溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關Android硬件加速的原理是什么,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
前言
硬件加速,直觀上說就是依賴 GPU 實現圖形繪制加速,同軟硬件加速的區別主要是圖形的繪制究竟是 GPU 來處理還是 CPU,如果是GPU,就認為是硬件加速繪制,反之,軟件繪制。在 Android 中也是如此,不過相對于普通的軟件繪制,硬件加速還做了其他方面優化,不僅僅限定在繪制方面,繪制之前,在如何構建繪制區域上,硬件加速也做出了很大優化,因此硬件加速特性可以從下面兩部分來分析:
1、前期策略:如何構建需要繪制的區域
2、后期繪制:單獨渲染線程,依賴 GPU 進行繪制
無論是軟件繪制還是硬件加速,繪制內存的分配都是類似的,都是需要請求 SurfaceFlinger 服務分配一塊內存,只不過硬件加速有可能從FrameBuffer 硬件緩沖區直接分配內存(SurfaceFlinger 一直這么干的),兩者的繪制都是在APP端,繪制完成之后同樣需要通知SurfaceFlinger 進行合成,在這個流程上沒有任何區別,真正的區別在于在 APP 端如何完成UI數據繪制,本文就直觀的了解下兩者的區別,會涉及部分源碼,但不求甚解。
軟硬件加速的分歧點
大概從 Android 4.+開始,默認情況下都是支持跟開啟了硬件加速的,也存在手機支持硬件加速,但是部分API不支持硬件加速的情況,如果使用了這些API,就需要主關閉硬件加速,或者在 View 層,或者在Activity 層,比如 Canvas 的 clipPath等。但是,View 的繪制是軟件加速實現的還是硬件加速實現的,一般在開發的時候并不可見,那圖形繪制的時候,軟硬件的分歧點究竟在哪呢?舉個例子,有個 View 需要重繪,一般會調用 View 的 invalidate,觸發重繪,跟著這條線走,去查一下分歧點。
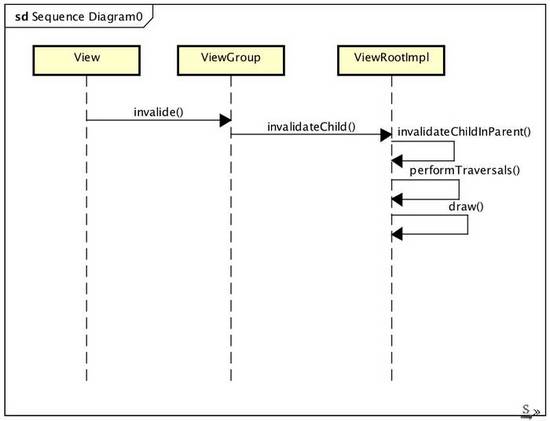
從上面的調用流程可以看出,視圖重繪最后會進入ViewRootImpl的draw,這里有個判斷點是軟硬件加速的分歧點,簡化后如下
ViewRootImpl.java
private void draw(boolean fullRedrawNeeded) {
...
if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) {
<!--關鍵點1 是否開啟硬件加速-->
if (mAttachInfo.mHardwareRenderer != null && mAttachInfo.mHardwareRenderer.isEnabled()) {
...
dirty.setEmpty();
mBlockResizeBuffer = false;
<!--關鍵點2 硬件加速繪制-->
mAttachInfo.mHardwareRenderer.draw(mView, mAttachInfo, this);
} else {
...
<!--關鍵點3 軟件繪制-->
if (!drawSoftware(surface, mAttachInfo, xOffset, yOffset, scalingRequired, dirty)) {
return;
}
...關鍵點1是啟用硬件加速的條件,必須支持硬件并且開啟了硬件加速才可以,滿足,就利用 HardwareRenderer.draw,否則 drawSoftware(軟件繪制)。簡答看一下這個條件,默認情況下,該條件是成立的,因為4.+之后的手機一般都支持硬件加速,而且在添加窗口的時候,ViewRootImpl 會 enableHardwareAcceleration 開啟硬件加速,new HardwareRenderer,并初始化硬件加速環境。
private void enableHardwareAcceleration(WindowManager.LayoutParams attrs) {
<!--根據配置,獲取硬件加速的開關-->
// Try to enable hardware acceleration if requested
final boolean hardwareAccelerated =
(attrs.flags & WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED) != 0;
if (hardwareAccelerated) {
...
