溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
前面兩篇文章中,老王和大家介紹了存儲復制的功能,在單機對單機,以及延伸群集的實踐,基本上大家可以看出,這是一種基于塊級別的存儲復制,原生內置于Windows Server 2016上面,可以幫助我們實現在單機對單機場景下的災備,也可以結合群集,實現存儲和應用結合,當發生站點級別災難的時候,自動轉移存儲和應用
對于工程師來說,現在架構上又多了一個新的選擇,我們可以不借助設備,不借助第三方產品,就使用微軟原生的OS實現高可用+災難恢復
雖然說延伸群集很好,但是仍有一個弊端,即不能直接使用各節點本地磁盤完成存儲復制,各站點節點還必須接入自己站點的存儲,兩個站點需以非對稱共享存儲的方式來完成復制,老王猜想微軟的本意,就是希望把延伸群集這項功能用于異地站點不同共享存儲,例如北京站點各節點接入北京站點的存儲,天津站點各節點接入天津站點的存儲,然后呢,在兩個Site之間做存儲復制,以實現延伸群集的效果,即便是本地站點存儲和計算節點全部崩潰,另外一個站點也可以使用
不過老王猜想應該還是群集機制的原因,導致目前延伸群集還不能使用各節點本地磁盤,因為微軟群集設計之初就是要求實現群集存儲永久保留,群集數據存放共享存儲,以便切換直接掛載,如果直接本地磁盤進入群集磁盤,故障切換上會有一些問題
雖然說微軟2016有了S2D技術,可以實現超融合存儲,但是它本質上功能和我們講的災難恢復還是有一些區別,S2D老王認為是存儲+群集結合起來的一項技術,我們在群集上面啟用S2D,之后通過一個存儲匯流排把各個節點的磁盤匯集在一起,但是注意,這里并不是說各節點的本地磁盤直接就進到群集磁盤,而是在群集存儲里面機箱的區域可以看到所有節點的可用磁盤,我們開啟S2D后,可以相當于我們邏輯的構建了一個存儲機柜,這個存儲機柜里面的存儲是來自各個節點的磁盤,接下來要怎么用呢,我們還需要在這個邏輯的存儲機柜上面劃分Lun給各個節點接入,所以我們創建存儲池,虛擬磁盤,實現容錯,分層,緩存,最終交付到群集上面是虛擬磁盤,虛擬磁盤就可以被認作是一個群集磁盤,但是事實上只會顯示一個群集磁盤,即便這個虛擬磁盤是通過邏輯存儲機柜,多個節點創建出來的。
所以,在老王看來,S2D是借助于群集,實現了一個邏輯存儲機柜,然后分配存儲給群集應用使用,所以這個概念大家可以看到,和我們的存儲復制還是有一些出入,相對來看,似乎業界都是通過S2D這樣的超融合架構來實現延伸群集
直接底層S2D邏輯存儲機柜的層面做好站點感知,然后分配給群集,存儲在底層已經做好了容錯,微軟為什么沒有實現這種架構,老王猜想應該是優化和機制的問題
1.當前S2D只能做到機架感知和機箱感知,不能做到站點感知,即沒辦法控制數據撒到不同站點
2.S2D對于網絡性能要求太高,不適用于延伸群集場景
也maybe,過幾個版本微軟會針對于S2D做站點感知的優化,到時我們就可以實現超融合延伸群集,或者災難恢復延伸群集
就目前的情況來看,我們只能通過災難恢復來實現延伸群集的效果,那么很多朋友可能會問,為什么延伸群集不能和S2D相結合一起來用
首先老王認為在微軟生態環境中這是兩個解決不同場景的方案
延伸群集,是為了處理跨站點群集,存儲的災難恢復,為兩個站點的存儲實現復制,確保可以接受站點級別的災難
S2D, 是為了處理存儲設備昂貴,通過本地磁盤實現群集存儲,通過操作系統軟件實現存儲設備的管理功能
如果我們使用S2D,在同一個群集內并不會顯示兩套存儲,僅會顯示一套存儲,因為S2D是在底層實現的存儲容錯
而延伸群集需要兩套存儲,以實現不同站點的存儲復制
所以根據目前這個定位來看,老王認為延伸群集不會和S2D有什么契合點,除非后面的版本有大變化
廢棄當前通過存儲復制機制實現的延伸群集,優化S2D站點感知,實現延伸群集
優化S2D站點感知,實現兩種延伸群集模型
S2D架構開通一個click鍵,是否要實現延伸群集,如果是,則不通過底層容錯,而提供兩套存儲,實現存儲復制
就老王來看,我認為1和3的幾率都不大,2的幾率大一些,反正現在網絡也不是瓶頸,如果企業有錢,當然可以選擇用S2D實現延伸群集
事實上老王覺得目前這個存儲復制實現的延伸群集效果也挺好的,對于企業沒有高級存儲設備,但是又想實現跨站點的災備,通過存儲復制+群集,可以實現很低的RTO和RPO,災難切換的時候實現完全自動化,這更是一大優勢
那么這是對于延伸群集中存儲復制,S2D的一些探討,對于Windows Server 2016的存儲復制來說,我們還有另外一種場景,跨群集復制,將存儲復制擴展至群集邊界外
在這種場景中,我們就可以把S2D方案和存儲復制方案相結合
