溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關使用kotlin怎么統計文件中字符的個數,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
首先找到一個要統計的文件。
val file = "F:\\MyBook\\讀書備忘錄.txt"
然后建立一個HashMap,用來存儲統計的結果。
val map = HashMap<Char, Int>()
讀取文件內容,轉換成Char進行遍歷統計
File(file).readText().toCharArray().filterNot(Char::isWhitespace).forEach {
val count = map[it]
if (count == null){
map[it] = 1
}else{
map[it] = count +1
}
}readText()就是讀取文件內容了
toCharArray()轉成Char數組
filterNot(Char::isWhitespace)忽略空格
遍歷的時候,把當前遍歷到的map[it]賦給 count ,如果在 map 中沒找到這個字符,即 count == null,則為初次記錄,map[it] 為1,否則 map[it] 已經記錄過了,在原有計數基礎上加1。
最后輸出統計結果
map.forEach { t, u -> println("字符\"$t\"出現了 $u 次")}執行效果如下
統計文件中每個字符的個數 字符"言"出現了 1 次 字符"需"出現了 1 次 字符"最"出現了 1 次 字符"要"出現了 1 次 字符"節"出現了 1 次 字符"。"出現了 1 次 字符"窄"出現了 1 次 字符"的"出現了 1 次 字符"★"出現了 5 次 字符"("出現了 1 次 字符"按"出現了 1 次 字符")"出現了 1 次 字符"《"出現了 1 次 字符"》"出現了 1 次 字符","出現了 2 次 字符"完"出現了 1 次 字符"復"出現了 1 次 字符"后"出現了 2 次 字符"題"出現了 1 次 字符":"出現了 1 次 字符"圣"出現了 1 次 字符"個"出現了 1 次 字符"本"出現了 1 次 字符"-"出現了 2 次 字符"."出現了 2 次 字符"0"出現了 4 次 字符"新"出現了 1 次 字符"1"出現了 6 次 字符"2"出現了 3 次 字符"3"出現了 2 次 字符"6"出現了 3 次 字符"邊"出現了 1 次 字符"雅"出現了 1 次 字符"G"出現了 1 次 字符"版"出現了 1 次 字符"重"出現了 1 次 字符"經"出現了 1 次 字符"黑"出現了 1 次 字符"體"出現了 1 次 字符"字"出現了 1 次 字符"這"出現了 1 次 字符"距"出現了 1 次 字符"章"出現了 1 次 字符"習"出現了 2 次 字符"d"出現了 1 次 字符"f"出現了 1 次 字符"學"出現了 1 次 字符"書"出現了 1 次 字符"照"出現了 1 次 字符"全"出現了 1 次 字符"語"出現了 1 次 字符"o"出現了 1 次 字符"p"出現了 1 次 字符"數"出現了 1 次 字符"讀"出現了 1 次
上面的讀取還不夠簡練,我們可以再簡化一點,完全不必聲明 HashMap。
val file = "F:\\MyBook\\讀書備忘錄.txt"
File(file).readText().toCharArray().filterNot(Char::isWhitespace).groupBy{it}.map {
it.key to it.value.size
}.forEach{
println("字符\"${it.first}\"出現了 ${it.second} 次")
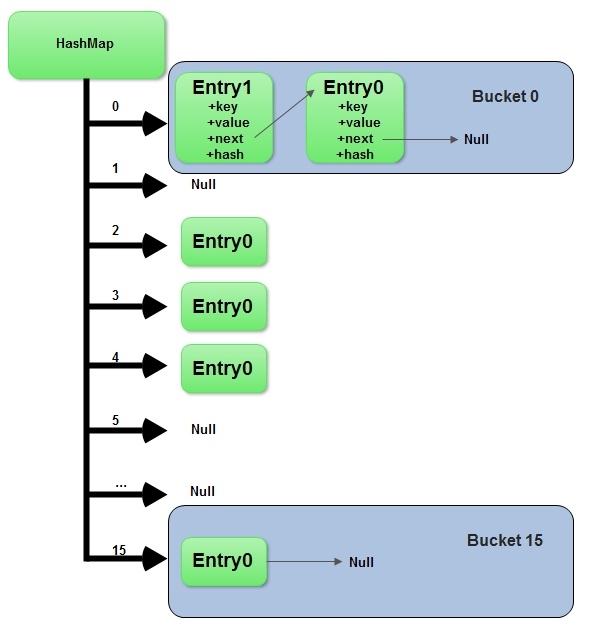
}附上:HashMap結構圖
關于使用kotlin怎么統計文件中字符的個數就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