<!--新建硬件加速圖形渲染器-->
mAttachInfo.mHardwareRenderer = HardwareRenderer.create(mContext, translucent);
if (mAttachInfo.mHardwareRenderer != null) {
mAttachInfo.mHardwareRenderer.setName(attrs.getTitle().toString());
mAttachInfo.mHardwareAccelerated =
mAttachInfo.mHardwareAccelerationRequested = true;
}
...其實到這里軟件繪制跟硬件加速的分歧點已經找到了,就是ViewRootImpl在draw 的時候,如果需要硬件加速就利用 HardwareRenderer 進行 draw,否則走軟件繪制流程,drawSoftware其實很簡單,利用 Surface.lockCanvas,向 SurfaceFlinger 申請一塊匿名共享內存內存分配,同時獲取一個普通的 SkiaCanvas,用于調用Skia 庫,進行圖形繪制,
private boolean drawSoftware(Surface surface, AttachInfo attachInfo, int xoff, int yoff,
boolean scalingRequired, Rect dirty) {
final Canvas canvas;
try {
<!--關鍵點1 -->
canvas = mSurface.lockCanvas(dirty);
..
<!--關鍵點2 繪制-->
mView.draw(canvas);
..
關鍵點3 通知SurfaceFlinger進行圖層合成
surface.unlockCanvasAndPost(canvas);
} ...
return true; }drawSoftware 工作完全由 CPU 來完成,不會牽扯到 GPU 的操作,下面重點看下 HardwareRenderer 所進行的硬件加速繪制。
HardwareRenderer 硬件加速繪制模型
開頭說過,硬件加速繪制包括兩個階段:構建階段+繪制階段,所謂構建就是遞歸遍歷所有視圖,將需要的操作緩存下來,之后再交給單獨的Render 線程利用 OpenGL 渲染。在 Android 硬件加速框架中,View視圖被抽象成 RenderNode 節點,View 中的繪制都會被抽象成一個個DrawOp(DisplayListOp),比如 View 中 drawLine,構建中就會被抽象成一個 DrawLintOp,drawBitmap 操作會被抽象成DrawBitmapOp,每個子 View 的繪制被抽象成DrawRenderNodeOp,每個 DrawOp 有對應的 OpenGL 繪制命令,同時內部也握著繪圖所需要的數據。如下所示:
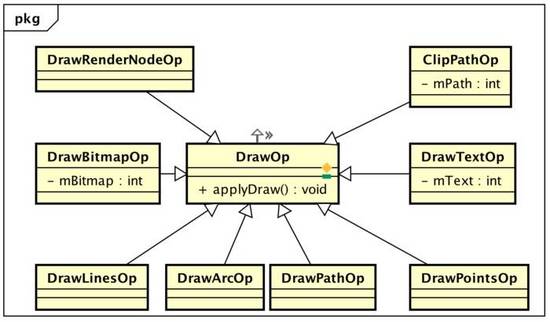
繪圖Op抽象
如此以來,每個 View 不僅僅握有自己 DrawOp List,同時還拿著子View的繪制入口,如此遞歸,便能夠統計到所有的繪制Op,很多分析都稱為 Display List,源碼中也是這么來命名類的,不過這里其實更像是一個樹,而不僅僅是List,示意如下:
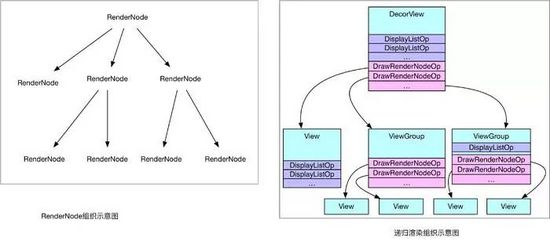
硬件加速.jpg
構建完成后,就可以將這個繪圖Op樹交給Render線程進行繪制,這里是同軟件繪制很不同的地方,軟件繪制時,View一般都在主線程中完成繪制,而硬件加速,除非特殊要求,一般都是在單獨線程中完成繪制,如此以來就分擔了主線程很多壓力,提高了UI線程的響應速度。
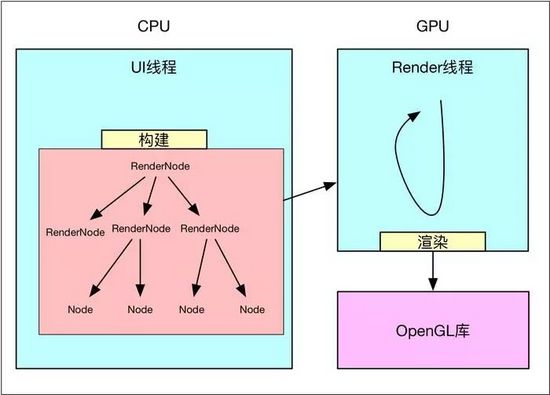
硬件加速模型.jpg
知道整個模型后,就代碼來簡單了解下實現流程,先看下遞歸構建RenderNode 樹及 DrawOp 集。
