
'8':res0_8,
'9':res0_9
}
max_wan = res_wan['0']
max_key = 0
for key in res_wan.keys():
if res_wan[key] > max_wan:
max_wan = res_wan[key]
max_key = key
zhongjiang = dict(zip(num[::-1], num_zhong[::-1]))
zj_qihao = []
zj_qianyiqi = []
zj_num = []
zj_qnum = []
for key, value in zhongjiang.items():
#print(key, value)
if int(value[0]) == max_key:
qihao = int(key)
#print(qihao, value)
qianyiqi = str(qihao - 1)
if qihao and qianyiqi in zhongjiang:
zj_qihao.append(qihao)
zj_num.append(zhongjiang[str(qihao)])
zj_qianyiqi.append(qianyiqi)
zj_qnum.append(zhongjiang[qianyiqi])
# 計算前一期概率
count0_zjq ,count1_zjq,count2_zjq,count3_zjq,count4_zjq,count5_zjq,count6_zjq,count7_zjq,count8_zjq,count9_zjq= 0,0,0,0,0,0,0,0,0,0
for i in zj_qnum:
if i[0] == '0':
count0_zjq += 1
elif i[0]=='1':
count1_zjq += 1
elif i[0]=='2':
count2_zjq += 1
elif i[0]=='3':
count3_zjq += 1
elif i[0]=='4':
count4_zjq += 1
elif i[0]=='5':
count5_zjq += 1
elif i[0]=='6':
count6_zjq += 1
elif i[0]=='7':
count7_zjq += 1
elif i[0]=='8':
count8_zjq += 1
elif i[0]=='9':
count9_zjq += 1
res0_zjq,res1_zjq = round(count0_zjq/len(zj_qnum),2),round(count1_zjq/len(zj_qnum),2)
res2_zjq,res3_zjq = round(count2_zjq/len(zj_qnum),2),round(count3_zjq/len(zj_qnum),2)
res4_zjq,res5_zjq = round(count4_zjq/len(zj_qnum),2),round(count5_zjq/len(zj_qnum),2)
res6_zjq,res7_zjq = round(count6_zjq/len(zj_qnum),2),round(count7_zjq/len(zj_qnum),2)
res8_zjq,res9_zjq = round(count8_zjq/len(zj_qnum),2),round(count9_zjq/len(zj_qnum),2)\
# 計算最大概率
probability = [res0_zjq,res1_zjq,res2_zjq,res3_zjq,res4_zjq,res5_zjq,res6_zjq,res7_zjq,res8_zjq,res9_zjq]
max_probability = probability[0] # 最大概率
max_probability_num = 0 # 最大概率數字
for i in range(len(probability)):
if probability[i] > max_probability:
max_probability = probability[i]
max_probability_num = i
ws.cell(row = 1, column = 4).value = '萬位最大概率數字'
ws.cell(row = 1, column = 5).value = '概率'
ws.cell(row = 2, column = 4).value = max_key
ws.cell(row = 2, column = 5).value = max_wan
ws.cell(row = 3, column = 4).value = '前一期萬位最大概率'
ws.cell(row = 4, column = 4).value = max_probability_num
ws.cell(row = 4, column = 5).value = max_probability*100
for i in probability:
print(i)
for row in range(len(probability)):
ws.cell(row=row + 5, column=4).value = row
ws.cell(row=row + 5, column=5).value = probability[row]*100
wb.save(filename='D:/caipiao.xlsx')
print('Write Over!')
4、保存文件即可
wb.save(filename='指定路徑文件')
print('Write Over!')以上是用Python爬取彩票信息的步驟的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