前文我們提到過,存儲復制解決方案對于存儲沒有要求,底層可以是本地SCSI/SATA,ISCSI,Share SAS ,SAN,SDS,對于延伸群集來說,可能是需要非對稱共享存儲的架構,要是ISCSI,SAN,JBOD等架構,但是對于單機對單機或者群集對群集來說,就沒有這么多說法了,我們可以使用本地磁盤和SDS架構,在單機對單機的架構中,就相當于是,我給你系統OS提供一個存儲,你別管我是怎么來的,只要兩邊大小一致符合要求就可以建立存儲復制,群集對群集也基本上差不多,可以把一個群集看成一個大主機,兩個群集就是兩個大主機,你別管我這個群集的存儲怎么來的,總之我群集有符合要求的存儲,只要兩個群集的存儲配置都符合要求,就可以進行群集對群集的復制
這就有很多場景可以玩啦
例如:北京站點群集存儲架構是ISCSI,天津站點群集存儲架構是S2D,然后針對于兩個群集做存儲復制,一旦ISCSI主存儲無法正常提供服務,立刻切換至天津站的提供服務,或者北京站點采用物理機部署,天津站點采用虛擬機部署,北京站點使用私有云部署群集,然后再在公有云部署群集,本地群集和存儲宕機,公有云里面的群集和存儲可以啟動起來
群集對群集復制的好處
1.不用額外配置站點感知,如果北京群集都在北京站點,只會是群集內故障轉移
2.兩個站點的存儲底層架構可以不一樣,避免單一類型存儲都出現故障
3.支持同步復制與異步復制
4.支持更復雜的架構,例如華北群集和華南群集,華北群集由北京節點和天津節點構成,華南群集由廣東和深圳節點構成,各站點內部分別配置站點故障感知,北京節點壞了或者天津節點壞了無關緊要,應用會漂移至同群集的相近站點,如果整個華北地區群集全部宕機,還可以再華南群集重新啟動群集角色
5.幫助實現群集級別的容災,例如如果北京群集配置出現故障,不會影響到天津群集,天津群集可以利用復制過來的存儲啟動群集角色
6.兩個站點可以使用不同的網絡架構,以實現子網的容錯
群集對群集復制的壞處
1.需要手動使用命令進行故障轉移,無圖形化界面操作
2.故障轉移時,需事先在備群集準備好群集角色,然后重新掛載上存儲
3.針對于文件服務器,跨群集故障轉移后需使用新名稱訪問
跨群集復制技術部署需求
各復制節點操作系統需要是Windows Server 2016數據中心版
至少有四臺服務器(兩個群集中各兩臺服務器),支持最多 2 個 64 節點群集
兩組共享存儲, SAS JBOD、SAN、Share VHDX、S2D或 iSCSI,每個存儲組設置為僅對每個群集可用
復制節點需安裝File Server角色,存儲副本功能,故障轉移群集功能
Active Directory域環境,提供復制過程各節點的Kerberos驗證
每個復制群集至少需要兩個磁盤,一個數據磁盤,一個日志磁盤
數據磁盤和日志磁盤的格式必須為GPT,不支持MBR格式磁盤
兩個群集數據磁盤大小與分區大小必須相同,最大 10TB
兩個群集日志磁盤大小與分區大小必須相同,最少 8GB
需要為各群集內需要被復制的磁盤分配CSV或文件服務器角色
存儲復制使用445端口(SMB - 復制傳輸協議),5895端口(WSManHTTP - WMI / CIM / PowerShell的管理協議),5445端口(iWARP SMB - 僅在使用iWARP RDMA網絡時需要)
跨群集復制規劃建議
建議為日志磁盤使用SSD,或NVME SSD,存儲復制首先寫入數據至日志磁盤,良好的日志磁盤性能可以幫助提高寫入效率
建議規劃較大的日志空間,較大的日志允許從較大的中斷中恢復速度更快,但會消耗空間成本。
為同步復制場景準備可靠高速的網絡帶寬,建議1Gbps起步,最好10Gbps,同步復制場景,如果帶寬不足,將延遲應用程序的寫入請求時間
針對于跨云,跨國,或者遠距離的跨群集復制,建議使用異步復制
跨群集復制可以整合的其它微軟技術
部署:Nano Server , SCVMM
管理:PS,Azure ASR,WMI,Honolulu,SCOM,OMS,Azure Stack
整合:Hyper-V,Storage Spaces Direct ,Scale-Out File Server,SMB Multichannel,SMB Direct,重復資料刪除,ReFS,NTFS
微軟跨群集復制場景實作
本例模擬兩座異地群集相互復制,北京站點兩個節點,天津站點兩個節點,北京站點有一臺DC,也承載ISCSI服務器角色,北京站點群集使用ISCSI存儲架構,天津站點兩個節點,使用S2D架構,分別模擬節點宕機,站點宕機,站點恢復后反向復制。
AD&北京ISCSI
Lan:10.0.0.2 255.0.0.0
ISCSI:30.0.0.2 255.0.0.0
16Server1
MGMT: 10.0.0.3 255.0.0.0 DNS 10.0.0.2
