溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
很高興今天給大家介紹微軟2016群集的VM彈性和存儲容錯技術,在老王看來,WSFC 2016里面針對于群集運作,VM彈性是一項很重要的改變,和滾動升級一樣,是一種顛覆式的思維。
簡單來說,在大家的認知里,群集就是應該當檢測到節點不可用之后,快速進行failover,把應用繼續轉移到其它節點上運行,對吧,相信大家都認同這一點。
2012R2里面默認相同子網和跨子網都是每隔一秒全網檢測一次,五次檢測失效,即判定該節點不可用,RCM開始根據群集數據庫內容,故障轉移角色到其它節點運作,檢測時間和檢測失敗次數操作,可以改,如果您的環境存在網絡不穩定的情況,嚴格的監測會導致節點頻繁故障轉移,您也改成松散一些的1秒檢測一次,20次檢測失敗,再執行故障轉移
但是這個閥值不易修改太久,原因,一個是因為這個值是針對整個群集級別,如果群集上面有很多應用則所有應用都將受到這個影響,其二是如果檢測次數時間過長,會導致宕機時間很久才被發現,因此2012R2及之前,微軟建議,最長設置為20次檢測失敗就故障轉移,不建議超過這個數值
但歸根到底,我們修改監測閥值,還是為了解決網絡不穩定的問題,以及用戶特定的需求,例如,如果客戶網絡不穩定,檢測會存在瞬時中斷,而且也沒辦法更改,那么就可以把監測閥值設置寬松一些,如果客戶環境網絡很穩定,需要很嚴格的檢測來保證SLA,也可以把檢測閥值設置嚴格一些。
這是2012R2時代的解決方案,到了2016,微軟認為,真正的故障轉移情況已經并不多見,反而是瞬時故障的情況更常見,例如節點短暫無法進行網絡通信,或短暫無法和存儲連接,之后又立刻恢復了,因此微軟重新設計了群集中VM故障轉移策略,能夠讓一定時間內的節點瞬時故障,不必再觸發節點虛擬機的故障轉移。
在WSFC 2016中,VM彈×××默認被啟用,在2016 TP1中這項功能默認被禁用,隨后的版本都默認啟用,運行Get-Cluster |fl * 可以看到和VM彈性相關的配置

參數說明
ResiliencyLevel : IsolateOnSpecialHeartbeat或1,AlwaysIsolate或2,默認為AlwaysIsolate,即在發生節點瞬時中斷后,在一段時間內可以允許虛擬機在線或暫停狀態,IsolateOnSpecialHeartbeat即當檢測到瞬時中斷后,立刻置節點為失敗狀態,執行failover
之前我們說過2016里面重構了VM故障轉移策略
到底是怎么重構的呢
在WSFC 2016里面,假設你發生了瞬時中斷,例如
網絡短暫不穩定,節點無法和其它節點通訊
群集服務崩潰,無法與其他節點連接
管理員誤操作
