溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Java Memory Model簡稱JMM, 是一系列的Java虛擬機平臺對開發者提供的多線程環境下的內存可見性、是否可以重排序等問題的無關具體平臺的統一的保證。(可能在術語上與Java運行時內存分布有歧義,后者指堆、方法區、線程棧等內存區域)。
并發編程有多種風格,除了CSP(通信順序進程)、Actor等模型外,大家最熟悉的應該是基于線程和鎖的共享內存模型了。在多線程編程中,需要注意三類并發問題:
·原子性
·可見性
·重排序
原子性涉及到,一個線程執行一個復合操作的時候,其他線程是否能夠看到中間的狀態、或進行干擾。典型的就是i++的問題了,兩個線程同時對共享的堆內存執行++操作,而++操作在JVM、運行時、CPU中的實現都可能是一個復合操作, 例如在JVM指令的角度來看是將i的值從堆內存讀到操作數棧、加上一、再寫回到堆內存的i,這幾個操作的期間,如果沒有正確的同步,其他線程也可以同時執行,可能導致數據丟失等問題。常見的原子性問題又叫競太條件,是基于一個可能失效的結果進行判斷,如讀取-修改-寫入。 可見性和重排序問題都源于系統的優化。
由于CPU的執行速度和內存的存取速度嚴重不匹配,為了優化性能,基于時間局部性、空間局部性等局部性原理,CPU在和內存間增加了多層高速緩存,當需要取數據時,CPU會先到高速緩存中查找對應的緩存是否存在,存在則直接返回,如果不存在則到內存中取出并保存在高速緩存中。現在多核處理器越基本已經成為標配,這時每個處理器都有自己的緩存,這就涉及到了緩存一致性的問題,CPU有不同強弱的一致性模型,最強的一致性安全性最高,也符合我們的順序思考的模式,但是在性能上因為需要不同CPU之間的協調通信就會有很多開銷。
典型的CPU緩存結構示意圖如下

CPU的指令周期通常為取指令、解析指令讀取數據、執行指令、數據寫回寄存器或內存。串行執行指令時其中的讀取存儲數據部分占用時間較長,所以CPU普遍采取指令流水線的方式同時執行多個指令, 提高整體吞吐率,就像工廠流水線一樣。
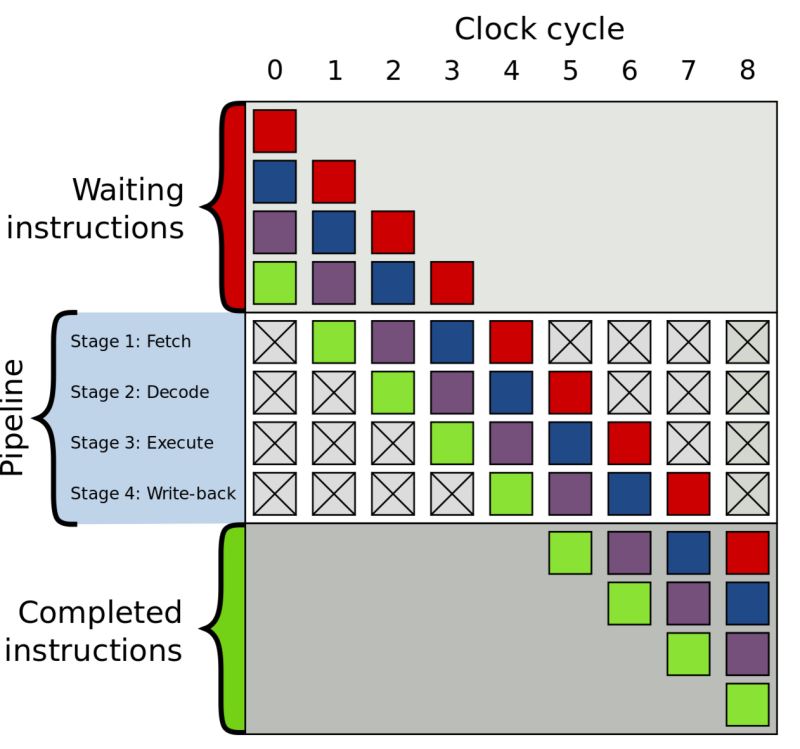
讀取數據和寫回數據到內存相比執行指令的速度不在一個數量級上,所以CPU使用寄存器、高速緩存作為緩存和緩沖,在從內存中讀取數據時,會讀取一個緩存行(cache line)的數據(類似磁盤讀取讀取一個block)。數據寫回的模塊在舊數據沒有在緩存中的情況下會將存儲請求放入一個store buffer中繼續執行指令周期的下一個階段,如果存在于緩存中則會更新緩存,緩存中的數據會根據一定策略flush到內存。
public class MemoryModel {
private int count;
private boolean stop;
public void initCountAndStop() {
count = 1;
stop = false;
}
public void doLoop() {
while(!stop) {
count++;
}
}
public void printResult() {
System.out.println(count);
System.out.println(stop);
}
}
上面這段代碼執行時我們可能認為count = 1會在stop = false前執行完成,這在上面的CPU執行圖中顯示的理想狀態下是正確的,但是要考慮上寄存器、緩存緩沖的時候就不正確了, 例如stop本身在緩存中但是count不在,則可能stop更新后再count的write buffer寫回之前刷新到了內存。
另外CPU、編譯器(對于Java一般指JIT)都可能會修改指令執行順序,例如上述代碼中count = 1和stop = false兩者并沒有依賴關系,所以CPU、編譯器都有可能修改這兩者的順序,而在單線程執行的程序看來結果是一樣的,這也是CPU、編譯器要保證的as-if-serial(不管如何修改執行順序,單線程的執行結果不變)。由于很大部分程序執行都是單線程的,所以這樣的優化是可以接受并且帶來了較大的性能提升。但是在多線程的情況下,如果沒有進行必要的同步操作則可能會出現令人意想不到的結果。例如在線程T1執行完initCountAndStop方法后,線程T2執行printResult,得到的可能是0, false, 可能是1, false, 也可能是0, true。如果線程T1先執行doLoop(),線程T2一秒后執行initCountAndStop, 則T1可能會跳出循環、也可能由于編譯器的優化永遠無法看到stop的修改。