利用HardwareRenderer構建DrawOp集
HardwareRenderer 是整個硬件加速繪制的入口,實現是一個ThreadedRenderer 對象,從名字能看出,ThreadedRenderer應該跟一個Render線程息息相關,不過ThreadedRenderer是在UI線程中創建的,那么與UI線程也必定相關,其主要作用:
1、在UI線程中完成DrawOp集構建
2、負責跟渲染線程通信
可見ThreadedRenderer的作用是很重要的,簡單看一下實現:
ThreadedRenderer(Context context, boolean translucent) {
...
<!--新建native node-->
long rootNodePtr = nCreateRootRenderNode();
mRootNode = RenderNode.adopt(rootNodePtr);
mRootNode.setClipToBounds(false);
<!--新建NativeProxy-->
mNativeProxy = nCreateProxy(translucent, rootNodePtr);
ProcessInitializer.sInstance.init(context, mNativeProxy);
loadSystemProperties();
}從上面代碼看出,ThreadedRenderer中有一個RootNode用來標識整個DrawOp樹的根節點,有個這個根節點就可以訪問所有的繪制Op,同時還有個RenderProxy對象,這個對象就是用來跟渲染線程進行通信的句柄,看一下其構造函數:
RenderProxy::RenderProxy(bool translucent, RenderNode* rootRenderNode, IContextFactory* contextFactory)
: mRenderThread(RenderThread::getInstance())
, mContext(nullptr) {
SETUP_TASK(createContext);
args->translucent = translucent;
args->rootRenderNode = rootRenderNode;
args->thread = &mRenderThread;
args->contextFactory = contextFactory;
mContext = (CanvasContext*) postAndWait(task);
mDrawFrameTask.setContext(&mRenderThread, mContext);
}從RenderThread::getInstance()可以看出,RenderThread是一個單例線程,也就是說,每個進程最多只有一個硬件渲染線程,這樣就不會存在多線程并發訪問沖突問題,到這里其實環境硬件渲染環境已經搭建好好了。下面就接著看ThreadedRenderer的draw函數,如何構建渲染Op樹:
@Override
void draw(View view, AttachInfo attachInfo, HardwareDrawCallbacks callbacks) {
attachInfo.mIgnoreDirtyState = true;
final Choreographer choreographer = attachInfo.mViewRootImpl.mChoreographer;
choreographer.mFrameInfo.markDrawStart();
<!--關鍵點1:構建View的DrawOp樹-->
updateRootDisplayList(view, callbacks);
<!--關鍵點2:通知RenderThread線程繪制-->
int syncResult = nSyncAndDrawFrame(mNativeProxy, frameInfo, frameInfo.length);
...