當發生例如這種瞬時中斷,群集現在新增了三個屬性
隔離:針對于群集節點,在規定時間內,群集節點發生瞬時中斷后,狀態會被標記為隔離,該成員不會再是合格的群集成員,但上面托管的虛擬機,在一定時間內依然可以正常運行
未監視:針對于群集管理器中看虛擬機狀態,如果當節點發生瞬時中斷,變成隔離狀態后,在群集里面看虛擬機,虛擬機會是未監視狀態
如果虛擬機存儲在SMB3/SOFS路徑下,節點隔離狀態后虛擬機可以使用Online狀態運行,因為SMB可獨立運行,如果虛擬機存儲在FC/FCoE/iSCSI/ShareSAS等塊存儲構成的CSV路徑下,那么虛擬機會被置為暫停狀態,因為節點被隔離后,不是合格的群集成員,也將失去CSV的訪問資格,如果節點恢復正常,虛擬機會從暫停狀態中恢復正常運行,如果節點的瞬時中斷一段時間內未恢復,虛擬機將會被failover到其它節點運作。
3. 檢疫持續:我們會設定一個時間,在這個時間內,節點如果發生瞬時中斷后又恢復了,虛擬機不會被遷移,只是繼續運行,但如果節點在一小時內,被隔離達到一定次數,多次發生瞬時中斷,則我們判定該節點當前不正常,該節點可能會導致應用不穩定,因此我們會把該節點置為檢疫狀態,置為檢疫狀態的節點,在一段時間內該節點將處于檢疫狀態,上面所有的虛擬機會被實時遷移走,直到我們分析判斷該節點恢復正常后,再重新加入群集。
ResiliencyPeriod:配置節點在隔離狀態下運作的時間,默認為240秒,即240秒內的瞬時中斷,可以被接受,不需要發生故障轉移,如果超過240秒仍未恢復,則按照群集檢測走,執行故障轉移操作。
#配置隔離狀態時間
(Get-Cluster).ResiliencyDefaultPeriod = 60

#關閉隔離狀態功能
(Get-Cluster).ResiliencyDefaultPeriod =0
#配置單個虛擬機級別隔離狀態時間(即未監視狀態時間)
(Get-ClusterGroup“stat”).ResiliencyPeriod = 60
QuarantineThreshold:節點進入檢疫狀態前的隔離次數,默認為3,即節點一小時內被置為3次隔離狀態后,則節點進入檢疫狀態,所有虛擬機會被實時遷移走
#配置進入檢疫狀態前的隔離次數
(Get-Cluster).QuarantineThreshold =<value>
QuarantineDuration:節點處在檢疫狀態下的時間,默認為7200秒,在這段時間,節點將不承載應用,所有虛擬機被實時遷移走,管理員可以排查頻繁導致瞬時終端的問題,如果修復好了后可以手動讓節點提前恢復,或等到7200秒自動恢復。
#配置檢疫狀態時間
(Get-Cluster).QuarantineDuration = <value>
