溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“Tensorflow可視化工具Tensorboard怎么用”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Tensorflow可視化工具Tensorboard怎么用”這篇文章吧。
當使用Tensorflow訓練大量深層的神經網絡時,我們希望去跟蹤神經網絡的整個訓練過程中的信息,比如迭代的過程中每一層參數是如何變化與分布的,比如每次循環參數更新后模型在測試集與訓練集上的準確率是如何的,比如損失值的變化情況,等等。如果能在訓練的過程中將一些信息加以記錄并可視化得表現出來,是不是對我們探索模型有更深的幫助與理解呢?
Tensorflow官方推出了可視化工具Tensorboard,可以幫助我們實現以上功能,它可以將模型訓練過程中的各種數據匯總起來存在自定義的路徑與日志文件中,然后在指定的web端可視化地展現這些信息。
1. Tensorboard介紹
1.1 Tensorboard的數據形式
Tensorboard可以記錄與展示以下數據形式:
(1)標量Scalars
(2)圖片Images
(3)音頻Audio
(4)計算圖Graph
(5)數據分布Distribution
(6)直方圖Histograms
(7)嵌入向量Embeddings
1.2 Tensorboard的可視化過程
(1)首先肯定是先建立一個graph,你想從這個graph中獲取某些數據的信息
(2)確定要在graph中的哪些節點放置summary operations以記錄信息
使用tf.summary.scalar記錄標量
使用tf.summary.histogram記錄數據的直方圖
使用tf.summary.distribution記錄數據的分布圖
使用tf.summary.image記錄圖像數據
….
(3)operations并不會去真的執行計算,除非你告訴他們需要去run,或者它被其他的需要run的operation所依賴。而我們上一步創建的這些summary operations其實并不被其他節點依賴,因此,我們需要特地去運行所有的summary節點。但是呢,一份程序下來可能有超多這樣的summary 節點,要手動一個一個去啟動自然是及其繁瑣的,因此我們可以使用tf.summary.merge_all去將所有summary節點合并成一個節點,只要運行這個節點,就能產生所有我們之前設置的summary data。
(4)使用tf.summary.FileWriter將運行后輸出的數據都保存到本地磁盤中
(5)運行整個程序,并在命令行輸入運行tensorboard的指令,之后打開web端可查看可視化的結果
2.Tensorboard使用案例
不出所料呢,我們還是使用最基礎的識別手寫字體的案例~
不過本案例也是先不去追求多美好的模型,只是建立一個簡單的神經網絡,讓大家了解如何使用Tensorboard。
2.1 導入包,定義超參數,載入數據
(1)首先還是導入需要的包:
from __future__ import absolute_import from __future__ import division from __future__ import print_function import argparse import sys import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data
(2)定義固定的超參數,方便待使用時直接傳入。如果你問,這個超參數為啥要這樣設定,如何選擇最優的超參數?這個問題此處先不討論,超參數的選擇在機器學習建模中最常用的方法就是“交叉驗證法”。而現在假設我們已經獲得了最優的超參數,設置學利率為0.001,dropout的保留節點比例為0.9,最大循環次數為1000.
另外,還要設置兩個路徑,第一個是數據下載下來存放的地方,一個是summary輸出保存的地方。
max_step = 1000 # 最大迭代次數 learning_rate = 0.001 # 學習率 dropout = 0.9 # dropout時隨機保留神經元的比例 data_dir = '' # 樣本數據存儲的路徑 log_dir = '' # 輸出日志保存的路徑
(3)接著加載數據,下載數據是直接調用了tensorflow提供的函數read_data_sets,輸入兩個參數,第一個是下載到數據存儲的路徑,第二個one_hot表示是否要將類別標簽進行獨熱編碼。它首先回去找制定目錄下有沒有這個數據文件,沒有的話才去下載,有的話就直接讀取。所以第一次執行這個命令,速度會比較慢。
mnist = input_data.read_data_sets(data_dir,one_hot=True)
2.2 創建特征與標簽的占位符,保存輸入的圖片數據到summary
(1)創建tensorflow的默認會話:
sess = tf.InteractiveSession()
(2)創建輸入數據的占位符,分別創建特征數據x,標簽數據y_
在tf.placeholder()函數中傳入了3個參數,第一個是定義數據類型為float32;第二個是數據的大小,特征數據是大小784的向量,標簽數據是大小為10的向量,None表示不定死大小,到時候可以傳入任何數量的樣本;第3個參數是這個占位符的名稱。
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')(3)使用tf.summary.image保存圖像信息
特征數據其實就是圖像的像素數據拉升成一個1*784的向量,現在如果想在tensorboard上還原出輸入的特征數據對應的圖片,就需要將拉升的向量轉變成28 * 28 * 1的原始像素了,于是可以用tf.reshape()直接重新調整特征數據的維度:
將輸入的數據轉換成[28 * 28 * 1]的shape,存儲成另一個tensor,命名為image_shaped_input。
為了能使圖片在tensorbord上展示出來,使用tf.summary.image將圖片數據匯總給tensorbord。
tf.summary.image()中傳入的第一個參數是命名,第二個是圖片數據,第三個是最多展示的張數,此處為10張
with tf.name_scope('input_reshape'):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', image_shaped_input, 10)2.3 創建初始化參數的方法,與參數信息匯總到summary的方法
(1)在構建神經網絡模型中,每一層中都需要去初始化參數w,b,為了使代碼簡介美觀,最好將初始化參數的過程封裝成方法function。
創建初始化權重w的方法,生成大小等于傳入的shape參數,標準差為0.1,正態分布的隨機數,并且將它轉換成tensorflow中的variable返回。
def weight_variable(shape): """Create a weight variable with appropriate initialization.""" initial = tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial)
創建初始換偏執項b的方法,生成大小為傳入參數shape的常數0.1,并將其轉換成tensorflow的variable并返回
def bias_variable(shape): """Create a bias variable with appropriate initialization.""" initial = tf.constant(0.1, shape=shape) return tf.Variable(initial)
(2)我們知道,在訓練的過程在參數是不斷地在改變和優化的,我們往往想知道每次迭代后參數都做了哪些變化,可以將參數的信息展現在tenorbord上,因此我們專門寫一個方法來收錄每次的參數信息。
def variable_summaries(var):
"""Attach a lot of summaries to a Tensor (for TensorBoard visualization)."""