}只關心關鍵點1 updateRootDisplayList,構建RootDisplayList,其實就是構建View的DrawOp樹,updateRootDisplayList會進而調用根View的updateDisplayListIfDirty,讓其遞歸子View的updateDisplayListIfDirty,從而完成DrawOp樹的創建,簡述一下流程:
private void updateRootDisplayList(View view, HardwareDrawCallbacks callbacks) {
<!--更新-->
updateViewTreeDisplayList(view);
if (mRootNodeNeedsUpdate || !mRootNode.isValid()) {
<!--獲取DisplayListCanvas-->
DisplayListCanvas canvas = mRootNode.start(mSurfaceWidth, mSurfaceHeight);
try {
<!--利用canvas緩存Op-->
final int saveCount = canvas.save();
canvas.translate(mInsetLeft, mInsetTop);
callbacks.onHardwarePreDraw(canvas);
canvas.insertReorderBarrier();
canvas.drawRenderNode(view.updateDisplayListIfDirty());
canvas.insertInorderBarrier();
callbacks.onHardwarePostDraw(canvas);
canvas.restoreToCount(saveCount);
mRootNodeNeedsUpdate = false;
} finally {
<!--將所有Op填充到RootRenderNode-->
mRootNode.end(canvas);
}
}
}利用View的RenderNode獲取一個DisplayListCanvas
利用DisplayListCanvas構建并緩存所有的DrawOp
將DisplayListCanvas緩存的DrawOp填充到RenderNode
將根View的緩存DrawOp設置到RootRenderNode中,完成構建
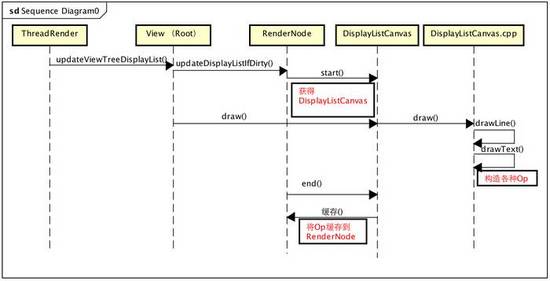
繪制流程
簡單看一下View遞歸構建DrawOp,并將自己填充到
@NonNull
public RenderNode updateDisplayListIfDirty() {
final RenderNode renderNode = mRenderNode;
...
// start 獲取一個 DisplayListCanvas 用于繪制 硬件加速
final DisplayListCanvas canvas = renderNode.start(width, height);
try {
// 是否是textureView
final HardwareLayer layer = getHardwareLayer();
if (layer != null && layer.isValid()) {
canvas.drawHardwareLayer(layer, 0, 0, mLayerPaint);
} else if (layerType == LAYER_TYPE_SOFTWARE) {
// 是否強制軟件繪制
buildDrawingCache(true);
Bitmap cache = getDrawingCache(true);
if (cache != null) {
canvas.drawBitmap(cache, 0, 0, mLayerPaint);
}
} else {
// 如果僅僅是ViewGroup,并且自身不用繪制,直接遞歸子View
if ((mPrivateFlags & PFLAG_SKIP_DRAW) == PFLAG_SKIP_DRAW) {
dispatchDraw(canvas);
} else {