這項技術說太多可能會覺得枯燥,下面我們實際來看一下案例
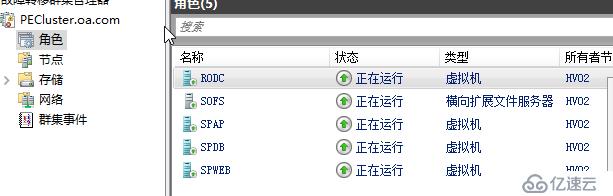
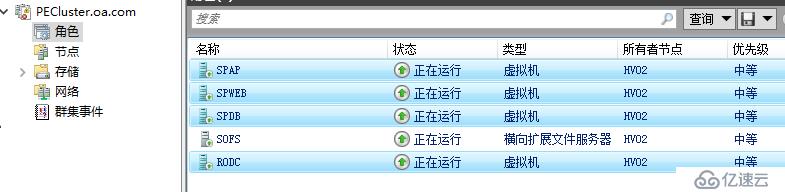
當前環境里面四臺虛擬機,其中RODC運作在SOFS路徑,其它三臺虛擬機運作在通過ISCSI提供的CSV路徑下,我設置節點隔離狀態時間為60秒,檢疫狀態時間為600秒,這里老王只是為了測試快點看到結果,真實環境下建議根據實際時間評估,多長時間內可以算作瞬時中斷,頻繁發生瞬時中斷我需要多長時間進行排查問題節點。
WSFC 2016中要實現VM彈性的功能要求
群集功能級別為9
虛擬機配置級別升級至少6x以上
在老王的實驗中,我將模擬一個群集服務短暫崩潰的場景,模擬群集服務強制停止后,觀察群集的反應
當前群集四臺虛擬機都承載在HV01

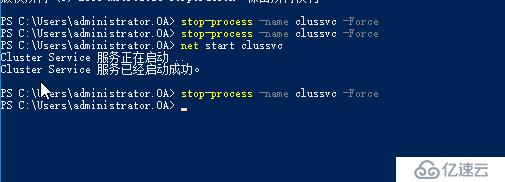
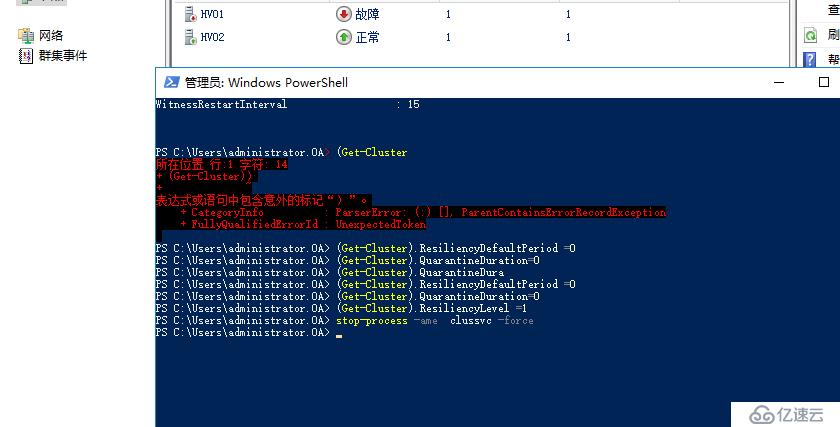
我們通過強制停止節點上面的clussvc進程來模擬群集服務崩潰
Stop-process -name clussvc -Force

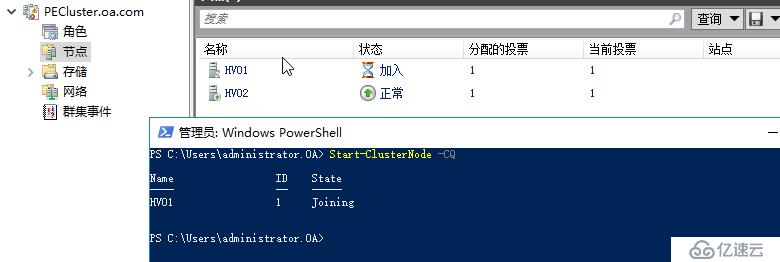
可以看到,群集服務崩潰后,節點會被置為隔離狀態

所有虛擬機在群集里面看會是未被監視狀態,這只是個群集管理器中看到的臨時狀態
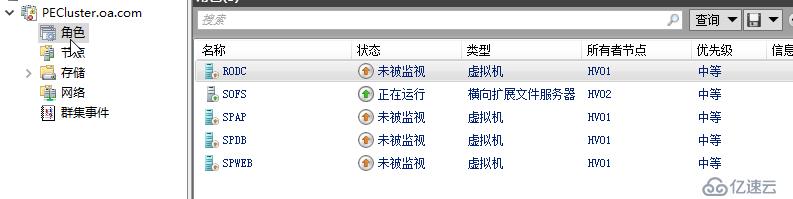
但其實在Hyper-V可以看到,實質上,存放在SOFS的RODC在60秒內會持續運行,運行在CSV上的其他虛擬機,雖然顯示 正在運行-關鍵,這個中文顯示是錯的,英文上面顯示為Paused-Critical,實質上它們是因為節點被隔離,失去到CSV的資格,而被置為暫停狀態。
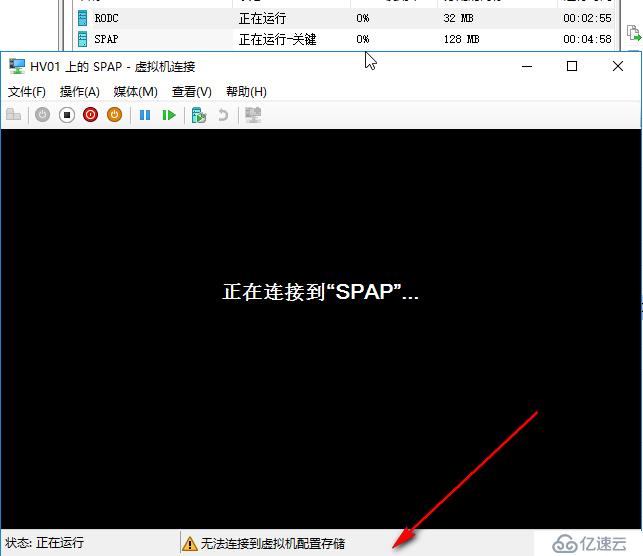
如果60秒內,節點又恢復正常了,瞬時中斷恢復,網絡恢復正常,服務不再崩潰,管理員恢復了誤操作,則節點重新加入回到正常狀態,已被暫停的虛擬機會重新開始運行,本例中我們強制終止clussvc進程后,稍后會自動啟動起來

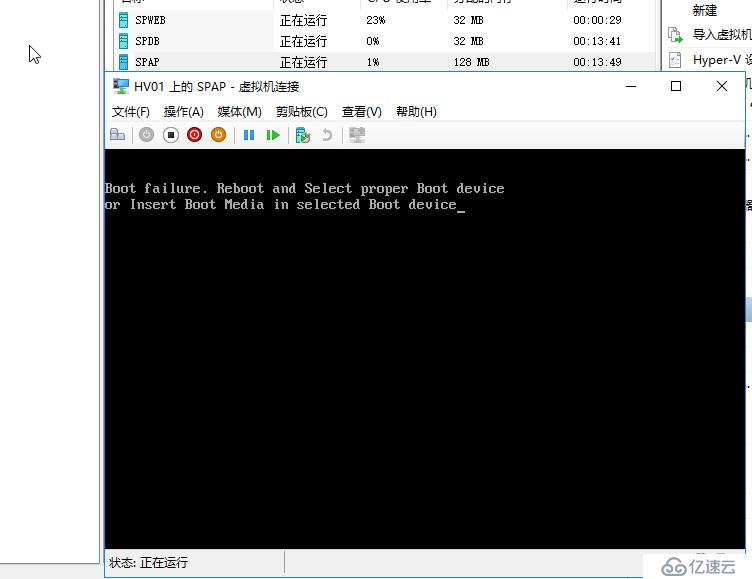
如果60秒內,瞬時中斷,或是群集服務崩潰,或是網絡臨時中斷,或是管理員誤操作,沒有得到修復,則節點會被置為Down狀態,所有被置為未被監視狀態的虛擬機會被遷移到其它活著的節點上,遷移過程是快速遷移,針對暫停的虛擬機會置為關機狀態再遷移走。
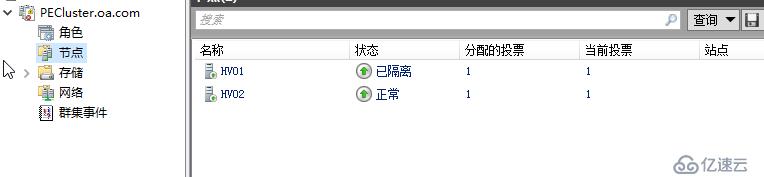
