溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這段時間在看周志華大佬的《機器學習》,在看書的過程中,有時候會搜搜其他人寫的文章,對比來講,周教授講的內容還是比較深刻的,但是前幾天看到SVM這一章的時候,感覺甚是晦澀啊,第一感覺就是比較抽象,特別是對于像本人這種IQ不怎么高的,涉及到高維向量之后,對模型的理解就比較懵了,特別是對于那個幾何距離(或者說是最大間隔),一直是模棱兩可,似懂非懂的感覺,本人也看了其他人寫的SVM的文章,好多都沒用講清楚那個最大間隔模型 d = 1/||w|| 為什么分子是1而不是|f(x)|。苦思冥想之后,給了一個適合自己理解的解釋。
現有n維數據集Dx={x1, x2, x3, ... , xi, ... , xn},其中樣本xi的類別yi∈Y={+1,-1}即數據集為D,且D= {d1, d2, ... ,di , ... ,dm }={(x1,y1), (x2,y2), (x3,y3),... , (xj,yj), (xm,ym)}。其樣本分布如下圖所示:
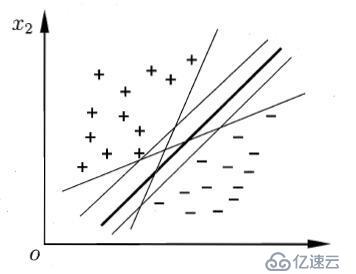
嘗試用一條“直線”(超平面)將這兩類數據點(向量)進行分類,位于使得位于兩側的樣本屬于不同的類。顯然,這樣的直線或者說是超平面有很多,那么應該怎么選取呢,如何定義一個最好的分類超平面呢?
對于最好的超平面,從直覺上最中間的那條粗黑線是最好的,因為它使兩類樣本點都離其最遠,即可以使得分類模型的魯棒性最好,不至于像其他超平面模型,對于樣本的擾動(可理解為“噪聲”)“容忍性”小。顯然對于該“直線”可以用w、b參數進行表示,其中w=(w1, w2, w3, ... , wi, wn).
超平面為:
wx +b = 0
其中x = (xi1; xi2 ;xi3 ; ... ; xij; xim);位列向量,也可以寫成w^T X + b = 0,那么w就是列向量,這里方便公式編輯采用第一種表示,意義一樣。顯然w、b都是未知的參數,聯想到線性規劃并進行推廣,若樣本點(向量)xi滿足wxi+ b > 0 ; 則xi屬于+1類,即yi = +1 ;若wxi+ b < 0 ; 則xi屬于-1類,即yi = -1;定義函數f(xi) = wxi + b ,又定義g(xi,yi)= g(di) = yi * (wxi + b) = yi * f(xi) ,顯然,yi與f(xi)總是同號的,故g(xi,yi) > 0。
言歸正傳,為什么要定義函數f和g呢,因為我們得通過這兩個函數來求得權向量w和閾值b,以確定分類最好的超平面,那么問題又來了,“最優”超平面需滿足什么條件呢,或者說,在滿足什么條件下,這個超平面“最優”?這就轉化為了一個優化問題。剛才討論的時候,我們已經假設了該超平面L:
wx + b = 0 ;那么對于給定的數據集D= {d1, d2, ... ,di , ... ,dn }={(x1,y1), (x2,y2), (x3,y3),... , (xi,yi), (xn,yn)};肯定存在至少一個正樣本點 di = (xi, +1),至少一個負樣本dj = (xj, -1),他,對于它們各自而言,在正樣本中,di是“距離”L最近的樣本點(向量),設最近距離為li同理,在負樣本中,dj是“距離”L最近的樣本點,設最近距離為lj聯想二維空間中點到直線的距離公式,同時對此進行一個推廣,定義一個距離γ = li + lj = (|wxi + b| + |wxj + b| ) / ||w|| ,顯然,只有當γ最大時,L才是我們想要的超平面。即:
max γ
那么問題又來了,單就上述γ定義的形式而言,似乎不怎么好求解最大值,這以上是我自己定義的,在周
的《機器學習》中,直接令:
wxi+ b ≥ 1 (yi = +1)
{
wxi+ b ≤ -1 (yi = -1)
然后,定義距離d = 2/||w||,本人疑惑就來了,為何直接令wxi+ b ≥ 1 (yi = +1) 和 wxi+ b ≤ -1 (yi = -1),就幾何意義,這兩個面與超平面wxi+ b = 0“平行”且“距離”都為1,就這么“霸氣”地令,實在是令我百思不得其解,于是,開始參閱一些其他人寫的博客,有很多人都不理解這個2是如何來的,我也沒有找到讓自己很容易理解的文章,倒是找到了一篇不錯的講SVM的博文(http://www.blogjava.net/zhenandaci/archive/2009/02/13/254519.html),但是也沒有講清楚距離那個d = 2/||w||,只好自己苦想。
我發現,可以這么來解釋,上文中提到的li和lj,對于給定的樣本集,其到超平面的距離di和dj肯定是
定的,即di = wxi +b中,雖然w和b是未知參數,但是di確定,同理dj = wxj + b中,dj確定,不妨設
DiLj = di + dj
則 DiLj亦是確定的,于是乎:
γ = DiLj / ||w||
對于 max γ <=> max (1 / ||w||),這就相當于分別將di = |wxi + b| / ||w|| ,dj = |wxj + b| / ||w|| 進行歸一化得di' = 1 / ||w|| , dj' = 1 / ||w|| ,于是乎:
max 2 / ||w||
s.t. g(di) = g((xi,yi)) ≥ 1 (i = 1, 2, 3, ... , m) ;
其中||w||為范數,一般而言,是指向量長度,w = √w1^2 + w2^2 + ... + wn^2 則上述模型等價于:
min 1/2 * ||w||^2
s.t. g(di) = g((xi,yi)) ≥ 1 (i = 1, 2, 3, ... , m) ;
就好理解了。
位于 wx + b = ±1 上的樣本點(向量)稱為"支持向量",似乎跟該模型更多的利用了“支持向量”???,自己也不是很確定(待續)。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





