溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關node.js中怎么讀取docx文本,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
其實docx就是一個zip包,然后封裝了一些xml文件。可以直接將docx的包改后綴為.zip來打開觀看。
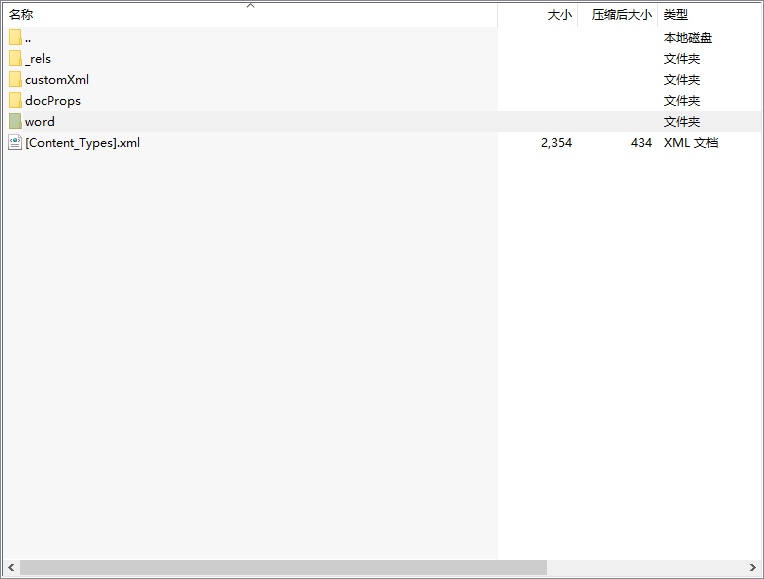
進入word文件夾
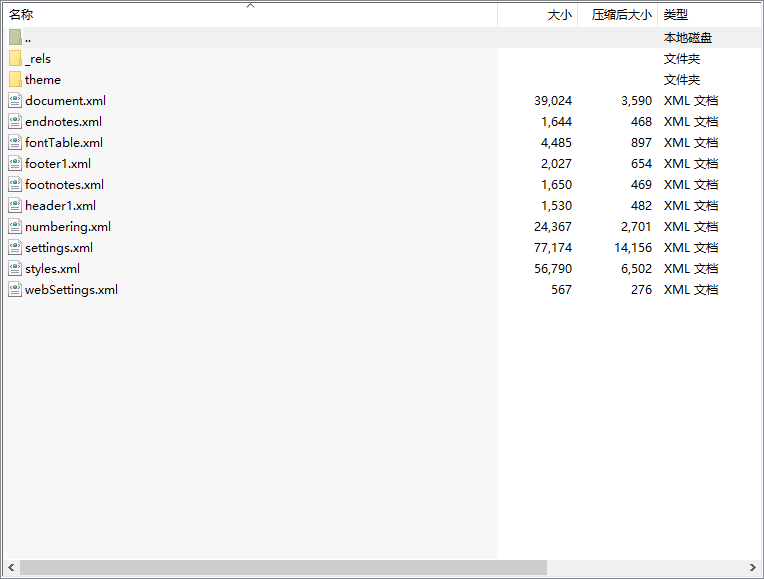
里面有幾個主要的文件。
document.xml 這個就是文檔的主要內容
numbering.xml 這個就是標題號,以及標題號的一些屬性
styles.xml 這個就是樣式列表
打開document.xml 你就會發現,所有的文本都是用 <w:t>標簽包著的。這個就是本文的關鍵
代碼
首先,需要通過npm安裝一個能查看zip文件的包:adm-zip;
然后,寫下下列代碼即可
const fs = require("fs");
const AdmZip = require('adm-zip'); //引入查看zip文件的包
const zip = new AdmZip(filePath); //filePath為文件路徑
let contentXml = zip.readAsText("word/document.xml");//將document.xml讀取為text內容;
let str = "";
contentXml .match(/<w:t>[\s\S]*?<\/w:t>/ig).forEach((item)=>{
str += item.slice(5,-6)});
fs.writeFile("./2.txt",str,(err)=>{//將./2.txt替換為你要輸出的文件路徑
if(err)throw err;
});最近正在用node.js去解析docx的工作。先將最簡單的寫在上面。回頭有空再繼續分享
最新更新
之前隨手寫的代碼,今天測試發現用更新后的代碼比源代碼的效率提升十倍以上。
//原代碼
//str += item.replace("<w:t>","").replace("</w:t>","");
//更新代碼
str += item.slice(5,-6)附上測試代碼
var str = "<w:t>sdfjpasif aefnmasd;lf asdfsdf</w:t>";
var arr = [];
for(var i=0;i<50000;i++){
arr.push(str);
}
console.time("replactest");
arr.forEach((item)=>{
item.replace(/<w:t>/,"").replace(/<\/w:t>/,"");
});
console.timeEnd("replactest");
//replactest: 20.560ms
console.time("replactest2");
arr.forEach((item)=>{
item.replace(/<\/*w:t>/g,"");
});
console.timeEnd("replactest2");
//replactest2: 14.926ms
console.time("replactest3");
arr.forEach((item)=>{
item.replace(/(^<w:t>)|(<\/w:t>$)/g,"");
});
console.timeEnd("replactest3");
//replactest3: 14.402ms
console.time("slice");
arr.forEach((item)=>{
item.slice(5,-6);
});
console.timeEnd("slice");
//slice: 1.718ms關于node.js中怎么讀取docx文本就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