下面我們模擬1小時內3次隔離的情況發生,即同一節點三小時內發生瞬時中斷
可以看到,在節點的地方查看發現已經從紅隔離變成了綠隔離,但其實這個綠色的已隔離和上面紅色的已隔離已經不是同一個意思,一個是Isolate,一個是Quarantine,進入綠隔離狀態其實應該是我們說的檢疫狀態,即根據我們定義的算法,群集已經可以判斷這個節點不正常了,它生病了,不應該再繼續承載虛擬機,因此上面所有的虛擬機都會被實時遷移至其它節點,并在QuarantineDuration時間內,節點都將處于檢疫狀態,這時候管理員可以對節點進行錯誤診斷,確認頻繁發生瞬時中斷,是否意味著有真實的問題存在需要處理,
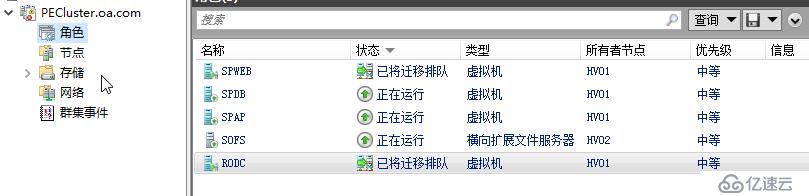
如果600秒時間到了,則群集認為您已經解決了該問題,自動解除檢疫狀態,放節點正常加入群集,如果您不想等待這個時間,或者您在已經提前解決了頻繁瞬時中斷的問題,那么您也可以運行命令 Start-ClusterNode -CQ 執行ClearQuarantine操作,把節點手動恢復正常
相信通過以上實驗大家對于VM彈×××已經有了一定了解了
有了這項技術后,我們可以讓群集保持以前的樣子,根據檢測信號完成快速的故障轉移,也可以根據通過VM彈性技術,設置在一定瞬時中斷時間內,接受短暫的中斷又恢復,不需要立刻執行故障轉移,可以分別把主機在瞬時中斷下做隔離處理,甚至進一步檢疫處理,相對來說更加正規一些,也比原來我們調整檢測信號的方式來的效果更好,因此如果大家環境中有瞬時中斷的情況,不妨了解使用下這項功能。
如果不想要VM彈×××,還想恢復以前基于信號檢測直接做故障轉移的運作方式
設置VM彈性值如下,則回到從前,需要注意,在2016TP2之后的版本,這項功能默認被啟用,因此當發生網絡中斷,服務崩潰如果發現應用沒快速故障轉移,不要驚慌,那么是因為群集自動開啟了VM彈×××,不想要它,直接這樣disable掉即可

關閉VM彈性后,再次強制停止clussvc進程,發現節點直接進入故障狀態,執行故障轉移
以上為VM彈×××,可以幫助我們解決節點級別的網絡,系統,誤操作等瞬時故障,除了計算級別可以有這種彈×××,2016還在虛擬機存儲中也添加了這項技術,主要針對于虛擬機訪問VHDX,在2012R2中,如果虛擬機忽然訪問不到VHDX,虛擬機肯定會崩潰無法使用,當存儲再次可用,我們可能也需要重新打開虛擬機。
在WSFC 2016中群集虛擬機可以和存儲實現更好的容錯功能,非常的神奇,我們可以設置一個允許中斷時間,在這段時間內,如果群集虛擬機到存儲之間發生了瞬時故障,無法訪問VHDX了,可以把虛擬機置為暫停關鍵狀態,虛擬機將被凍結,狀態得到保存,所有虛擬機的IO也都會被凍結
