溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“SpringBoot+Dubbo集成ELK實戰的示例分析”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“SpringBoot+Dubbo集成ELK實戰的示例分析”這篇文章吧。
前言
一直以來,日志始終伴隨著我們的開發和運維過程。當系統出現了Bug,往往就是通過Xshell連接到服務器,定位到日志文件,一點點排查問題來源。
隨著互聯網的快速發展,我們的系統越來越龐大。依賴肉眼分析日志文件來排查問題的方式漸漸凸顯出一些問題:
分布式集群環境下,服務器數量可能達到成百上千,如何準確定位?
微服務架構中,如何根據異常信息,定位其他各服務的上下文信息?
隨著日志文件的不斷增大,可能面臨在服務器上不能直接打開的尷尬。
文本搜索太慢、無法多維度查詢等
面臨這些問題,我們需要集中化的日志管理,將所有服務器節點上的日志統一收集,管理,訪問。
而今天,我們的手段的就是使用 Elastic Stack 來解決它們。
一、什么是Elastic Stack ?
或許有人對Elastic感覺有一點點陌生,它的前生正是ELK ,Elastic Stack 是ELK Stack的更新換代產品。
Elastic Stack分別對應了四個開源項目。
Beats
Beats 平臺集合了多種單一用途數據采集器,它負責采集各種類型的數據。比如文件、系統監控、Windows事件日志等。
Logstash
Logstash 是服務器端數據處理管道,能夠同時從多個來源采集數據,轉換數據。沒錯,它既可以采集數據,也可以轉換數據。采集到了非結構化的數據,通過過濾器把他格式化成友好的類型。
Elasticsearch
Elasticsearch 是一個基于 JSON 的分布式搜索和分析引擎。作為 Elastic Stack 的核心,它負責集中存儲數據。我們上面利用Beats采集數據,通過Logstash轉換之后,就可以存儲到Elasticsearch。
Kibana
最后,就可以通過 Kibana,對自己的 Elasticsearch 中的數據進行可視化。
本文的實例是通過 SpringBoot+Dubbo 的微服務架構,結合 Elastic Stack 來整合日志的。架構如下:
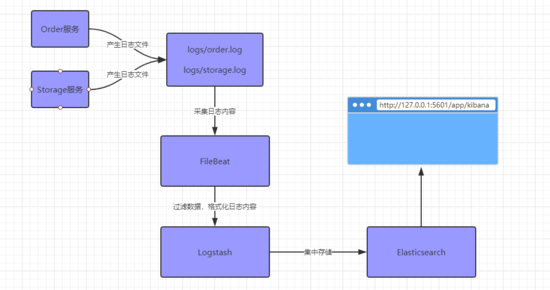
注意,閱讀本文需要了解ELK組件的基本概念和安裝。本文不涉及安裝和基本配置過程,重點是如何與項目集成,達成上面的需求。
二、采集、轉換
1、FileBeat
在SpringBoot項目中,我們首先配置Logback,確定日志文件的位置。
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${user.dir}/logs/order.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${user.dir}/logs/order.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder>
<pattern></pattern>
</encoder>
</appender>Filebeat 提供了一種輕量型方法,用于轉發和匯總日志與文件。
所以,我們需要告訴 FileBeat 日志文件的位置、以及向何處轉發內容。
如下所示,我們配置了 FileBeat 讀取 usr/local/logs 路徑下的所有日志文件。
- type: log # Change to true to enable this input configuration. enabled: true # Paths that should be crawled and fetched. Glob based paths. paths: - /usr/local/logs/*.log
然后,告訴 FileBeat 將采集到的數據轉發到 Logstash 。
#----------------------------- Logstash output -------------------------------- output.logstash: # The Logstash hosts hosts: ["192.168.159.128:5044"]
另外, FileBeat 采集文件數據時,是一行一行進行讀取的。但是 FileBeat 收集的文件可能包含跨越多行文本的消息。
例如,在開源框架中有意的換行:
2019-10-29 20:36:04.427 INFO org.apache.dubbo.spring.boot.context.event.WelcomeLogoApplicationListener :: Dubbo Spring Boot (v2.7.1) : https://github.com/apache/incubator-dubbo-spring-boot-project :: Dubbo (v2.7.1) : https://github.com/apache/incubator-dubbo :: Discuss group : dev@dubbo.apache.org
或者Java異常堆棧信息:
2019-10-29 21:30:59.849 INFO com.viewscenes.order.controller.OrderController http-nio-8011-exec-2 開始獲取數組內容... java.lang.IndexOutOfBoundsException: Index: 3, Size: 0 at java.util.ArrayList.rangeCheck(ArrayList.java:657) at java.util.ArrayList.get(ArrayList.java:433)
所以,我們還需要配置 multiline ,以指定哪些行是單個事件的一部分。
multiline.pattern 指定要匹配的正則表達式模式。
multiline.negate 定義是否為否定模式。
multiline.match 如何將匹配的行組合到事件中,設置為after或before。
聽起來可能比較饒口,我們來看一組配置:
# The regexp Pattern that has to be matched. The example pattern matches all lines starting with [
multiline.pattern: '^\<|^[[:space:]]|^[[:space:]]+(at|\.{3})\b|^java.'