ISCSI:30.0.0.3 255.0.0.0
Heart:18.0.0.3 255.0.0.0
16Server2
MGMT: 10.0.0.4 255.0.0.0 DNS 10.0.0.100
ISCSI:30.0.0.4 255.0.0.0
Heart:18.0.0.4 255.0.0.0
天津站點
16Server3
MGMT: 10.0.0.5 255.0.0.0 DNS 10.0.0.2
S2D:30.0.0.5 255.0.0.0
Heart:19.0.0.5 255.0.0.0
16Server4
MGMT: 10.0.0.6 255.0.0.0 DNS 10.0.0.2
S2D:30.0.0.6 255.0.0.0
Heart:19.0.0.6 255.0.0.0
由于我們采用群集對群集架構,因此網絡上面也更加靈活,例如,心跳網絡不必都在同一個網段內,因為心跳網絡是群集級別,跨群集了之后即便你在一個網段,另外的群集也不知道,管理網絡也可以使用不同的子網,例如如果不做多個復制組,不做多活的話,那么天津的對外網絡可以設置在一個安全的網段下,正常不對外提供服務,再通過網絡策略限制存儲復制流量從ISCSI卡到S2D卡,這樣只需要打通兩個群集的存儲流量即可,天津如果有DC,則最好群集可以使用天津站點DC。當災難發生時,再把北京的網絡和天津的管理網絡打通,讓北京用戶訪問天津的角色
操作流程
1.北京站點接入存儲
2.北京站點創建群集
3.北京站點創建群集角色
4.天津站點接入存儲
5.天津站點創建群集
6.天津站點開啟S2D
7.天津站點創建群集角色
8.分配互相群集權限
9.創建存儲復制
10.站點災難恢復
北京站點接入存儲
16server1
16server2
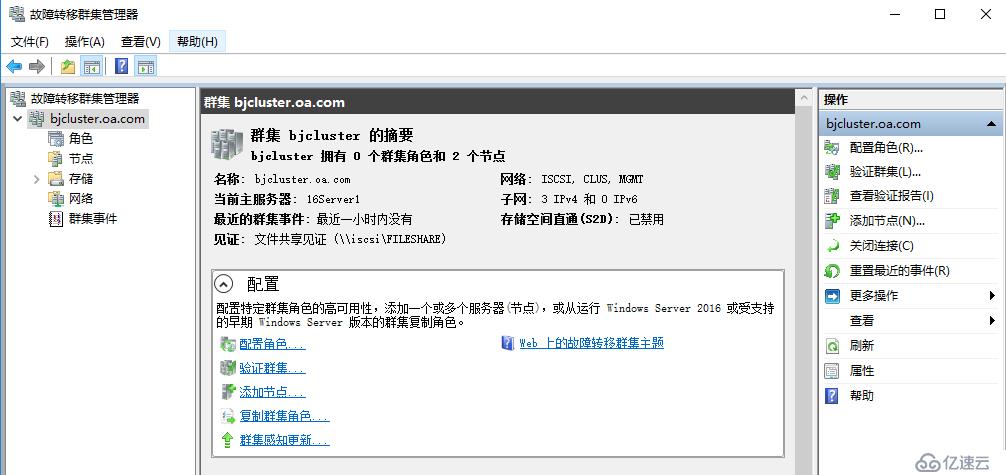
北京站點創建群集,配置群集仲裁為文件共享見證或云見證
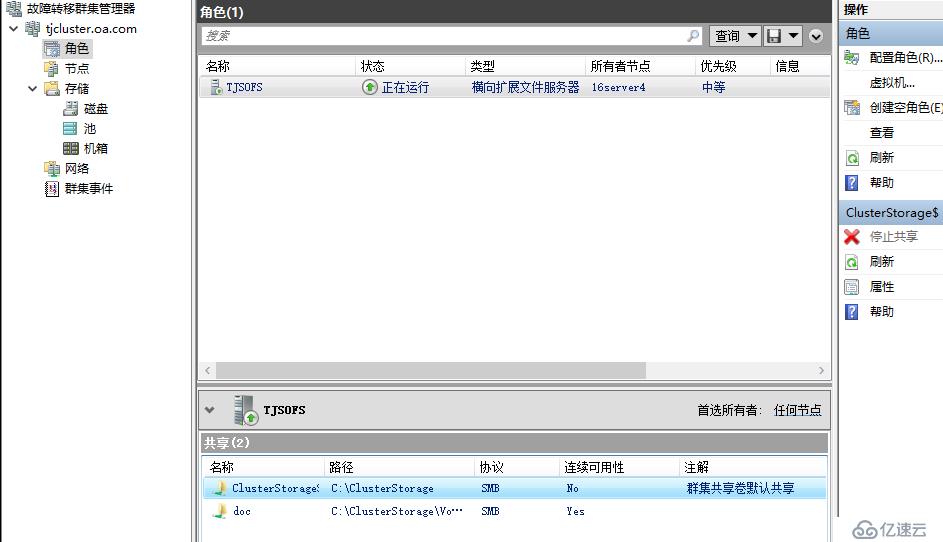
北京站點創建文件服務器群集角色
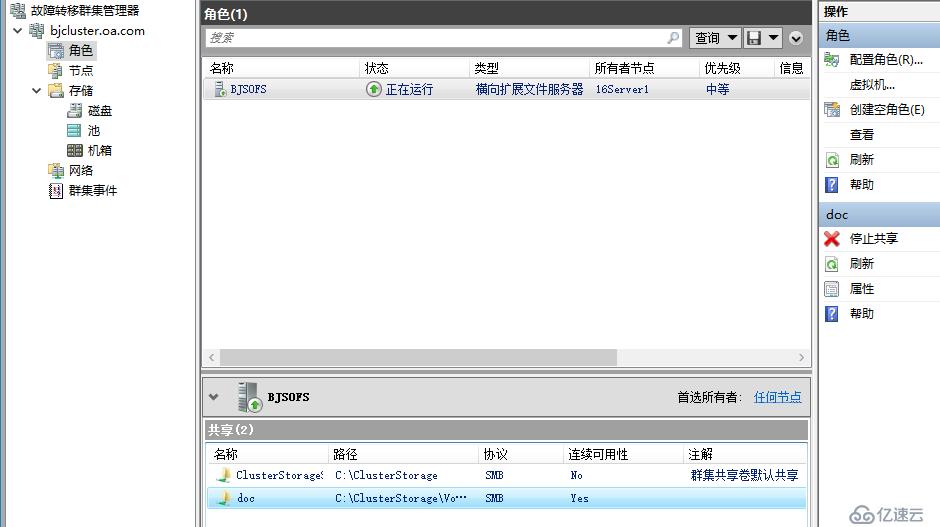
可以看到,老王這里創建的群集角色是SOFS,這是跨群集復制和延伸群集的不同點,延伸群集的時候微軟說明負載只是CSV和傳統高可用文件服務器角色,但是在跨群集復制時場景又變成了可以支持SOFS,我們都知道SOFS主要強調的是文件服務器雙活以及透明故障轉移,由于在延伸群集中故障轉移需要先存儲切換再轉移角色,因此很難實現透明故障轉移,在跨群集復制時,可能由于是兩個群集,所以每個群集內部可以部署SOFS,實現群集內部的透明故障轉移,至于站點故障,則沒辦法完全透明
天津各節點接入本地存儲,大小隨意,最后我們在群集存儲空間上面會重新創建群集磁盤
16server3
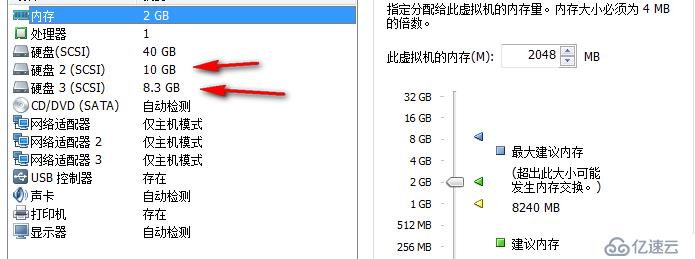
16server4
拿到存儲后,各節點把磁盤聯機,初始化為GPT磁盤即可,不要直接對磁盤進行分區操作,我們需要再通過S2D包上一層才能交付給群集
天津站點創建S2D群集
New-Cluster -Name TJCluster -Node 16Server3,16Server4 -StaticAddress 10.0.0.20 –NoStorage
注:執行前確保節點已符合S2D需求,生產環境建議執行群集驗證


開啟群集S2D功能
Enable-ClusterS2D -CacheState disabled -Autoconfig 0 -SkipEligibilityChecks
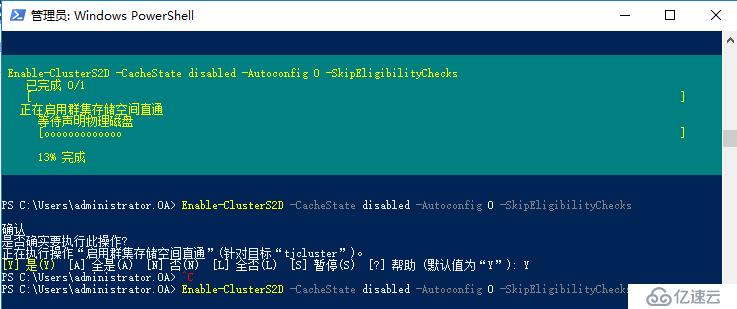
如果你是在vmware workstation上面模擬這個實驗,你會發現開啟S2D的過程會始終卡在這里,沒辦法進行下去,查看日志發現S2D一直沒辦法識別磁盤
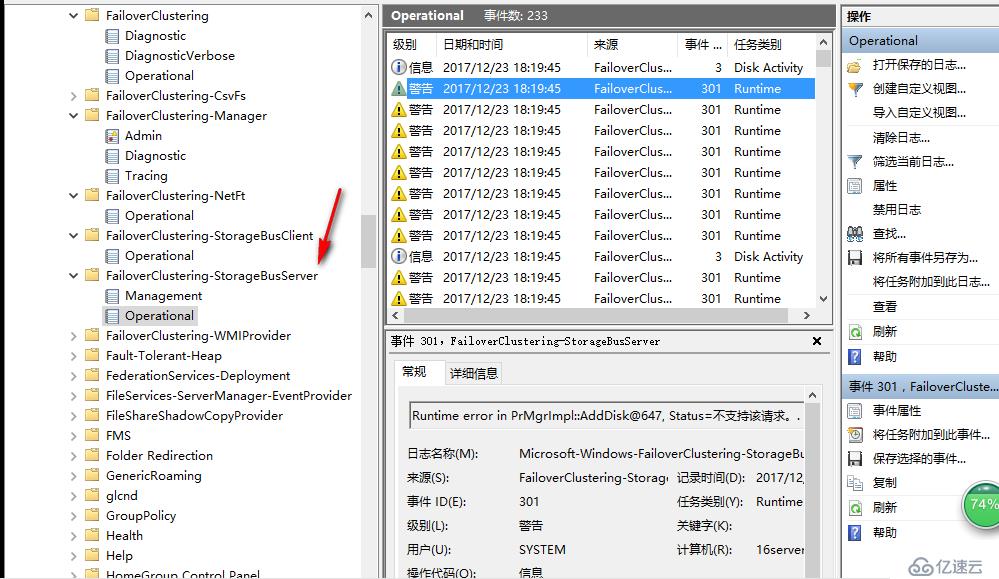
但是到底是什么原因識別不了磁盤呢,vmware虛擬上來的磁盤是SAS總線的,也符合S2D的需求,經過一番研究后,老王找到了原因,原來通過vmware虛擬出來的虛擬機沒有Serial Number,而開啟S2D會去找磁盤的這個數字,找不到,所以磁盤沒辦法被聲明為S2D可用

通過在vmware虛擬機vmx配置文件關機添加參數即可
disk.EnableUUID="true"
添加完成后開機可以看到Serial Number已經可以正常顯示

配置各節點磁盤MediaType標簽
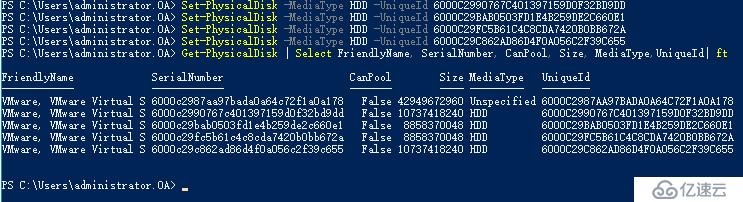
再次開啟S2D,順利通過,現在我們可以在vmware workstation上面模擬S2D實驗!
