溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Mybatis中resultMap如何使用,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
一、字段映射
在Mybatis中,最簡單的結果映射方式,就是通過類型別名typeAliases來處理。
如果要這樣做,那么第一步需要配置實體類包的路徑:
mybatis.type-aliases-package=com.xxx.entity
該路徑下的所有類,就會被注冊到TYPE_ALIASES容器。我們在指定返回值類型的時候,就直接用別名即可。
比如,我們有一個User類:
@Data
public class User {
private String id;
private String username;
private String password;
private String address;
private String email;
}如果數據庫中表的字段與User類的屬性名稱一致,我們就可以使用resultType來返回。
<select id="getUsers" resultType="User"> SELECT u.id, u.username, u.password, u.address, u.email FROM USER u </select>
當然,這是理想狀態下,屬性和字段名都完全一致的情況。但事實上,不一致的情況是有的,這時候我們的resultMap就要登場了。
如果User類保持不變,但SQL語句發生了變化,將id改成了uid。
<select id="getUsers" resultType="User"> SELECT u.id as uid, u.username, u.password, u.address, u.email FROM USER u </select>
那么,在結果集中,我們將會丟失id數據。這時候我們就可以定義一個resultMap,來映射不一樣的字段。
<resultMap id="getUserByIdMap" type="User"> <result property="id" column="uid"></result> </resultMap>
然后,我們把上面的select語句中的resultType修改為resultMap="getUserByIdMap" 。
這里面column對應的是數據庫的列名或別名;property對應的是結果集的字段或屬性。
這就是resultMap最簡單,也最基礎的用法:字段映射。
下面,我們看看其他幾種標簽都是怎么應用的。
| 元素名稱 | 描述 |
|---|---|
| constructor | 用于在實例化類時,注入結果到構造方法中 |
| association | 關聯一個對象 |
| collection | 關聯多個對象 |
二、構造方法
如果你希望將結果注入構造方法里,就可以用到constructor元素。
比如,我們的User類增加了一個構造方法:
public User(String id, String name) {
this.id = id+"--------";
this.username = name+"--------";
}我們需要在resultMap中定義constructor元素:
<resultMap id="getUserByIdMap" type="User"> <constructor> <idArg column="id" name="id" javaType="string"></idArg> <arg column="username" name="name" javaType="string"></arg> </constructor> </resultMap>
其中,column代表數據庫字段名稱或者別名;name則是構造方法中的參數名稱;javaType指定了參數的類型。
如你所想,這樣指定構造方法后,我們結果集中的id和username屬性都會發生變化。
{
"id": "1001--------",
"username": "后羿--------",
"password": "123456",
"address": "北京市海淀區",
"email": "510273027@qq.com"
}三、關聯
在實際的業務中,我們的用戶一般都會有一個角色。那么在User類里面一般也是以一個實體類來表示。
@Data
public class User {
//省略用戶屬性...
//角色信息
private Role role;
}我們在查詢用戶的時候,如果也希望看到它的角色信息,我們會這樣來寫查詢語句:
<select id="getUserById" resultType="User">
SELECT
u.id,
u.username,
u.password,
u.address,
u.email,
r.id as 'role_id',
r.name as 'role_name'
FROM
USER u
LEFT JOIN user_roles ur ON u.id = ur.user_id
LEFT JOIN role r ON r.id = ur.role_id
where u.id=#{id}
</select>如上,就要查詢單個用戶以及用戶的角色信息。不過在這里,我們不能用resultType=User來返回。
畢竟,User類中只有一個Role對象,并沒有role_id和role_name字段屬性。
所以,我們要使用association來關聯它們。
<resultMap id="userMap" type="User"> <id property="id" column="id"></id> <result property="username" column="username"></result> <result property="password" column="password"></result> <result property="address" column="address"></result> <result property="email" column="email"></result> <association property="role" javaType="Role"> <id property="id" column="role_id"></id> <result property="name" column="role_name"></result> </association> </resultMap>
最后我們就可以將角色信息一塊顯示出來:
{
"id": "1001",
"username": "后羿",
"password": "123456",
"address": "北京市海淀區",
"email": "510273027@qq.com",
"role": {
"id": "3",
"name": "射手"
}
}事實上,如果你確定關聯信息是一對一的情況,有個更簡便的方法可以替代association,我們在本文的第五部分-自動填充關聯對象再看它是怎么實現的。
四、集合
1、集合的嵌套結果映射
上面我們看到一個用戶后羿,它的角色是射手;但大部分時候,我們每個人都不可能只擁有一種角色。所以,我們需要將User類中的角色屬性的類型改成List。
@Data
public class User {
//省略用戶屬性...