# Defines if the pattern set under pattern should be negated or not. Default is false.
multiline.negate: false
# Match can be set to "after" or "before". It is used to define if lines should be append to a pattern
# that was (not) matched before or after or as long as a pattern is not matched based on negate.
# Note: After is the equivalent to previous and before is the equivalent to to next in Logstash
multiline.match: after上面配置文件說的是,如果文本內容是以 < 或 空格 或空格+at+包路徑 或 java. 開頭,那么就將此行內容當做上一行的后續,而不是當做新的行。
就上面的Java異常堆棧信息就符合這個正則。所以, FileBeat 會將
java.lang.IndexOutOfBoundsException: Index: 3, Size: 0 at java.util.ArrayList.rangeCheck(ArrayList.java:657) at java.util.ArrayList.get(ArrayList.java:433)
這些內容當做 開始獲取數組內容... 的一部分。
2、Logstash
在 Logback 中,我們打印日志的時候,一般會帶上日志等級、執行類路徑、線程名稱等信息。
有一個重要的信息是,我們在 ELK 查看日志的時候,是否希望將以上條件單獨拿出來做統計或者精確查詢?
如果是,那么就需要用到 Logstash 過濾器,它能夠解析各個事件,識別已命名的字段以構建結構,并將它們轉換成通用格式。
那么,這時候就要先看我們在項目中,配置了日志以何種格式輸出。
比如,我們最熟悉的JSON格式。先來看 Logback 配置:
<pattern>
{"log_time":"%d{yyyy-MM-dd HH:mm:ss.SSS}","level":"%level","logger":"%logger","thread":"%thread","msg":"%m"}
</pattern>沒錯, Logstash 過濾器中正好也有一個JSON解析插件。我們可以這樣配置它:
input{
stdin{}
}
filter{
json {
source => "message"
}
}
output {
stdout {}
}這么一段配置就是說利用JSON解析器格式化數據。我們輸入這樣一行內容:
{
"log_time":"2019-10-29 21:45:12.821",
"level":"INFO",
"logger":"com.viewscenes.order.controller.OrderController",
"thread":"http-nio-8011-exec-1",
"msg":"接收到訂單數據."
}Logstash 將會返回格式化后的內容:

但是JSON解析器并不太適用,因為我們打印的日志中msg字段本身可能就是JSON數據格式。
比如:
{
"log_time":"2019-10-29 21:57:38.008",
"level":"INFO",
"logger":"com.viewscenes.order.controller.OrderController",
"thread":"http-nio-8011-exec-1",
"msg":"接收到訂單數據.{"amount":1000.0,"commodityCode":"MK66923","count":5,"id":1,"orderNo":"1001"}"
}這時候JSON解析器就會報錯。那怎么辦呢?