當VHDX恢復訪問后,虛擬機從暫停狀態回到正常運行,狀態釋放,所有IO得到正常運轉,通過這樣內置的存儲容錯功能,可以幫助我們在存儲短暫連接失效的時候提供一種很好的方案,當存儲再次可用時,虛擬機自動load io,對于用戶來說,停機時間得到改善。
當前除了RODC虛擬機,其它虛擬機都是直接連接到的CSV,我們直接在ISCSI上面禁用掉16群集用的數據磁盤,這樣CSV也就是失敗,節點到存儲失敗,VHDX也再也不可讀取
可以看到虛擬機又被置為正在運行-關鍵,但其實這個狀態應該是Paused-Critical
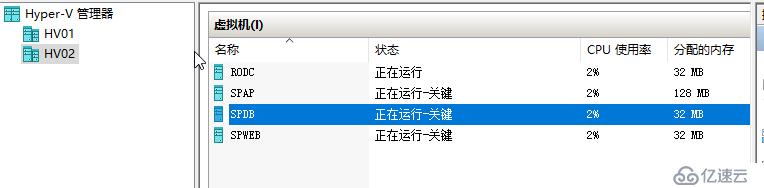
那么這個凍結虛擬機IO的時間是有限的,默認是30分鐘,不可以太長,不可以是無限期的,在一段時間內,如果虛擬機仍然無法連接到VHDX,則VM將會關閉,下次啟動將是冷啟動
30分鐘之內如果虛擬機恢復到存儲的連接,則繼續運作,虛擬機被置為正在運行,繼續保留之前的工作狀態,所有操作和IO正常運轉,如果這個到存儲的故障很短,那么對于用戶來說是感受不到的,一旦存儲連接上后,虛擬機會很快恢復運轉,SOFS虛擬機最快,其次是CSV虛擬機,開掛的ShareVHDX虛擬機會直接執行實時遷移。
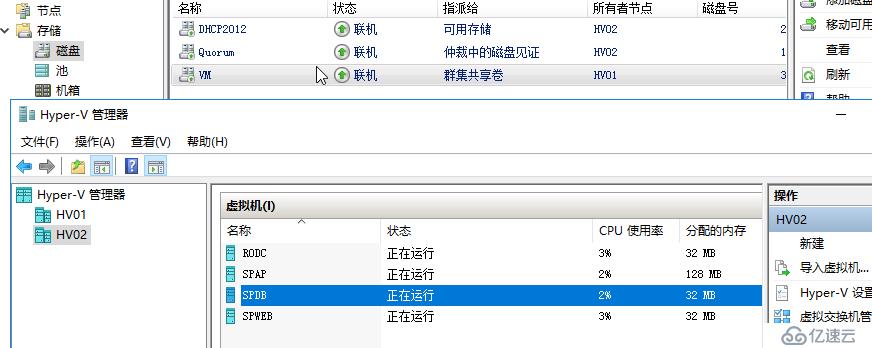
#配置虛擬機存儲容錯,HV級別配置虛擬機
開啟虛擬機容錯功能
Set-VM -AutomaticCriticalErrorAction <None | Pause>
默認為Pause,即存儲無法連接時暫停,改成None則回到以前狀態,如果要修改需關閉虛擬機!
配置虛擬機存儲無法連接等待時間 默認30分鐘
Set-VM –AutomaticCriticalErrorActionTimeout <value in minutes>
針對于ShareVhdx虛擬機在Hyper-V 2016會每隔十分鐘輪詢一次,存儲是否可用,如果不可用則自動實時遷移到其它節點上。
VM存儲容錯功能,僅支持基于CSV的VHD,VHDX檢測,或sharevhdx,sofs
不支持為群集化的本地VHD VHDX
不支持使用直通磁盤,或USB存儲的虛擬機
以上,老王為大家介紹了VM彈性和存儲容錯的功能,關注這項技術很久了,一直很想把這項技術介紹給國內的朋友,這次終于寫好了,希望能夠為看到的朋友帶來收獲,如果您的環境中存在節點,網絡,存儲的瞬時故障,現在您可以通過2016中的VM彈性技術進行控制,尤其是針對于存儲的神奇容錯功能。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