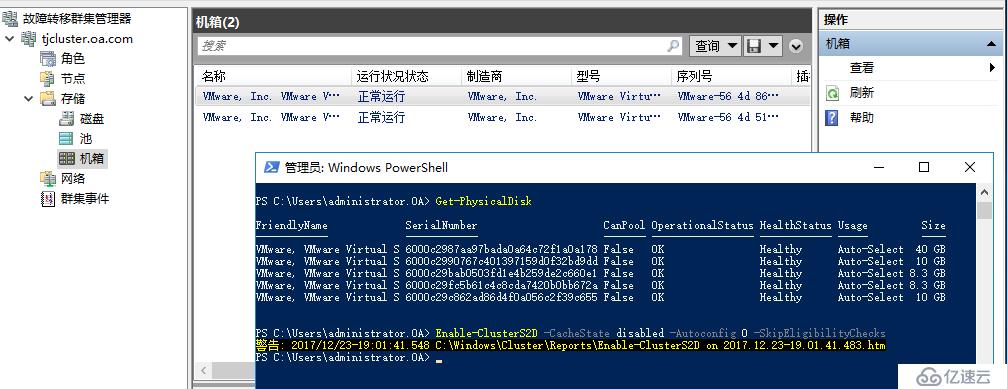
創建群集存儲池
新建虛擬磁盤(存儲空間),這里的虛擬磁盤交付出來就是群集磁盤,所以我們要和北京群集的群集磁盤大小確保一致,以便實現存儲復制
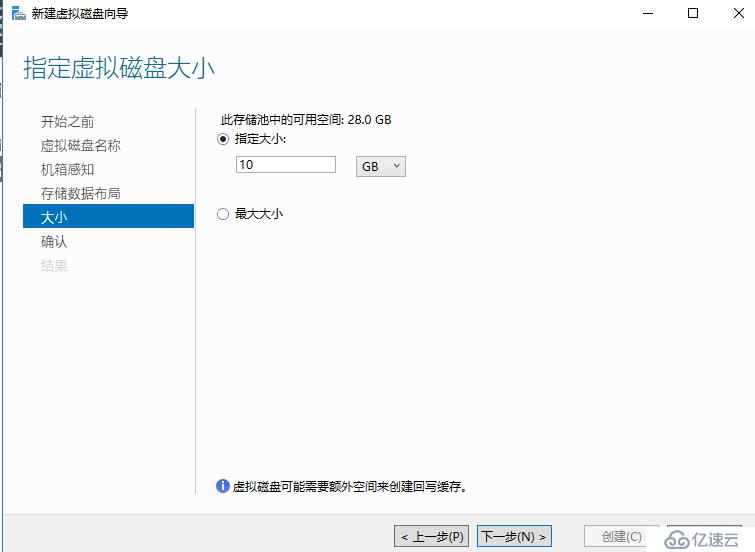
數據磁盤
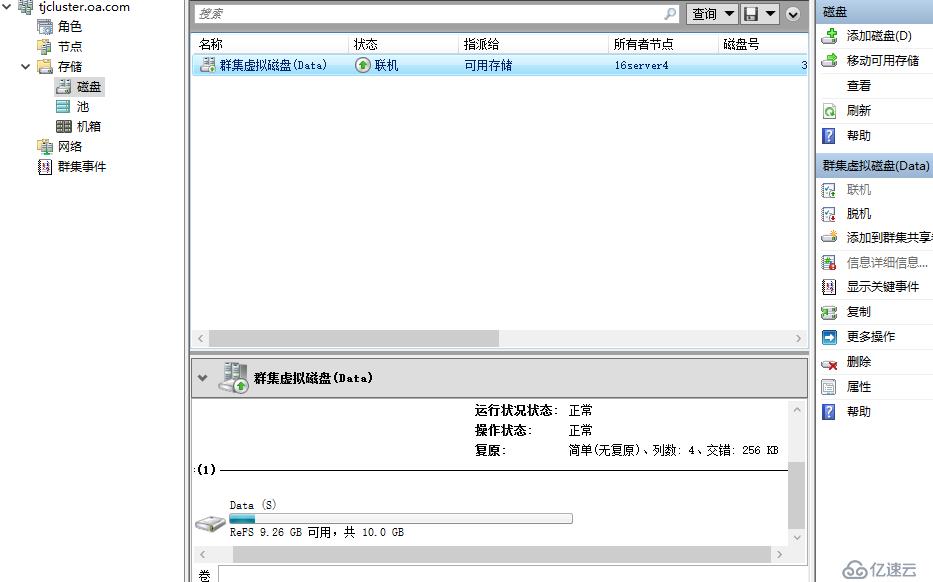
日志磁盤
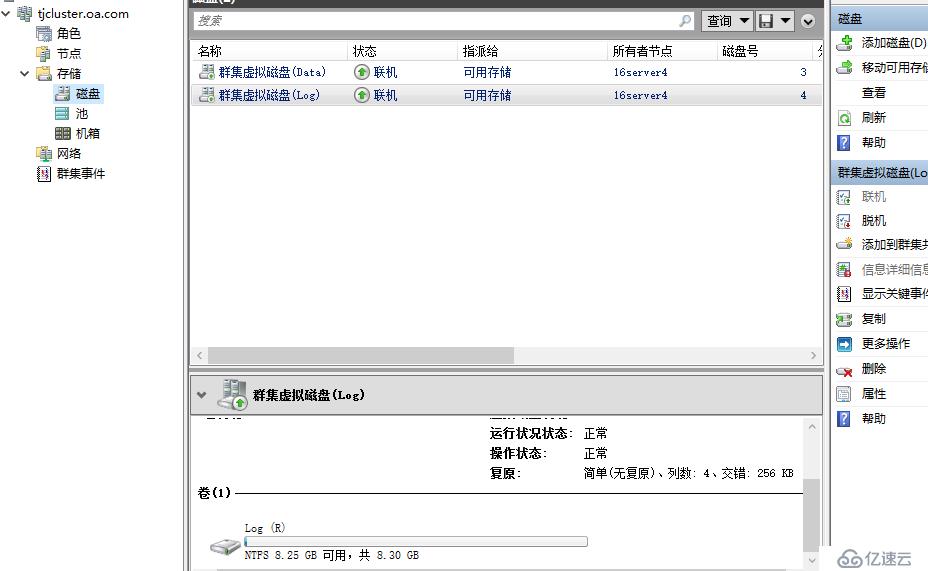
天津站點配置群集角色
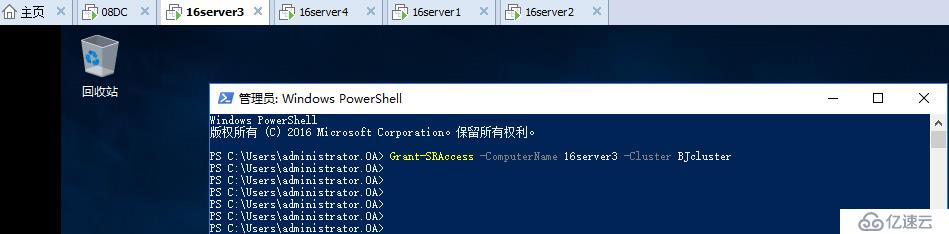
在天津站點任意節點上授予到北京站點群集的權限
Grant-SRAccess -ComputerName 16server3 -Cluster BJcluster
在北京站點任意節點上授予到天津站點群集的權限
Grant-SRAccess -ComputerName 16server1 -Cluster TJcluster

創建群集對群集復制關系