with tf.name_scope('summaries'):
# 計算參數的均值,并使用tf.summary.scaler記錄
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
# 計算參數的標準差
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
# 使用tf.summary.scaler記錄記錄下標準差,最大值,最小值
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
# 用直方圖記錄參數的分布
tf.summary.histogram('histogram', var)2.4 構建神經網絡層
(1)創建第一層隱藏層
創建一個構建隱藏層的方法,輸入的參數有:
input_tensor:特征數據
input_dim:輸入數據的維度大小
output_dim:輸出數據的維度大小(=隱層神經元個數)
layer_name:命名空間
act=tf.nn.relu:激活函數(默認是relu)
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
"""Reusable code for making a simple neural net layer.
It does a matrix multiply, bias add, and then uses relu to nonlinearize.
It also sets up name scoping so that the resultant graph is easy to read,
and adds a number of summary ops.
"""
# 設置命名空間
with tf.name_scope(layer_name):
# 調用之前的方法初始化權重w,并且調用參數信息的記錄方法,記錄w的信息
with tf.name_scope('weights'):
weights = weight_variable([input_dim, output_dim])
variable_summaries(weights)
# 調用之前的方法初始化權重b,并且調用參數信息的記錄方法,記錄b的信息
with tf.name_scope('biases'):
biases = bias_variable([output_dim])
variable_summaries(biases)
# 執行wx+b的線性計算,并且用直方圖記錄下來
with tf.name_scope('linear_compute'):
preactivate = tf.matmul(input_tensor, weights) + biases
tf.summary.histogram('linear', preactivate)
# 將線性輸出經過激勵函數,并將輸出也用直方圖記錄下來
activations = act(preactivate, name='activation')
tf.summary.histogram('activations', activations)
# 返回激勵層的最終輸出
return activations調用隱層創建函數創建一個隱藏層:輸入的維度是特征的維度784,神經元個數是500,也就是輸出的維度。
hidden1 = nn_layer(x, 784, 500, 'layer1')
(2)創建一個dropout層,,隨機關閉掉hidden1的一些神經元,并記錄keep_prob
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
tf.summary.scalar('dropout_keep_probability', keep_prob)
dropped = tf.nn.dropout(hidden1, keep_prob)(3)創建一個輸出層,輸入的維度是上一層的輸出:500,輸出的維度是分類的類別種類:10,激活函數設置為全等映射identity.(暫且先別使用softmax,會放在之后的損失函數中一起計算)
y = nn_layer(dropped, 500, 10, 'layer2', act=tf.identity)
2.5 創建損失函數
使用tf.nn.softmax_cross_entropy_with_logits來計算softmax并計算交叉熵損失,并且求均值作為最終的損失值。
with tf.name_scope('loss'):
# 計算交叉熵損失(每個樣本都會有一個損失)
diff = tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y)
with tf.name_scope('total'):
# 計算所有樣本交叉熵損失的均值
cross_entropy = tf.reduce_mean(diff)
tf.summary.scalar('loss', cross_entropy)2.6 訓練,并計算準確率
(1)使用AdamOptimizer優化器訓練模型,最小化交叉熵損失
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(learning_rate).minimize(
cross_entropy)(2)計算準確率,并用tf.summary.scalar記錄準確率
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
# 分別將預測和真實的標簽中取出最大值的索引,弱相同則返回1(true),不同則返回0(false)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
with tf.name_scope('accuracy'):
# 求均值即為準確率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)2.7 合并summary operation, 運行初始化變量
將所有的summaries合并,并且將它們寫到之前定義的log_dir路徑
# summaries合并 merged = tf.summary.merge_all() # 寫到指定的磁盤路徑中 train_writer = tf.summary.FileWriter(log_dir + '/train', sess.graph) test_writer = tf.summary.FileWriter(log_dir + '/test') # 運行初始化所有變量 tf.global_variables_initializer().run()
2.8 準備訓練與測試的兩個數據,循環執行整個graph進行訓練與評估
(1)現在我們要獲取之后要喂人的數據.
如果是train==true,就從mnist.train中獲取一個batch樣本,并且設置dropout值;
如果是不是train==false,則獲取minist.test的測試數據,并且設置keep_prob為1,即保留所有神經元開啟。
def feed_dict(train):
"""Make a TensorFlow feed_dict: maps data onto Tensor placeholders."""