//角色信息
private List<Role> roles;
}現在就變成了一個用戶對應多個角色,所以就不是簡單的association。
因為association處理的是有一個類型的關聯;而我們這里是有多個類型的關聯,所以就需要用到collection屬性。
我們整體的resultMap會變成下面這樣:
<resultMap id="userMap" type="User"> <id property="id" column="id"></id> <result property="username" column="username"></result> <result property="password" column="password"></result> <result property="address" column="address"></result> <result property="email" column="email"></result> <collection property="roles" ofType="Role"> <id property="id" column="role_id"></id> <result property="name" column="role_name"></result> </collection> </resultMap>
這樣的話,即便你有多個角色也可以被正確顯示:
{
"id": "1003",
"username": "貂蟬",
"password": "123456",
"address": "北京市東城區",
"email": "510273027@qq.com",
"roles": [
{
"id": "1",
"name": "中單"
},
{
"id": "2",
"name": "打野"
}
]
}2、集合的嵌套 Select 查詢
在大部分業務系統中,我們都會有一個菜單的表,比如像下面這樣,一張Menu表:
| id | name | url | parent_id |
|---|---|---|---|
| 1 | 系統管理 | 0 | |
| 1001 | 用戶管理 | /user | 1 |
| 1002 | 角色管理 | /role | 1 |
| 1003 | 單位管理 | /employer | 1 |
| 2 | 平臺監控 | 0 | |
| 2001 | 系統監控 | /system/monitor | 2 |
| 2002 | 數據監控 | /data/monitor | 2 |
這里我們給菜單分為兩級。我們給前端返回菜單的時候,也是需要分級的,不可能將這7條數據平級展示。那么,在這里我們的Menu實體類如下:
@Data
public class Menu {
private String id;
private String name;
private String url;
private String parent_id;
private List<Menu> childMenu;
}一級菜單,包含一個二級菜單的列表,這里用childMenu來表示。
SQL語句中,如果沒有parent_id字段屬性,我們就先查所有的一級菜單:
<select id="getMenus" resultMap="menusMap">
SELECT
m.id,
m.name,
m.url,
m.parent_id
FROM
m_menu m
where 1=1
<choose>
<when test="parent_id!=null">
and m.parent_id = #{parent_id}
</when>
<otherwise>
and m.parent_id = '0'
</otherwise>
</choose>
</select>這個查詢語句,在不傳輸任何參數的情況下,我們會得到兩條一級菜單的數據。
那么在只調用此方法一次的情況下,怎么把所有的菜單信息查詢出來,并按層級展示呢?