New-SRPartnership -SourceComputerName bjcluster -SourceRGName rg01 -SourceVolumeName C:\ClusterStorage\Volume1 -SourceLogVolumeName R: -DestinationComputerName tjcluster -DestinationRGName rg02 -DestinationVolumeName C:\ClusterStorage\Volume1 -DestinationLogVolumeName R:
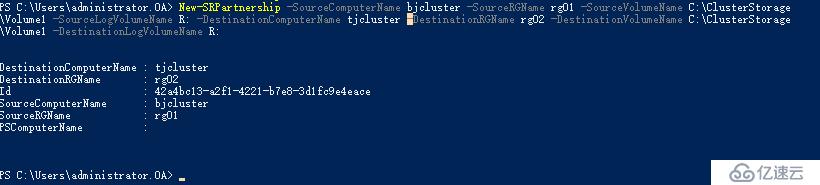
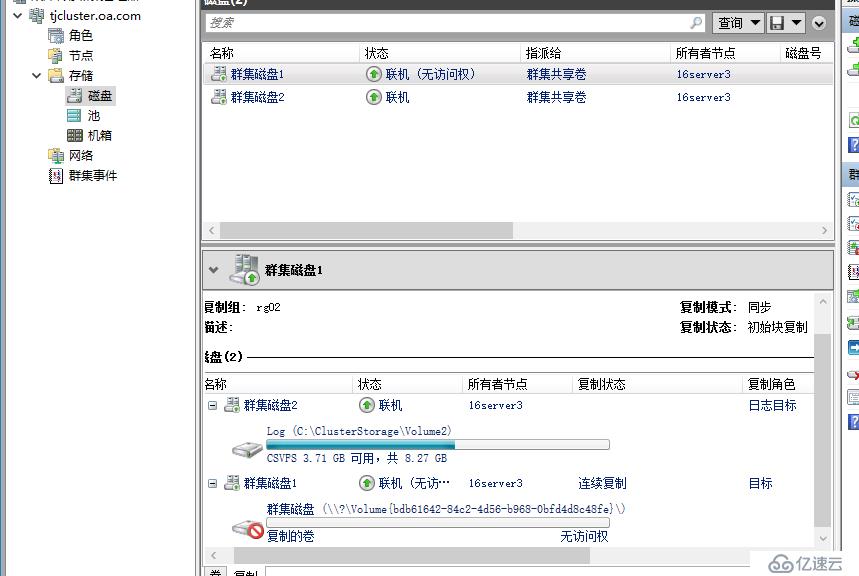
創建完成復制關系后,當前天津群集的數據磁盤會變成 聯機(無訪問權) ,到這里大家需要有這個意識,對于跨群集來說,我們現在把復制的邊界跨越了群集,因此每個復制組運作過程中都會有一個群集的數據磁盤是待命狀態,對于待命群集,復制組內磁盤不能被使用,如果部署多個跨群集復制組,可以實現群集應用互為待命。
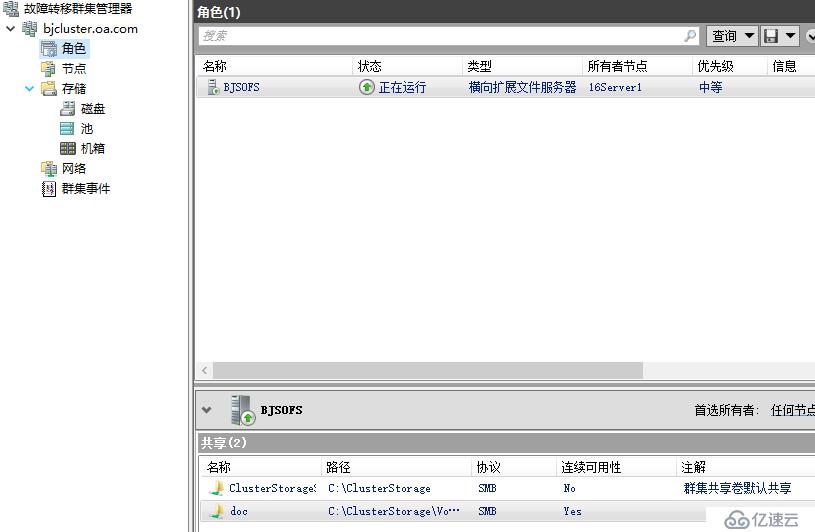
當前文件服務器群集角色在北京站點提供服務,所有者節點為16server1,已經有一些數據文件
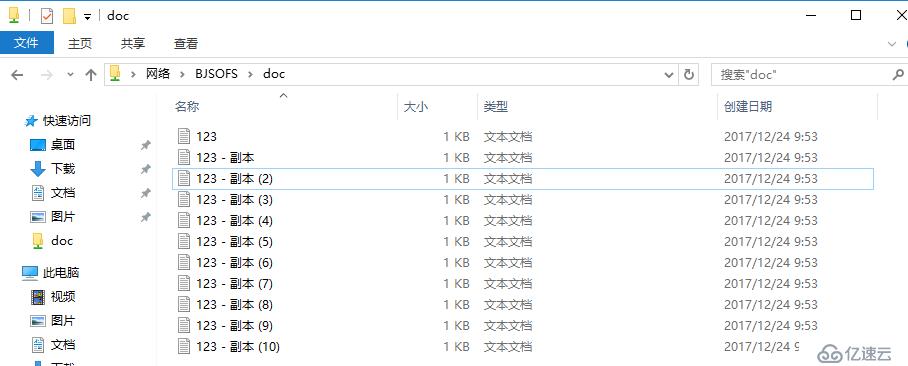