if train:
xs, ys = mnist.train.next_batch(100)
k = dropout
else:
xs, ys = mnist.test.images, mnist.test.labels
k = 1.0
return {x: xs, y_: ys, keep_prob: k}(2)開始訓練模型。
每隔10步,就進行一次merge, 并打印一次測試數據集的準確率,然后將測試數據集的各種summary信息寫進日志中。
每隔100步,記錄原信息
其他每一步時都記錄下訓練集的summary信息并寫到日志中。
for i in range(max_steps):
if i % 10 == 0: # 記錄測試集的summary與accuracy
summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False))
test_writer.add_summary(summary, i)
print('Accuracy at step %s: %s' % (i, acc))
else: # 記錄訓練集的summary
if i % 100 == 99: # Record execution stats
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
summary, _ = sess.run([merged, train_step],
feed_dict=feed_dict(True),
options=run_options,
run_metadata=run_metadata)
train_writer.add_run_metadata(run_metadata, 'step%03d' % i)
train_writer.add_summary(summary, i)
print('Adding run metadata for', i)
else: # Record a summary
summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True))
train_writer.add_summary(summary, i)
train_writer.close()
test_writer.close()2.9 執行程序,tensorboard生成可視化
(1)運行整個程序,在程序中定義的summary node就會將要記錄的信息全部保存在指定的logdir路徑中了,訓練的記錄會存一份文件,測試的記錄會存一份文件。
(2)進入linux命令行,運行以下代碼,等號后面加上summary日志保存的路徑(在程序第一步中就事先自定義了)
tensorboard --logdir=
執行命令之后會出現一條信息,上面有網址,將網址在瀏覽器中打開就可以看到我們定義的可視化信息了。:
Starting TensorBoard 41 on port 6006 (You can navigate to http://127.0.1.1:6006)
將http://127.0.1.1:6006在瀏覽器中打開,成功的話如下:
于是我們可以從這個web端看到所有程序中定義的可視化信息了。
2.10 Tensorboard Web端解釋
看到最上面橙色一欄的菜單,分別有7個欄目,都一一對應著我們程序中定義信息的類型。
(1)SCALARS