<!--調用自己draw,如果是ViewGroup會遞歸子View-->
draw(canvas);
}
}
} finally {
<!--緩存構建Op-->
renderNode.end(canvas);
setDisplayListProperties(renderNode);
}
}
return renderNode;
}TextureView跟強制軟件繪制的View比較特殊,有額外的處理,這里不關心,直接看普通的draw,假如在View onDraw中,有個drawLine,這里就會調用DisplayListCanvas的drawLine函數,DisplayListCanvas及RenderNode類圖大概如下
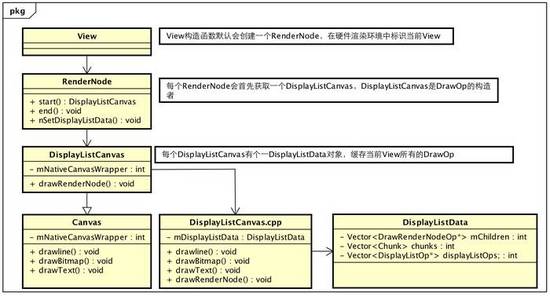
硬件加速類圖
DisplayListCanvas的drawLine 函數最終會進入DisplayListCanvas.cpp的drawLine,
void DisplayListCanvas::drawLines(const float* points, int count, const SkPaint& paint) {
points = refBuffer<float>(points, count);
addDrawOp(new (alloc()) DrawLinesOp(points, count, refPaint(&paint)));
}可以看到,這里構建了一個DrawLinesOp,并添加到DisplayListCanvas的緩存列表中去,如此遞歸便可以完成DrawOp樹的構建,在構建后利用RenderNode的end函數,將DisplayListCanvas中的數據緩存到RenderNode中去:
public void end(DisplayListCanvas canvas) {
canvas.onPostDraw();
long renderNodeData = canvas.finishRecording();
<!--將DrawOp緩存到RenderNode中去-->
nSetDisplayListData(mNativeRenderNode, renderNodeData);
// canvas 回收掉]
canvas.recycle();
mValid = true;
}如此,便完成了DrawOp樹的構建,之后,利用RenderProxy向RenderThread發送消息,請求OpenGL線程進行渲染。
RenderThread渲染UI到Graphic Buffer
DrawOp樹構建完畢后,UI線程利用RenderProxy向RenderThread線程發送一個DrawFrameTask任務請求,RenderThread被喚醒,開始渲染,大致流程如下:
首先進行DrawOp的合并
接著繪制特殊的Layer
最后繪制其余所有的DrawOpList
調用swapBuffers將前面已經繪制好的圖形緩沖區提交給Surface Flinger合成和顯示。
不過再這之前先復習一下繪制內存的由來,畢竟之前DrawOp樹的構建只是在普通的用戶內存中,而部分數據對于SurfaceFlinger都是不可見的,之后又繪制到共享內存中的數據才會被SurfaceFlinger合成,之前分析過軟件繪制的UI是來自匿名共享內存,那么硬件加速的共享內存來自何處呢?到這里可能要倒回去看看 ViewRootImlp
private void performTraversals() {
...
if (mAttachInfo.mHardwareRenderer != null) {
try {
hwInitialized = mAttachInfo.mHardwareRenderer.initialize(
mSurface);
if (hwInitialized && (host.mPrivateFlags
& View.PFLAG_REQUEST_TRANSPARENT_REGIONS) == 0) {
mSurface.allocateBuffers();
}
} catch (OutOfResourcesException e) {
handleOutOfResourcesException(e);
return;
}
}
....