直接斷電16server1,SOFS自動透明故障轉移至同站點內16server2
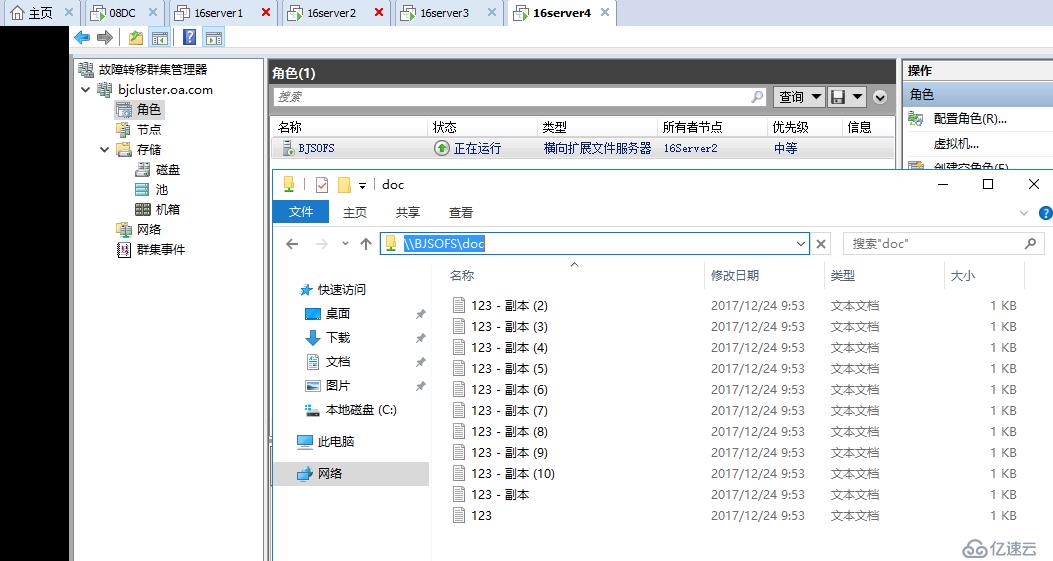
存儲復制繼續在同站點16server2進行,由此大家可以看出,存儲復制和Hyper-V復制一樣,在群集內有一個復制協調引擎,通過群集名稱和外面的群集進行復制,然后再協調內部由那個節點進行復制,一旦某個群集節點宕機,自動協調另外一個節點參與復制,區別在于Hyper-V復制在群集有顯式的群集角色,存儲復制的群集角色是隱藏的
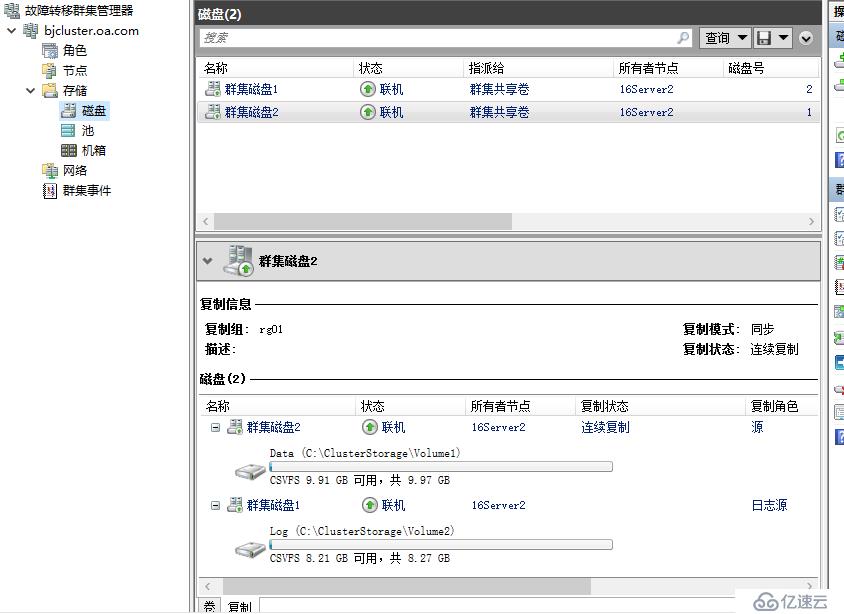
接下來模擬北京站點全部發生災難,16server1,16server2全部斷電,這時來到天津站點的群集可以看到,當前群集磁盤處于脫機狀態,并不會自動完成跨群集的故障轉移
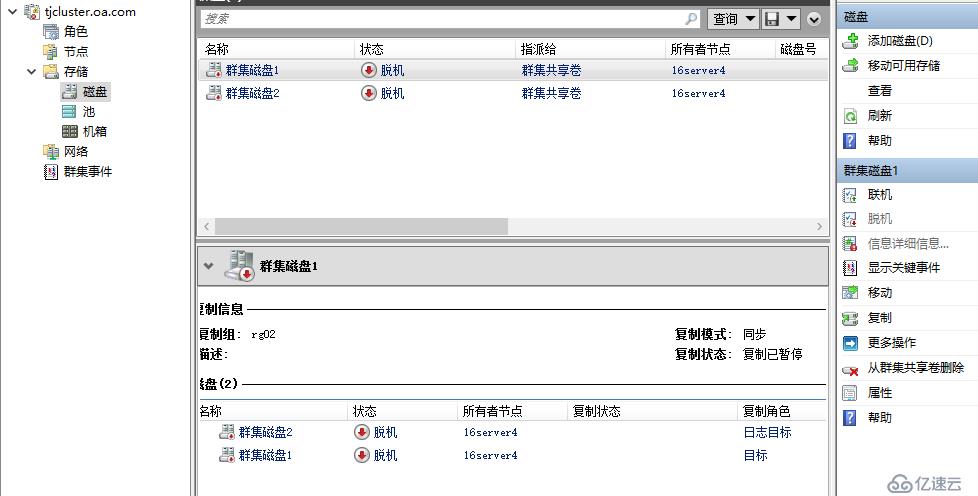
手動強制跨群集故障轉移
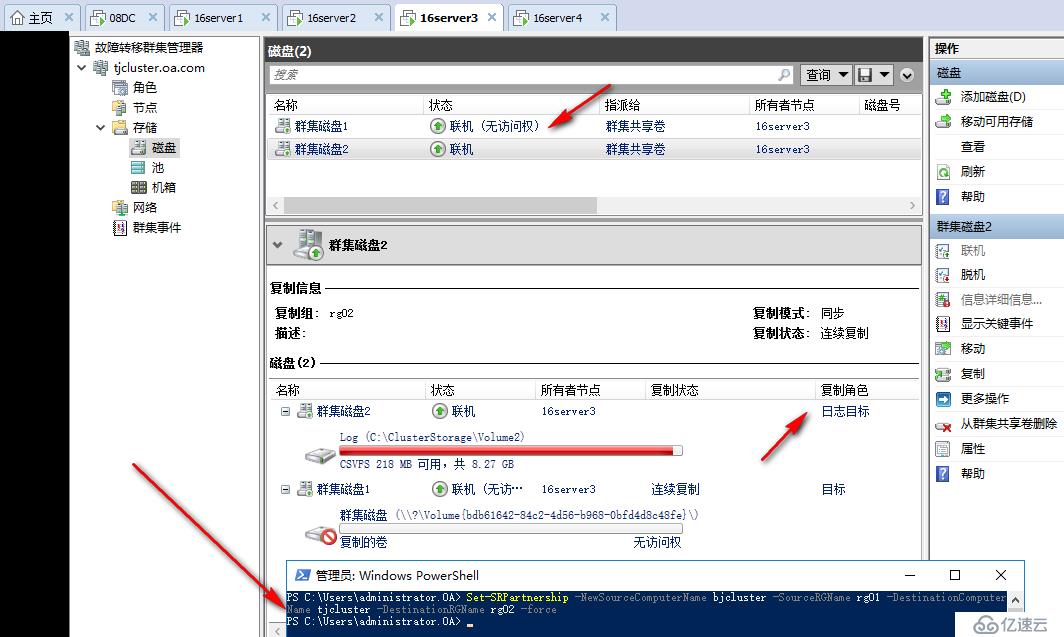
Set-SRPartnership -NewSourceComputerName tjcluster -SourceRGName rg02 -DestinationComputerName bjcluster -DestinationRGName rg01 -force