由于上述這些多線程情況下的各種問題,多線程中的程序順序已經不是底層機制中的執行順序和結果,編程語言需要給開發者一種保證,這個保證簡單來說就是一個線程的修改何時對其他線程可見,因此Java語言提出了JavaMemoryModel即Java內存模型,對于Java語言、JVM、編譯器等實現者需要按照這個模型的約定來進行實現。Java提供了Volatile、synchronized、final等機制來幫助開發者保證多線程程序在所有處理器平臺上的正確性。
在JDK1.5之前,Java的內存模型有著嚴重的問題,例如在舊的內存模型中,一個線程可能在構造器執行完成后看到一個final字段的默認值、volatile字段的寫入可能會和非volatile字段的讀寫重排序。
所以在JDK1.5中,通過JSR133提出了新的內存模型,修復之前出現的問題。
重排序規則
volatile和監視器鎖
| 是否可以重排序 | 第二個操作 | 第二個操作 | 第二個操作 |
|---|---|---|---|
| 第一個操作 | 普通讀/普通寫 | volatile讀/monitor enter | volatile寫/monitor exit |
| 普通讀/普通寫 | No | ||
| voaltile讀/monitor enter | No | No | No |
| volatile寫/monitor exit | No | No |
其中普通讀指getfield, getstatic, 非volatile數組的arrayload, 普通寫指putfield, putstatic, 非volatile數組的arraystore。
volatile讀寫分別是volatile字段的getfield, getstatic和putfield, putstatic。
monitorenter是進入同步塊或同步方法,monitorexist指退出同步塊或同步方法。
上述表格中的No指先后兩個操作不允許重排序,如(普通寫, volatile寫)指非volatile字段的寫入不能和之后任意的volatile字段的寫入重排序。當沒有No時,說明重排序是允許的,但是JVM需要保證最小安全性-讀取的值要么是默認值,要么是其他線程寫入的(64位的double和long讀寫操作是個特例,當沒有volatile修飾時,并不能保證讀寫是原子的,底層可能將其拆分為兩個單獨的操作)。
final字段
final字段有兩個額外的特殊規則
final字段的寫入(在構造器中進行)以及final字段對象本身的引用的寫入都不能和后續的(構造器外的)持有該final字段的對象的寫入重排序。例如, 下面的語句是不能重排序的
x.finalField = v; ...; sharedRef = x;
final字段的第一次加載不能和持有這個final字段的對象的寫入重排序,例如下面的語句是不允許重排序的
x = sharedRef; ...; i = x.finalField
內存屏障
處理器都支持一定的內存屏障(memory barrier)或柵欄(fence)來控制重排序和數據在不同的處理器間的可見性。例如,CPU將數據寫回時,會將store請求放入write buffer中等待flush到內存,可以通過插入barrier的方式防止這個store請求與其他的請求重排序、保證數據的可見性。可以用一個生活中的例子類比屏障,例如坐地鐵的斜坡式電梯時,大家按順序進入電梯,但是會有一些人從左側繞過去,這樣出電梯時順序就不相同了,如果有一個人攜帶了一個大的行李堵住了(屏障),則后面的人就不能繞過去了:)。另外這里的barrier和GC中用到的write barrier是不同的概念。
內存屏障的分類
幾乎所有的處理器都支持一定粗粒度的barrier指令,通常叫做Fence(柵欄、圍墻),能夠保證在fence之前發起的load和store指令都能嚴格的和fence之后的load和store保持有序。通常按照用途會分為下面四種barrier
LoadLoad Barriers
Load1; LoadLoad; Load2;
保證Load1的數據在Load2及之后的load前加載
StoreStore Barriers
Store1; StoreStore; Store2
保證Store1的數據先于Store2及之后的數據 在其他處理器可見