Logstash 擁有豐富的過濾器插件庫,或者你對正則有信心,也可以寫表達式去匹配。
正如我們在 Logback 中配置的那樣,我們的日志內容格式是已經確定的,不管是JSON格式還是其他格式。
所以,筆者今天推薦另外一種:Dissect。
Dissect過濾器是一種拆分操作。與將一個定界符應用于整個字符串的常規拆分操作不同,此操作將一組定界符應用于字符串值。Dissect不使用正則表達式,并且速度非常快。
比如,筆者在這里以 | 當做定界符。
input{
stdin{}
}
filter{
dissect {
mapping => {
"message" => "%{log_time}|%{level}|%{logger}|%{thread}|%{msg}"
}
}
}
output {
stdout {}
}然后在 Logback 中這樣去配置日志格式:
<pattern>
%d{yyyy-MM-dd HH:mm:ss.SSS}|%level|%logger|%thread|%m%n
</pattern>最后同樣可以得到正確的結果:

到此,關于數據采集和格式轉換都已經完成。當然,上面的配置都是控制臺輸入、輸出。
我們來看一個正兒八經的配置,它從 FileBeat 中采集數據,經由 dissect 轉換格式,并將數據輸出到 elasticsearch 。
input {
beats {
port => 5044
}
}
filter{
dissect {
mapping => {
"message" => "%{log_time}|%{level}|%{logger}|%{thread}|%{msg}"
}
}
date{
match => ["log_time", "yyyy-MM-dd HH:mm:ss.SSS"]
target => "@timestamp"
}
}
output {
elasticsearch {
hosts => ["192.168.216.128:9200"]
index => "logs-%{+YYYY.MM.dd}"
}
}不出意外的話,打開瀏覽器我們在Kibana中就可以對日志進行查看。比如我們查看日志等級為 DEBUG 的條目:

三、追蹤
試想一下,我們在前端發送了一個訂單請求。如果后端系統是微服務架構,可能會經由庫存系統、優惠券系統、賬戶系統、訂單系統等多個服務。如何追蹤這一個請求的調用鏈路呢?
1、MDC機制
首先,我們要了解一下MDC機制。
MDC - Mapped Diagnostic Contexts ,實質上是由日志記錄框架維護的映射。其中應用程序代碼提供鍵值對,然后可以由日志記錄框架將其插入到日志消息中。
簡而言之,我們使用了 MDC.PUT(key,value) ,那么 Logback 就可以在日志中自動打印這個value。
在 SpringBoot 中,我們就可以先寫一個 HandlerInterceptor ,攔截所有的請求,來生成一個 traceId 。
@Component
public class TraceIdInterceptor implements HandlerInterceptor {
Snowflake snowflake = new Snowflake(1,0);
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler){
MDC.put("traceId",snowflake.nextIdStr());
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView){
MDC.remove("traceId");
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex){}
}然后在 Logback 中配置一下,讓這個 traceId 出現在日志消息中。
<pattern>
%d{yyyy-MM-dd HH:mm:ss.SSS}|%level|%logger|%thread|%X{traceId}|%m%n
</pattern>2、Dubbo Filter
另外還有一個問題,就是在微服務架構下我們怎么讓這個 traceId 來回透傳。
熟悉 Dubbo 的朋友可能就會想到隱式參數。是的,我們就是利用它來完成 traceId 的傳遞。
@Activate(group = {Constants.PROVIDER, Constants.CONSUMER}, order = 99)
public class TraceIdFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
String tid = MDC.get("traceId");
String rpcTid = RpcContext.getContext().getAttachment("traceId");
boolean bind = false;
if (tid != null) {
RpcContext.getContext().setAttachment("traceId", tid);
} else {
if (rpcTid != null) {
MDC.put("traceId",rpcTid);
bind = true;
}
}
try{
return invoker.invoke(invocation);
}finally {
if (bind){
MDC.remove("traceId");
}
}
}
}這樣寫完,我們就可以愉快的查看某一次請求所有的日志信息啦。比如下面的請求,訂單服務和庫存服務兩個系統的日志。
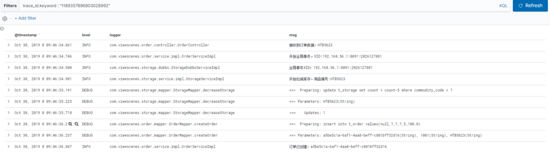
四、總結
本文介紹了 Elastic Stack 的基本概念。并通過一個 SpringBoot+Dubbo 項目,演示如何做到日志的集中化管理、追蹤。
事實上, Kibana 具有更多的分析和統計功能。所以它的作用不僅限于記錄日志。
另外 Elastic Stack 性能也很不錯。筆者在一臺虛擬機上,記錄了100+萬條用戶數據,index大小為1.1G,查詢和統計速度也不遜色。

以上是“SpringBoot+Dubbo集成ELK實戰的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