執行完成后當前數據在天津站點可讀
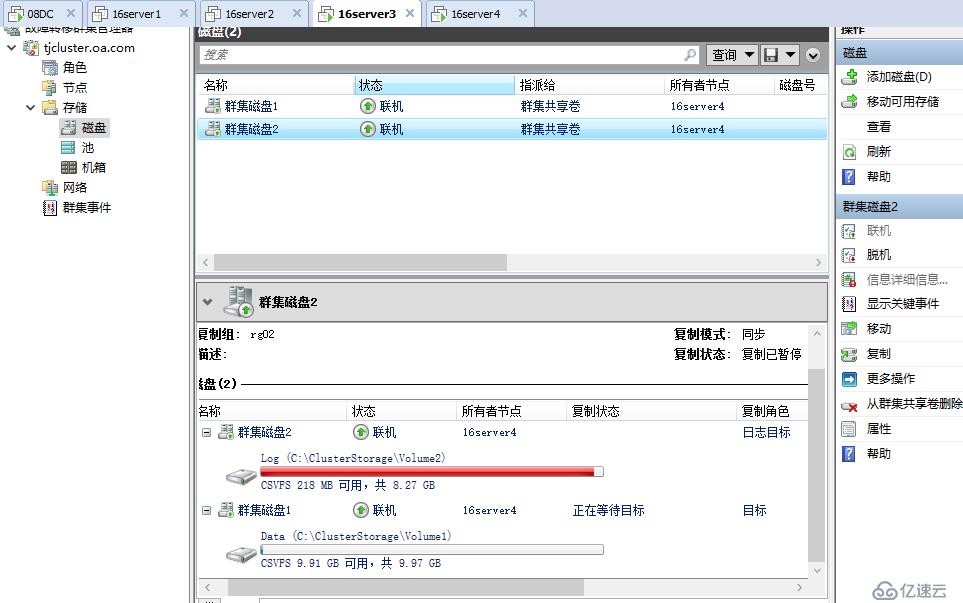
打開數據磁盤CSV可以看到北京站點的數據被完整復制過來
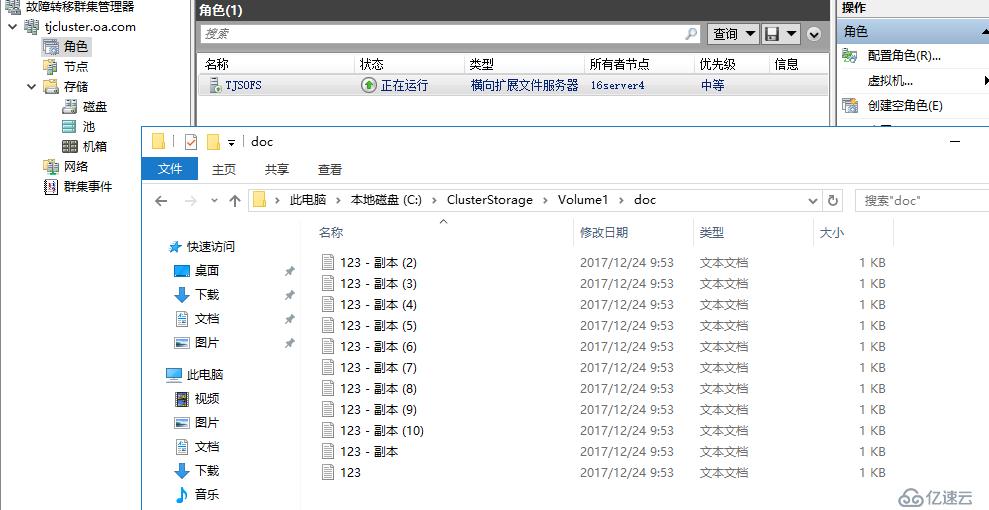
實際測試跨服務器故障轉移后,共享文件夾權限并不會被自動遷移,默認情況下會是未共享狀態,自行手動共享即可,猜想是跨服務器轉移磁盤的緣故,如果權限較多,大家可以嘗試下配合權限遷移能否映射過來,不過事實上,對于這種跨服務器故障轉移的負載,實際生產環境還是建議以SQL文件,VHDX,VHD文件為主,發生跨群集故障轉移后直接在新群集重新啟動數據庫或虛擬機角色。
現在我們完成了跨群集的災難恢復,如果采用網絡分離的架構,把天津站點的訪問公開給北京用戶即可,正如我們之前所說,轉移后會使用新的名稱進行訪問
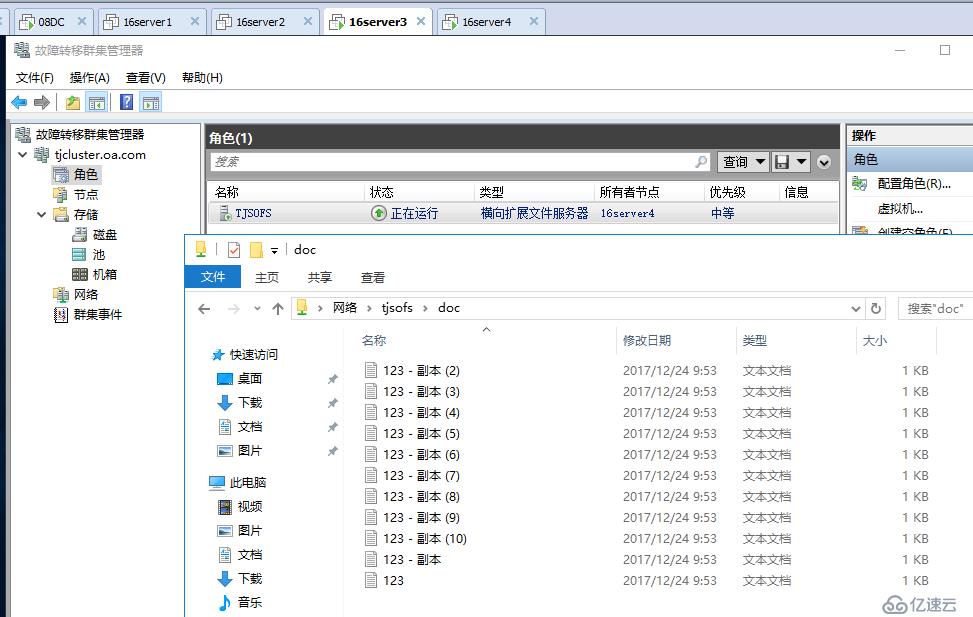
即便這時天津站點再壞掉一個節點,SOFS也可以透明故障轉移至僅存的節點存活,前提是仲裁配置得當
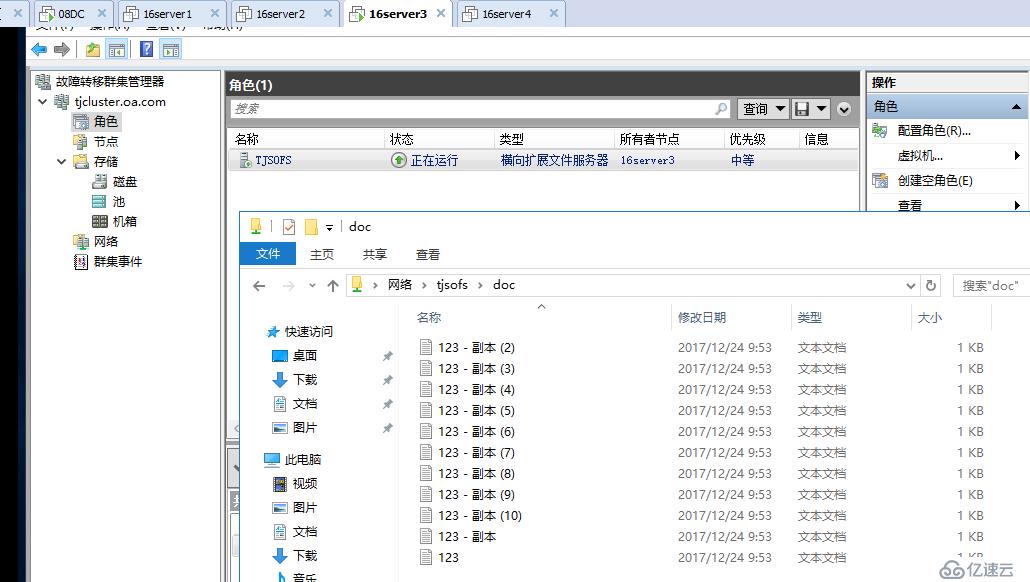