LoadStore Barriers
Load1; LoadStore; Store2
保證Load1的數據的加載在Store2和之后的數據flush前
StoreLoad Barriers
Store1; StoreLoad; Load2
保證Store1的數據在其他處理器前可見(如flush到內存)先于Load2和之后的load的數據的加載。StoreLoad Barrier能夠防止load讀取到舊數據而不是最近其他處理器寫入的數據。
幾乎近代的所有的多處理器都需要StoreLoad,StoreLoad的開銷通常是最大的,并且StoreLoad具有其他三種屏障的效果,所以StoreLoad可以當做一個通用的(但是更高開銷的)屏障。
所以,利用上述的內存屏障,可以實現上面表格中的重排序規則
| 需要的屏障 | 第二個操作 | 第二個操作 | 第二個操作 | 第二個操作 |
|---|---|---|---|---|
| 第一個操作 | 普通讀 | 普通寫 | volatile讀/monitor enter | volatile寫/monitor exit |
| 普通讀 | LoadStore | |||
| 普通讀 | StoreStore | |||
| voaltile讀/monitor enter | LoadLoad | LoadStore | LoadLoad | LoadStore |
| volatile寫/monitor exit | StoreLoad | StoreStore |
為了支持final字段的規則,需要對final的寫入增加barrier
x.finalField = v; StoreStore; sharedRef = x;
插入內存屏障
基于上面的規則,可以在volatile字段、synchronized關鍵字的處理上增加屏障來滿足內存模型的規則
volatile store前插入StoreStore屏障
所有final字段寫入后但在構造器返回前插入StoreStore
volatile store后插入StoreLoad屏障
在volatile load后插入LoadLoad和LoadStore屏障
monitor enter和volatile load規則一致,monitor exit 和volatile store規則一致。
HappenBefore
前面提到的各種內存屏障對應開發者來說還是比較復雜底層,因此JMM又可以使用一系列HappenBefore的偏序關系的規則方式來說明,要想保證執行操作B的線程看到操作A的結果(無論A和B是否在同一個線程中執行), 那么在A和B之間必須要滿足HappenBefore關系,否則JVM可以對它們任意重排序。
HappenBefore規則列表
HappendBefore規則包括
程序順序規則: 如果程序中操作A在操作B之前,那么同一個線程中操作A將在操作B之前進行
監視器鎖規則: 在監視器鎖上的鎖操作必須在同一個監視器鎖上的加鎖操作之前執行
volatile變量規則: volatile變量的寫入操作必須在該變量的讀操作之前執行
線程啟動規則: 在線程上對Thread.start的調用必須在該線程中執行任何操作之前執行
線程結束規則: 線程中的任何操作都必須在其他線程檢測到該線程已經結束之前執行
中斷規則: 當一個線程在另一個線程上調用interrupt時,必須在被中斷線程檢測到interrupt之前執行
傳遞性: 如果操作A在操作B之前執行,并且操作B在操作C之前執行,那么操作A在操作C之前執行。
其中顯示鎖與監視器鎖有相同的內存語義,原子變量與volatile有相同的內存語義。鎖的獲取和釋放、volatile變量的讀取和寫入操作滿足全序關系,所以可以使用volatile的寫入在后續的volatile的讀取之前進行。
可以利用上述HappenBefore的多個規則進行組合。
例如線程A進入監視器鎖后,在釋放監視器鎖之前的操作根據程序順序規則HappenBefore于監視器釋放操作,而監視器釋放操作HappenBefore于后續的線程B的對相同監視器鎖的獲取操作,獲取操作HappenBefore與線程B中的操作。
總結
以上就是本文關于Java內存模型JMM詳解的全部內容,希望對大家有所幫助。如有不足之處,歡迎留言指出。感謝朋友們對本站的支持!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