/**
* Allocate buffers ahead of time to avoid allocation delays during rendering
* @hide
*/
public void allocateBuffers() {
synchronized (mLock) {
checkNotReleasedLocked();
nativeAllocateBuffers(mNativeObject);
}
}可以看出,對于硬件加速的場景,內存分配的時機會稍微提前,而不是像軟件繪制事,由Surface的lockCanvas發起,主要目的是:避免在渲染的時候再申請,一是避免分配失敗,浪費了CPU之前的準備工作,二是也可以將渲染線程個工作簡化,在分析Android窗口管理分析(4):Android View繪制內存的分配、傳遞、使用的時候分析過,在分配成功后,如果有必要,會進行一次UI數據拷貝,這是局部繪制的根基,也是保證DrawOp可以部分執行的基礎,到這里內存也分配完畢。不過,還是會存在另一個問題,一個APP進程,同一時刻會有過個Surface繪圖界面,但是渲染線程只有一個,那么究竟渲染那個呢?這個時候就需要將Surface與渲染線程(上下文)綁定。
static jboolean android_view_ThreadedRenderer_initialize(JNIEnv* env, jobject clazz,
jlong proxyPtr, jobject jsurface) {
RenderProxy* proxy = reinterpret_cast<RenderProxy*>(proxyPtr);
sp<ANativeWindow> window = android_view_Surface_getNativeWindow(env, jsurface);
return proxy->initialize(window);
}首先通過android_view_Surface_getNativeWindowSurface獲取Surface,在Native層,Surface對應一個ANativeWindow,接著,通過RenderProxy類的成員函數initialize將前面獲得的ANativeWindow綁定到RenderThread
bool RenderProxy::initialize(const sp<ANativeWindow>& window) {
SETUP_TASK(initialize);
args->context = mContext;
args->window = window.get();
return (bool) postAndWait(task);
}仍舊是向渲染線程發送消息,讓其綁定當前Window,其實就是調用CanvasContext的initialize函數,讓繪圖上下文綁定繪圖內存:
bool CanvasContext::initialize(ANativeWindow* window) {
setSurface(window);
if (mCanvas) return false;
mCanvas = new OpenGLRenderer(mRenderThread.renderState());
mCanvas->initProperties();
return true;
}CanvasContext通過setSurface將當前要渲染的Surface綁定到到RenderThread中,大概流程是通過eglApi獲得一個EGLSurface,EGLSurface封裝了一個繪圖表面,進而,通過eglApi將EGLSurface設定為當前渲染窗口,并將繪圖內存等信息進行同步,之后通過RenderThread繪制的時候才能知道是在哪個窗口上進行繪制。這里主要是跟OpenGL庫對接,所有的操作最終都會歸結到eglApi抽象接口中去。假如,這里不是Android,是普通的Java平臺,同樣需要相似的操作,進行封裝處理,并綁定當前EGLSurface才能進行渲染,因為OpenGL是一套規范,想要使用,就必須按照這套規范走。之后,再創建一個OpenGLRenderer對象,后面執行OpenGL相關操作的時候,其實就是通過OpenGLRenderer來進行的。
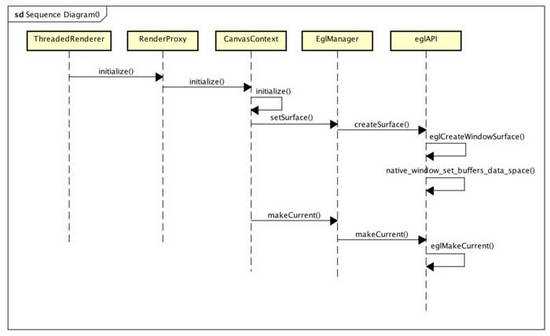
綁定流程
上面的流程走完,有序DrawOp樹已經構建好、內存也已分配好、環境及場景也綁定成功,剩下的就是繪制了,不過之前說過,真正調用OpenGL繪制之前還有一些合并操作,這是Android硬件加速做的優化,回過頭繼續走draw流程,其實就是走OpenGLRenderer的drawRenderNode進行遞歸處理:
void OpenGLRenderer::drawRenderNode(RenderNode* renderNode, Rect& dirty, int32_t replayFlags) {
...
<!--構建deferredList-->
DeferredDisplayList deferredList(mState.currentClipRect(), avoidOverdraw);
DeferStateStruct deferStruct(deferredList, *this, replayFlags);
<!--合并及分組-->
renderNode->defer(deferStruct, 0);
<!--繪制layer-->
flushLayers();
startFrame();
<!--繪制 DrawOp樹-->
deferredList.flush(*this, dirty);
...