僅剩下一個最后節點時,存儲復制會處于暫停狀態,等待其它節點恢復
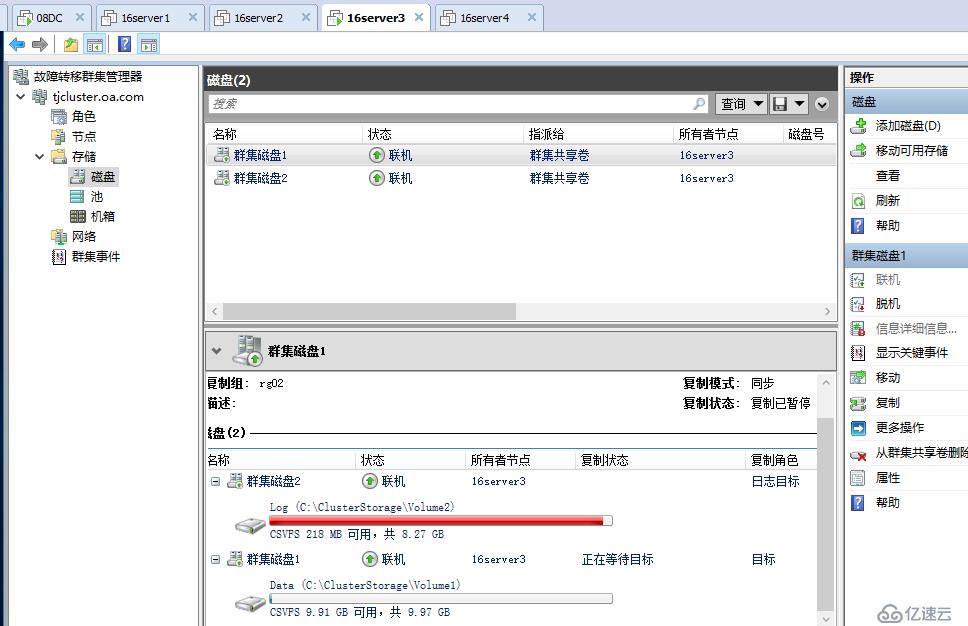
等待一段時間后,各站點服務器陸續修復完成上線,存儲復制自動恢復正常連續復制,當前主復制站點為天津站點
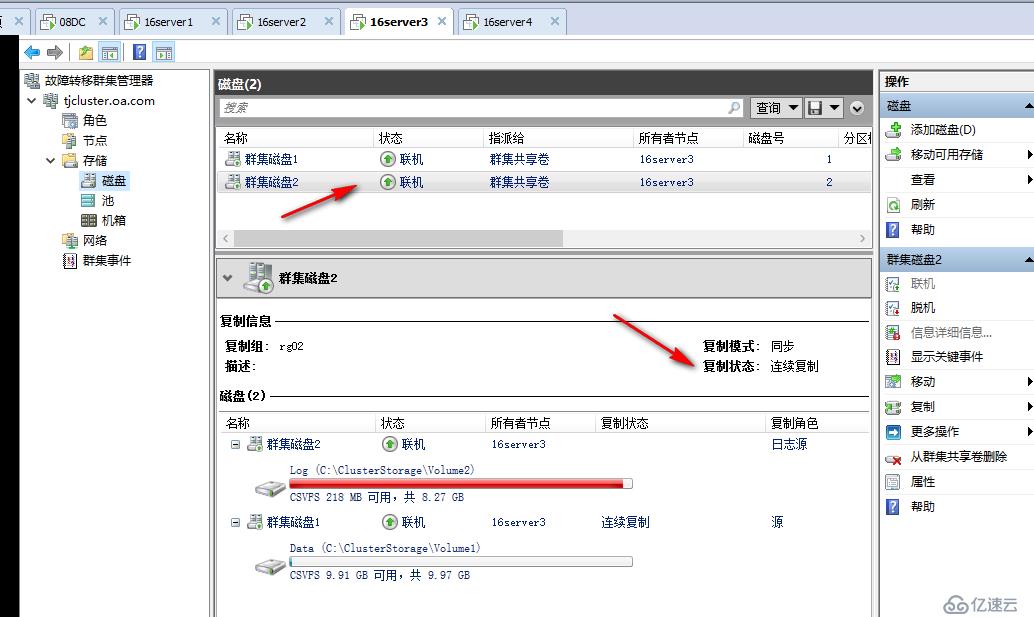
如果希望此時繼續由北京站點恢復為主站點,可以執行反轉復制,把天津站點內容復制回北京站點,主備關系恢復
通過三篇對于Windows Server 2016存儲復制功能的介紹,相信大家對于這項技術都有了了解,很高興的一點是聽聞有的朋友看了我的博客已經開始在實際環境使用了,存儲復制技術是2016存儲的一項主要進步,原生的塊級別復制,如果節點很少,不想維護群集的話,可以使用單機對單機場景實現災難恢復,如果希望群集獲得最低的RTO/RPO,可以使用延伸群集功能,獲得自動化的災難恢復,如果希望規劃更為復雜的架構,針對于不同站點希望使用不同網絡和存儲架構,實現跨群集跨站點級別的災難恢復,現在也可以實現,最終希望大家看了文章后都能有自己的思考
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