我們來看menusMap的定義:
<resultMap id="menusMap" type="Menu">
<id property="id" column="id"></id>
<result property="name" column="name"></result>
<result property="url" column="url"></result>
<result property="m_desc" column="m_desc"></result>
<result property="parent_id" column="parent_id"></result>
<collection property="childMenu" ofType="Menu" select="getMenus" column="{parent_id=id}"></collection>
</resultMap>重點來看collection元素:
property="childMenu" 對應的是菜單中的子級菜單列表;
ofType="Menu" 對應返回數據的類型;
select="getMenus" 指定了SELECT語句的id;
column="{parent_id=id}" 則是參數的表達式。
這個collection整體的含義可以這樣理解:
通過getMenus這個SELECT語句來獲取一級菜單中的childMenu屬性結果;在上面的SELECT語句中,需要傳遞一個parent_id參數;這個參數的值就是一級菜單中的id。
通過這種方式,我們就可以得到已分級的所有菜單信息。
[
{
"id": "1",
"name": "系統管理",
"parent_id": "0",
"childMenu": [
{
"id": "1001",
"name": "用戶管理",
"url": "/user",
"parent_id": "1"
},
{
"id": "1002",
"name": "角色管理",
"url": "/role",
"parent_id": "1"
},
{
"id": "1003",
"name": "單位管理",
"url": "/employer",
"parent_id": "1"
}
]
},
{
"id": "2",
"name": "平臺監控",
"parent_id": "0",
"childMenu": [
{
"id": "2001",
"name": "系統監控",
"url": "/system/monitor",
"parent_id": "2"
},
{
"id": "2002",
"name": "數據監控",
"url": "/data/monitor",
"parent_id": "2"
}
]
}
]五、自動填充關聯對象
我們知道,在Mybatis解析返回值的時候。
第一步是獲取返回值類型,拿到Class對象,然后獲取構造器,設置可訪問并返回實例,然后又把它包裝成MetaObject對象。
從數據庫rs中拿到結果之后,會調用MetaObject.setValue(String name, Object value) 來填充對象。
在這過程中,有趣的是,它會以.來分隔這個name屬性。
如果name屬性中包含.符號,就找到.符號之前的屬性名稱,把它當做一個實體對象來處理。
可能筆者在這里描述的不夠直觀,我們還是來看例子。
在本文第三部分中,我們有一個用戶對應一個角色的例子。
其中,User類定義如下:
@Data
public class User {
//省略用戶屬性...
//角色信息
private Role role;
}在這里,我們無需定義resultMap,直接返回resultType=User即可。不過需要把role信息的別名修改一下,重點是.符號
<select id="getUserList" resultType="User"> SELECT u.id, u.username, u.password, u.address, u.email, r.id as 'role.id', r.name as 'role.name' FROM USER u LEFT JOIN user_roles ur ON u.id = ur.user_id LEFT JOIN role r ON r.id = ur.role_id </select>
這樣,在Mybatis解析到role.id屬性的時候,以.符號分隔之后發現,role別名對應的是Role對象,則會先初始化Role對象,并將值賦予id屬性。
相關代碼如圖:
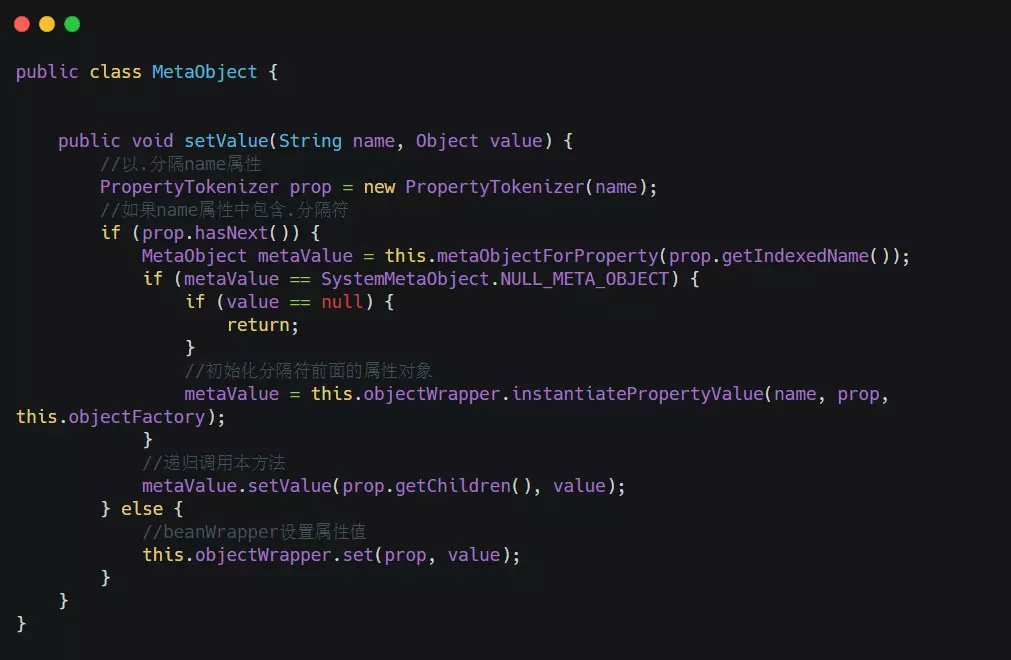
看完上述內容,你們掌握Mybatis中resultMap如何使用的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