}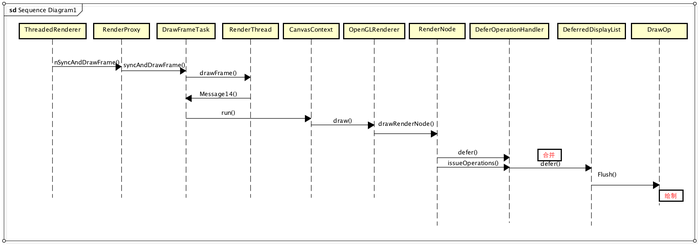
硬件加速渲染流程
先看下renderNode->defer(deferStruct, 0),合并操作,DrawOp樹并不是直接被繪制的,而是首先通過DeferredDisplayList進行一個合并優化,這個是Android硬件加速中采用的一種優化手段,不僅可以減少不必要的繪制,還可以將相似的繪制集中處理,提高繪制速度。
void RenderNode::defer(DeferStateStruct& deferStruct, const int level) {
DeferOperationHandler handler(deferStruct, level);
issueOperations<DeferOperationHandler>(deferStruct.mRenderer, handler);
}RenderNode::defer其實內含遞歸操作,比如,如果當前RenderNode代表DecorView,它就會遞歸所有的子View進行合并優化處理,簡述一下合并及優化的流程及算法,其實主要就是根據DrawOp樹構建DeferedDisplayList,defer本來就有延遲的意思,對于DrawOp的合并有兩個必要條件,
1:兩個DrawOp的類型必須相同,這個類型在合并的時候被抽象為Batch ID,取值主要有以下幾種
enum OpBatchId {
kOpBatch_None = 0, // Don't batch
kOpBatch_Bitmap,
kOpBatch_Patch,
kOpBatch_AlphaVertices,
kOpBatch_Vertices,
kOpBatch_AlphaMaskTexture,
kOpBatch_Text,
kOpBatch_ColorText,
kOpBatch_Count, // Add other batch ids before this
};2:DrawOp的Merge ID必須相同,Merge ID沒有太多限制,由每個DrawOp自定決定,不過好像只有DrawPatchOp、DrawBitmapOp、DrawTextOp比較特殊,其余的似乎不需要考慮合并問題,即時是以上三種,合并的條件也很苛刻
在合并過程中,DrawOp被分為兩種:需要合的與不需要合并的,并分別緩存在不同的列表中,無法合并的按照類型分別存放在Batch* mBatchLookup[kOpBatch_Count]中,可以合并的按照類型及MergeID存儲到TinyHashMap<mergeid_t, DrawBatch*> mMergingBatches[kOpBatch_Count]中,示意圖如下:
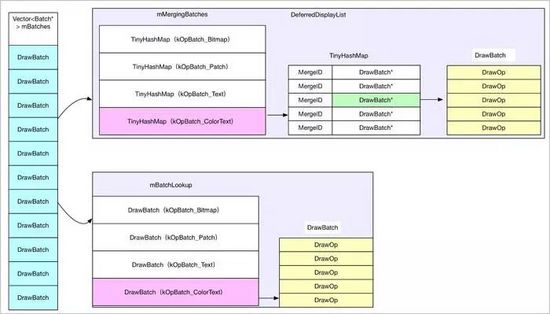
DrawOp合并操作.jpg
合并之后,DeferredDisplayList Vector<Batch> mBatches包含全部整合后的繪制命令,之后渲染即可,需要注意的是這里的合并并不是多個變一個,只是做了一個集合,主要是方便使用各資源紋理等,比如繪制文字的時候,需要根據文字的紋理進行渲染,而這個時候就需要查詢文字的紋理坐標系,合并到一起方便統一處理,一次渲染,減少資源加載的浪費,當然對于理解硬件加速的整體流程,這個合并操作可以完全無視,甚至可以直觀認為,構建完之后,就可以直接渲染,它的主要特點是在另一個Render線程使用OpenGL進行繪制,這個是它最重要的特點*。而mBatches中所有的DrawOp都會通過OpenGL被繪制到GraphicBuffer中,最后通過swapBuffers通知
以上就是Android硬件加速的原理是什么,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





