溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
版本對照
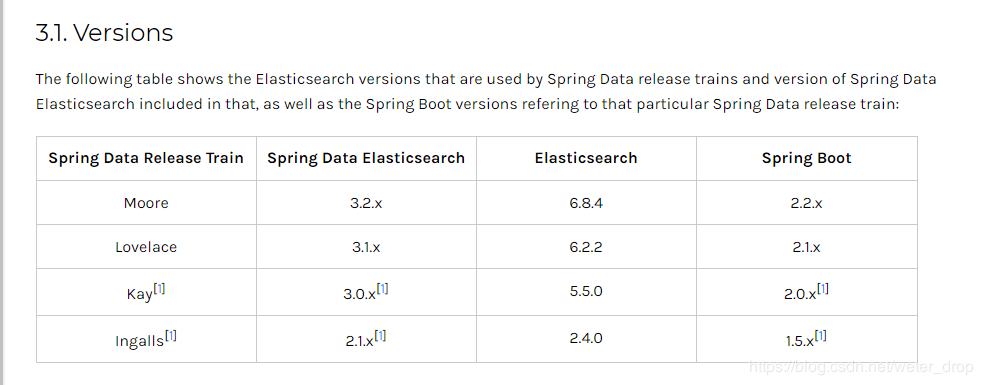
各版本的文檔說明:https://docs.spring.io/spring-data/elasticsearch/docs/
1、在application.yml中添加配置
spring:
data:
elasticsearch:
repositories:
enabled: true
#多實例集群擴展時需要配置以下兩個參數
#cluster-name: datab-search
#cluster-nodes: 127.0.0.1:9300,127.0.0.1:9301
2、添加 Maven 依賴
<!---開箱即用,版本默認和springboot版本對應-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
3、建立實體entity
注解說明:
Spring Data通過注解來聲明字段的映射屬性,有下面的三個注解:
示例:
@Document(indexName = "cp_doc", type = "doc", shards = 10, replicas = 0)
public class CpDocument extends BaseEntity {
@Id//作用在成員變量,標記一個字段作為id主鍵
private long id ;
@Field(type = FieldType.Text)
private String name ;
@Field(type = FieldType.Text)
private String address ;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
4、編寫 Repository 訪問層
/**
* 基本操作repository-curd
* @author 滾動的蛋
*
*/
public interface CpRepository extends ElasticsearchRepository<CpDocument, Integer> {
}
5、創建索引+查詢示例
@RunWith(SpringRunner.class)
@SpringBootTest
public class ElasticSearchTest {
@Autowired
CpRepository cpRepository;
@Autowired
ElasticsearchTemplate elsTemplate;//ElasticsearchTemplate中提供了創建索引的API<br data-filtered="filtered"><br data-filtered="filtered">
@Test
public void addIndexTest() {
//創建索引
boolean indexRes = elsTemplate.createIndex(CpDocument.class);
System.out.println("======創建索引結果:"+indexRes+"=========");
//添加索引
CpDocument cpTest = new CpDocument();
cpTest.setId(1);
cpTest.setName("阿里巴巴");
cpTest.setAddress("北京路12號");
cpRepository.save(cpTest);
}
@Test
public void srarchTest() {
//這個只做一個多字段的匹配查詢示例,其它的可以查看API文檔使用
//"name","address" 為匹配的字段
MultiMatchQueryBuilder multiMatchQuery = QueryBuilders.multiMatchQuery("阿里巴巴","address","name");//多字段匹配QueryBuilder
SearchQuery searchQuery = new NativeSearchQueryBuilder()//構建查詢對象
.withQuery(multiMatchQuery)
.withIndices("cp_doc")//索引名
.withPageable(PageRequest.of(0, 10))//分頁
.build();
Iterable<CpDocument> productDtos = cpRepository.search(searchQuery);
ArrayList<CpDocument> CpDocuments = Lists.newArrayList(productDtos);
for (CpDocument cpDocument : CpDocuments) {
System.out.printf("企業名稱:%s,企業地址:%s\n",cpDocument.getName(),cpDocument.getAddress());
}
}
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