展示的是標量的信息,我程序中用tf.summary.scalars()定義的信息都會在這個窗口。
回顧本文程序中定義的標量有:準確率accuracy,dropout的保留率,隱藏層中的參數信息,已經交叉熵損失。這些都在SCLARS窗口下顯示出來了。
點開accuracy,紅線表示test集的結果,藍線表示train集的結果,可以看到隨著循環次數的增加,兩者的準確度也在通趨勢增加,值得注意的是,在0到100次的循環中準確率快速激增,100次之后保持微弱地上升趨勢,直達1000次時會到達0.967左右
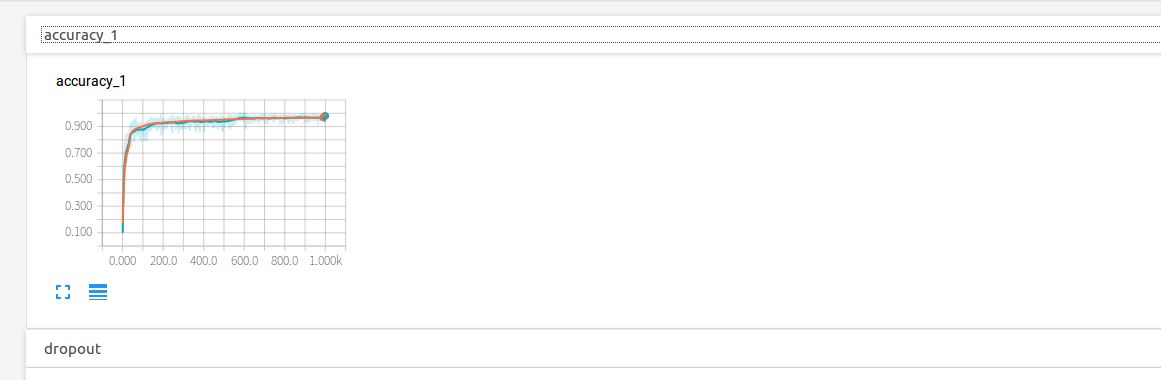
點開dropout,紅線表示的測試集上的保留率始終是1,藍線始終是0.9
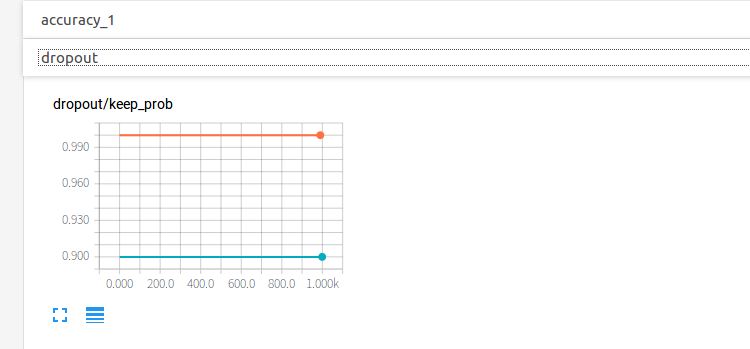
點開layer1,查看第一個隱藏層的參數信息。
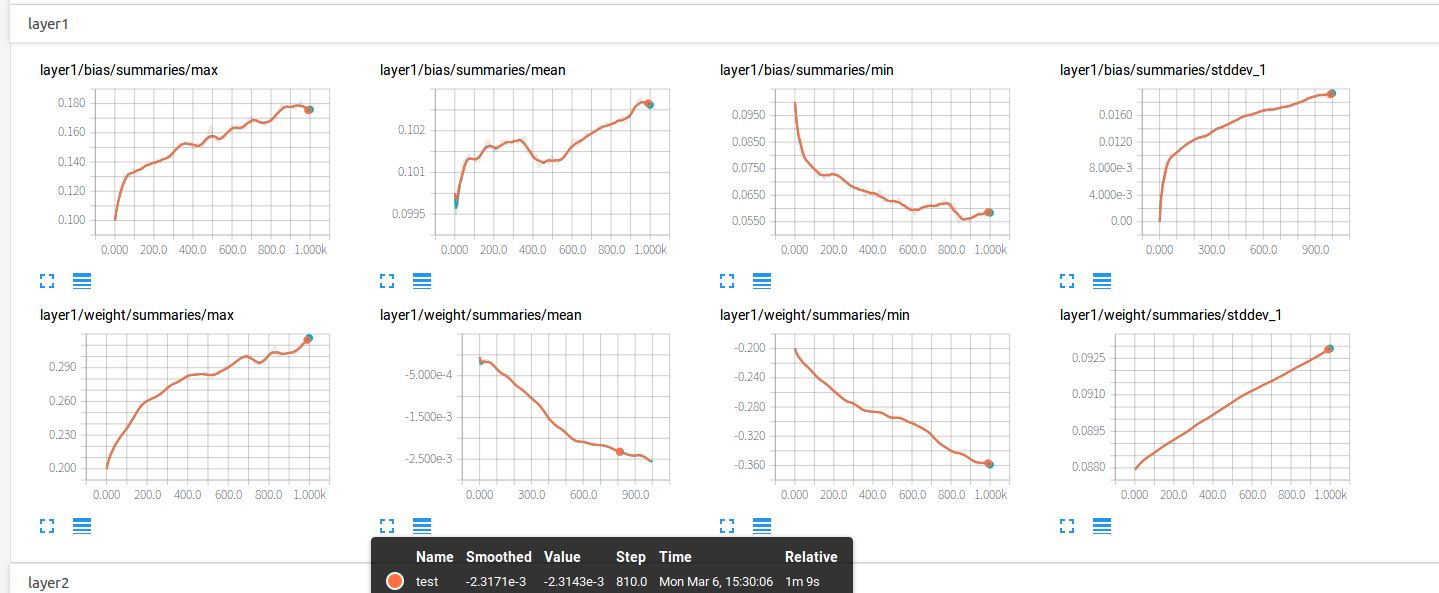
以上,第一排是偏執項b的信息,隨著迭代的加深,最大值越來越大,最小值越來越小,與此同時,也伴隨著方差越來越大,這樣的情況是我們愿意看到的,神經元之間的參數差異越來越大。因為理想的情況下每個神經元都應該去關注不同的特征,所以他們的參數也應有所不同。
第二排是權值w的信息,同理,最大值,最小值,標準差也都有與b相同的趨勢,神經元之間的差異越來越明顯。w的均值初始化的時候是0,隨著迭代其絕對值也越來越大。
點開layer2
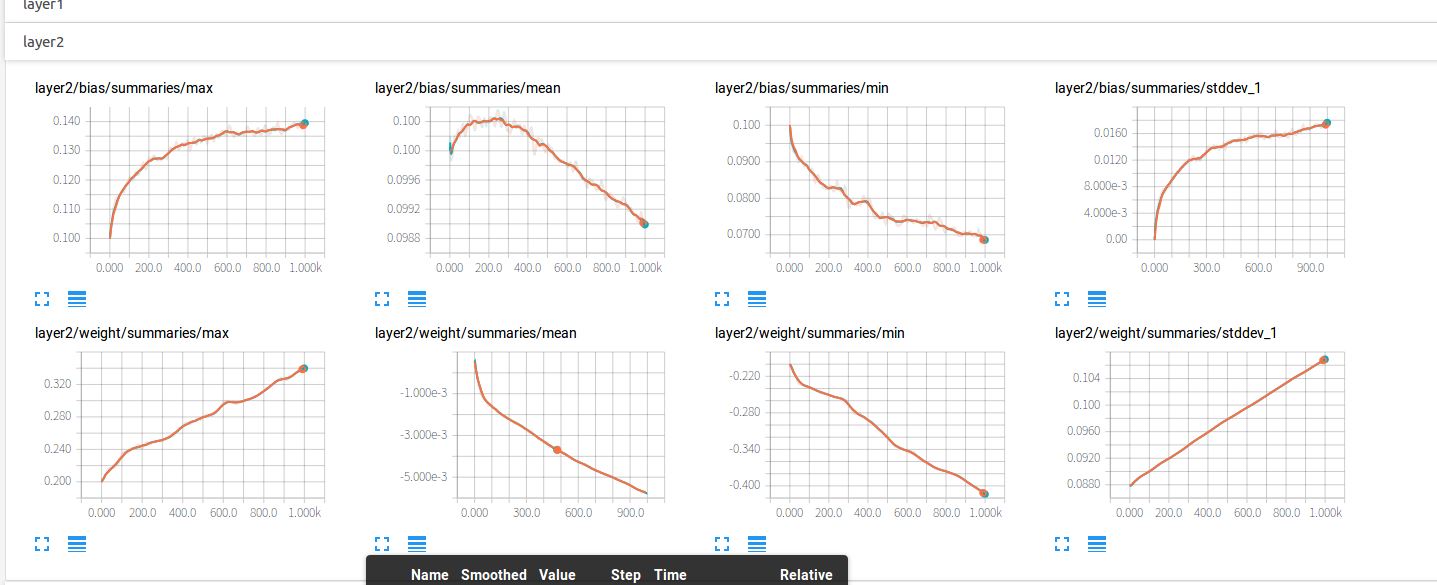
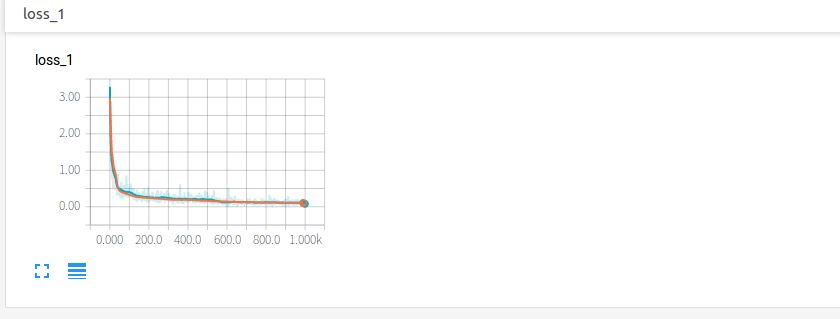
點開loss,可見損失的降低趨勢。
(2)IMAGES
在程序中我們設置了一處保存了圖像信息,就是在轉變了輸入特征的shape,然后記錄到了image中,于是在tensorflow中就會還原出原始的圖片了:
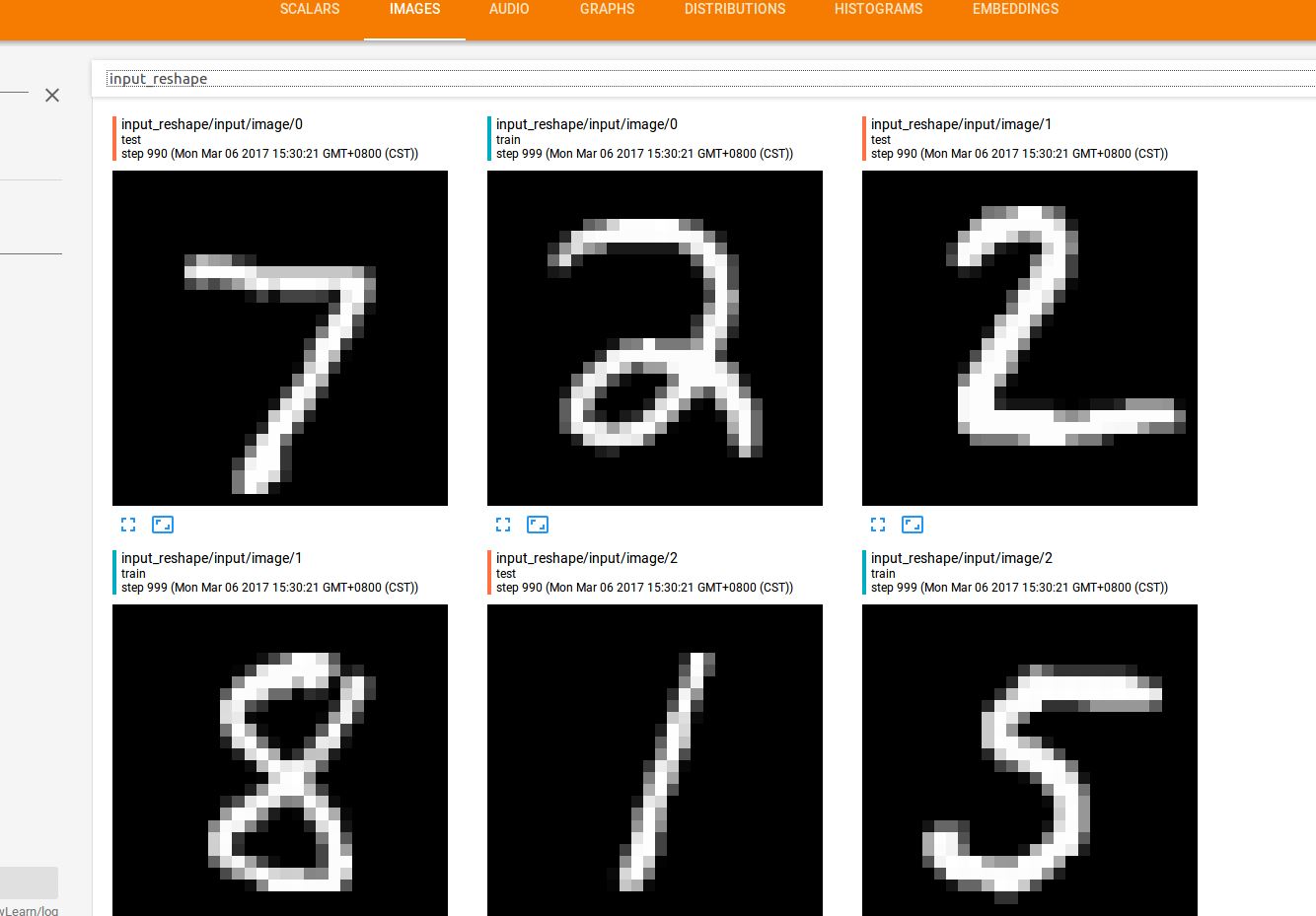
整個窗口總共展現了10張圖片(根據代碼中的參數10)
(3)AUDIO
這里展示的是聲音的信息,但本案例中沒有涉及到聲音的。
(4)GRAPHS
這里展示的是整個訓練過程的計算圖graph,從中我們可以清洗地看到整個程序的邏輯與過程。
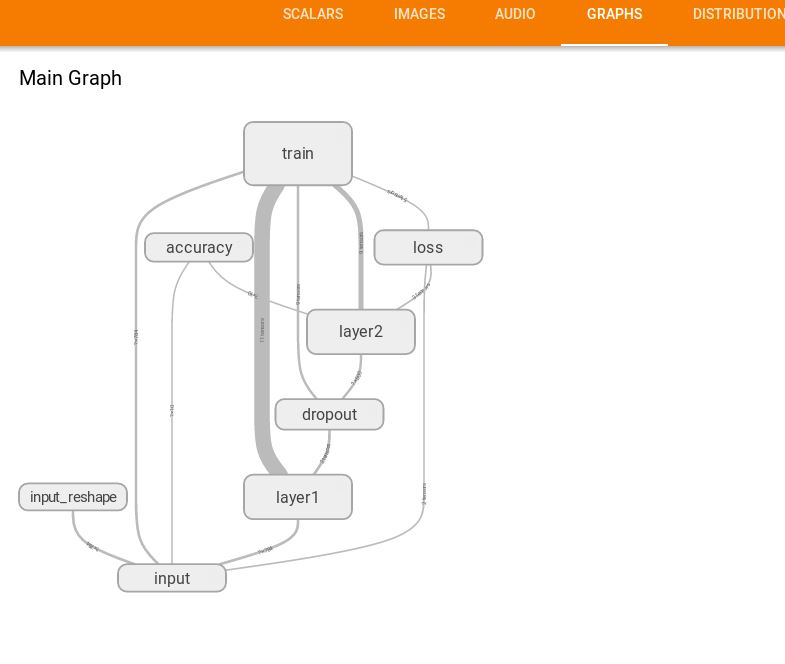
單擊某個節點,可以查看屬性,輸入,輸出等信息
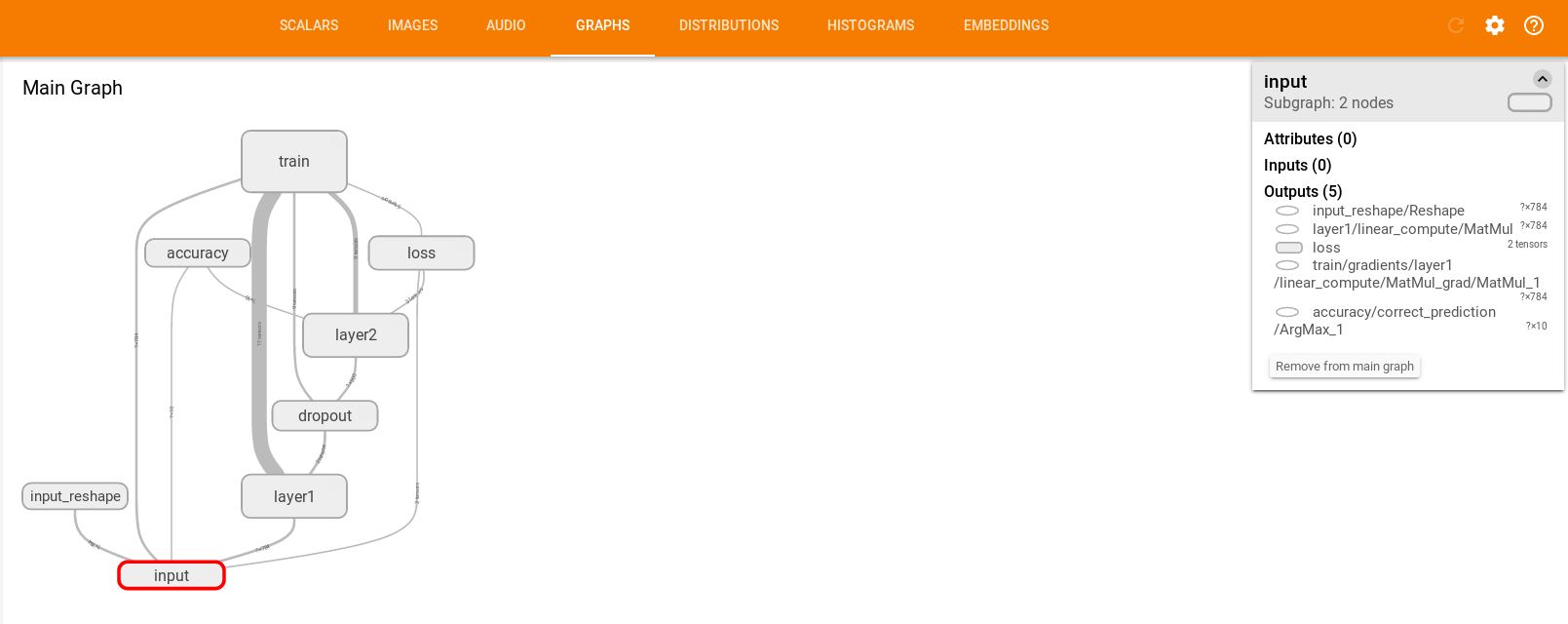
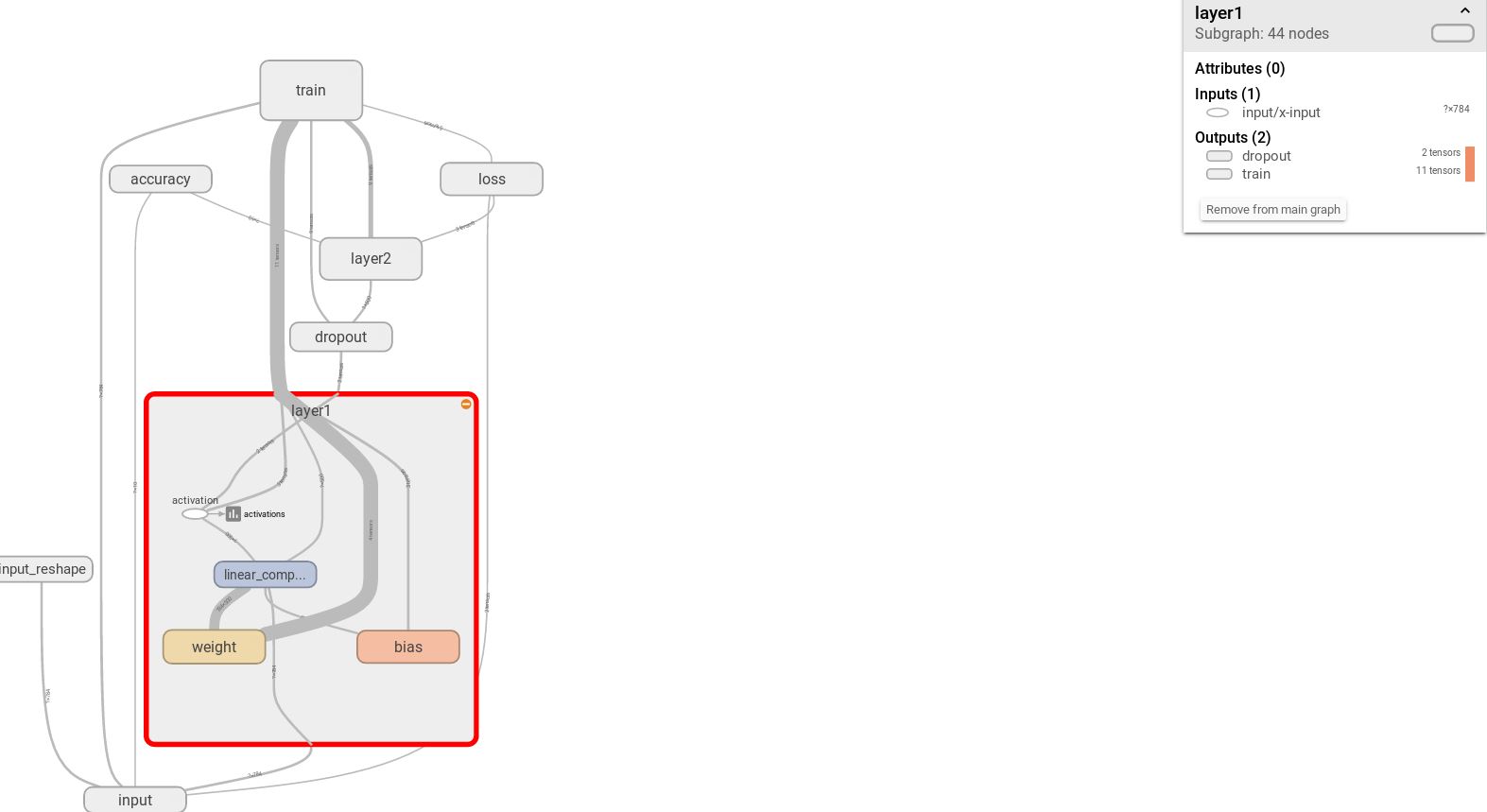
單擊節點上的“+”字樣,可以看到該節點的內部信息。
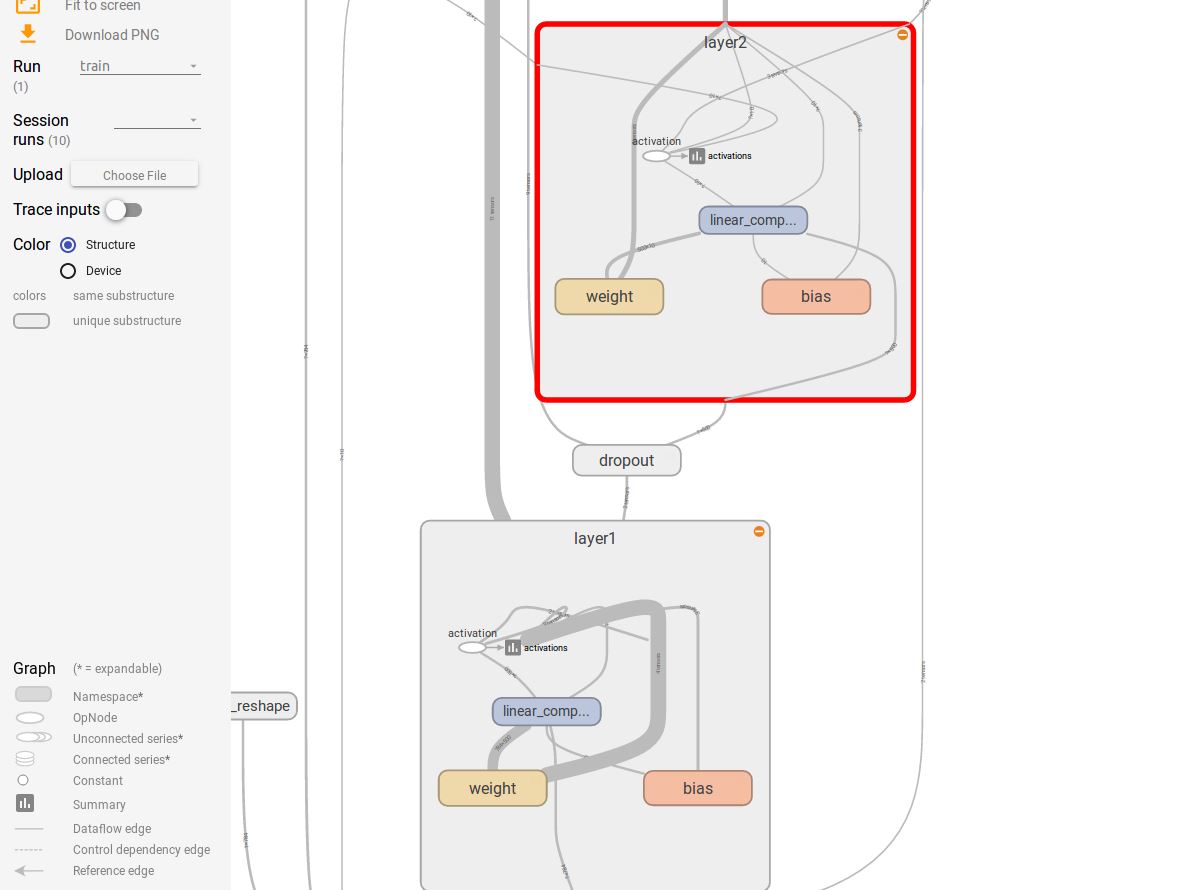
另外還可以選擇圖像顏色的兩者模型,基于結構的模式,相同的節點會有同樣的顏色,基于預算硬件的,同一個硬件上的會有相同顏色。
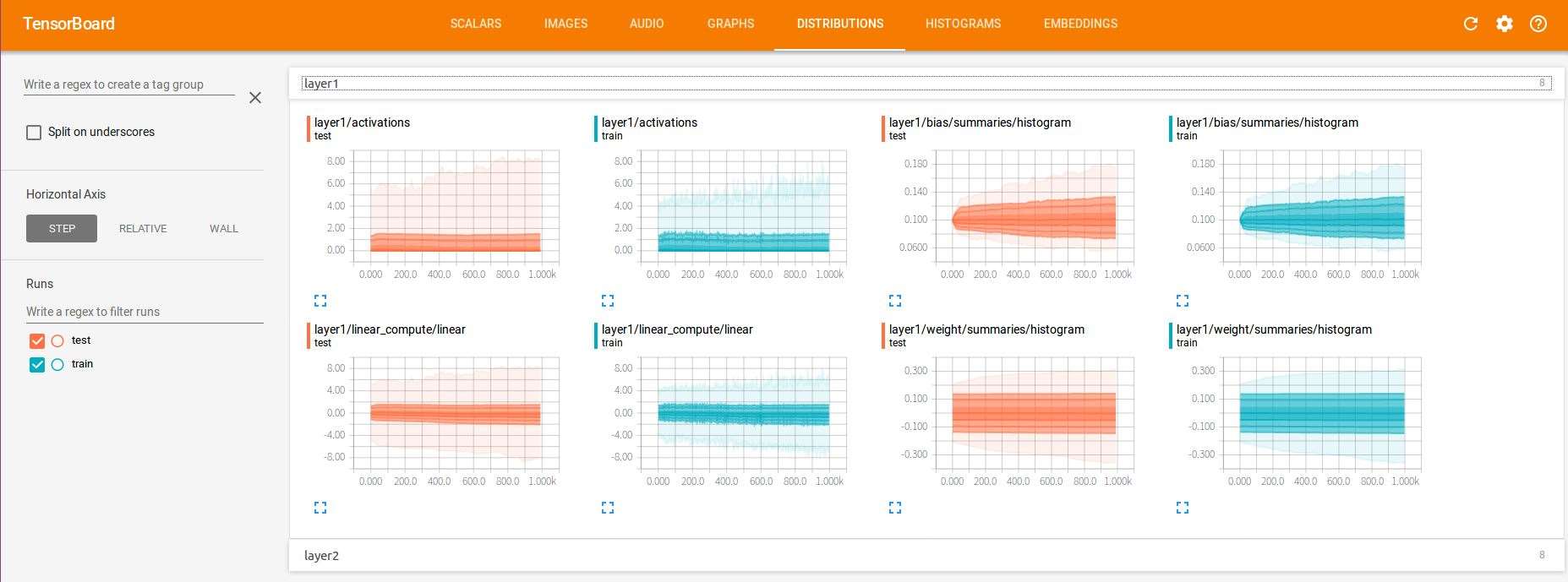
(5)DISTRIBUTIONS
這里查看的是神經元輸出的分布,有激活函數之前的分布,激活函數之后的分布等。
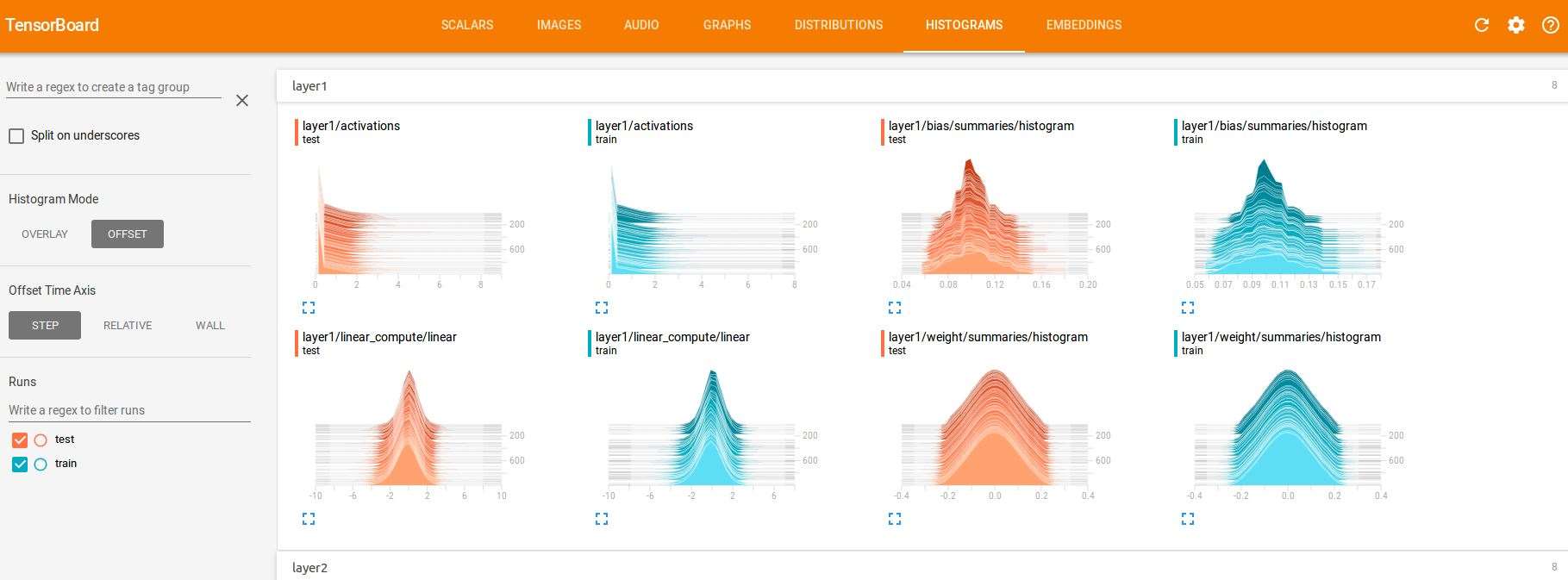
(6)HISTOGRAMS
也可以看以上數據的直方圖
以上是“Tensorflow可視化工具Tensorboard怎么用”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





