溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Selenium簡介與安裝
Selenium是什么?
Selenium也是一個用于Web應用程序測試的工具。Selenium測試直接運行在瀏覽器中,就像真正的用戶在操作一樣。支持的瀏覽器包括IE、Mozilla Firefox、Mozilla Suite等。
安裝
直接使用pip命令安裝即可!
pip install selenium
Python抓取微博有兩種方式,一是通過selenium自動登錄后從頁面直接爬取,二是通過api。
這里采用selenium的方式。
程序:
from selenium import webdriver
import time
import re
#全局變量
driver = webdriver.Chrome("C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
def loginWeibo(username, password):
driver.get('https://passport.weibo.cn/signin/login')
time.sleep(1)
driver.find_element_by_id("loginName").send_keys("haishu_zheng@163.com")
driver.find_element_by_id("loginPassword").send_keys("Weibo01061122")
time.sleep(1)
driver.find_element_by_id("loginAction").click()
#driver.close()
def visitUserPage(userId):
driver.get('http://weibo.cn/' + userId)
print('********************')
print('用戶資料')
# 1.用戶id
print('用戶id:' + userId)
# 2.用戶昵稱
strName = driver.find_element_by_xpath("http://div[@class='ut']")
strlist = strName.text.split(' ')
nickname = strlist[0]
print('昵稱:' + nickname)
# 3.微博數、粉絲數、關注數
strCnt = driver.find_element_by_xpath("http://div[@class='tip2']")
pattern = r"\d+\.?\d*" # 匹配數字,包含整數和小數
cntArr = re.findall(pattern, strCnt.text)
print(strCnt.text)
print("微博數:" + str(cntArr[0]))
print("關注數:" + str(cntArr[1]))
print("粉絲數:" + str(cntArr[2]))
print('\n********************')
# 4.將用戶信息寫到文件里
with open("weibo.txt", "w", encoding = "gb18030") as file:
file.write("用戶ID:" + userId + '\r\n')
file.write("昵稱:" + nickname + '\r\n')
file.write("微博數:" + str(cntArr[0]) + '\r\n')
file.write("關注數:" + str(cntArr[1]) + '\r\n')
file.write("粉絲數:" + str(cntArr[2]) + '\r\n')
# 5.獲取微博內容
# http://weibo.cn/ + userId + ? filter=0&page=1
# filter為0表示全部,為1表示原創
print("微博內容")
pageList = driver.find_element_by_xpath("http://div[@class='pa']")
print(pageList.text)
pattern = r"\d+\d*" # 匹配數字,只包含整數
pageArr = re.findall(pattern, pageList.text)
totalPages = pageArr[1] # 總共有多少頁微博
print(totalPages)
pageNum = 1 # 第幾頁
numInCurPage = 1 # 當前頁的第幾條微博內容
contentPath = "http://div[@class='c'][{0}]"
while(pageNum <= 3):
#while(pageNum <= int(totalPages)):
contentUrl = "http://weibo.cn/" + userId + "?filter=0&page=" + str(pageNum)
driver.get(contentUrl)
content = driver.find_element_by_xpath(contentPath.format(numInCurPage)).text
# print("\n" + content) # 微博內容,包含原創和轉發
if "設置:皮膚.圖片.條數.隱私" not in content:
numInCurPage += 1
with open("weibo.txt", "a", encoding = "gb18030") as file:
file.write("\r\n" + "\r\n" + content) # 將微博內容逐條寫到weibo.txt中
else:
pageNum += 1 # 抓取新一頁的內容
numInCurPage = 1 # 每一頁都是從第1條開始抓
if __name__ == '__main__':
username = 'haishu_zheng@163.com' # 輸入微博賬號
password = 'Weibo01061122' # 輸入密碼
loginWeibo(username, password) # 要先登錄,否則抓取不了微博內容
time.sleep(3)
uid = 'xywyw' # 尋醫問藥
visitUserPage(uid)
運行結果:
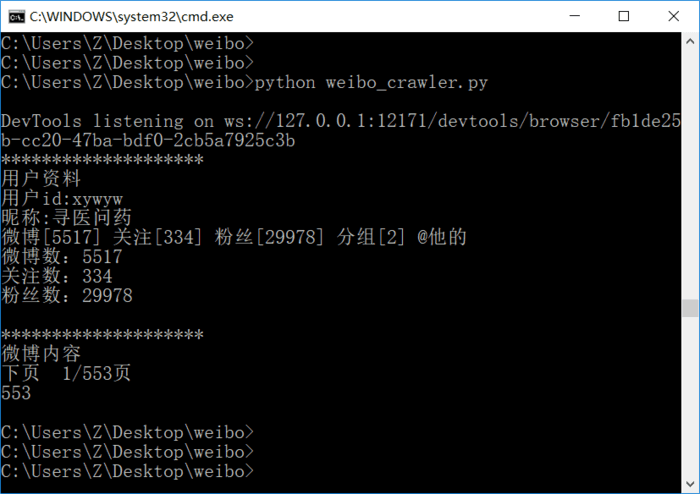
同時還生成了weibo.txt文件,內容如下
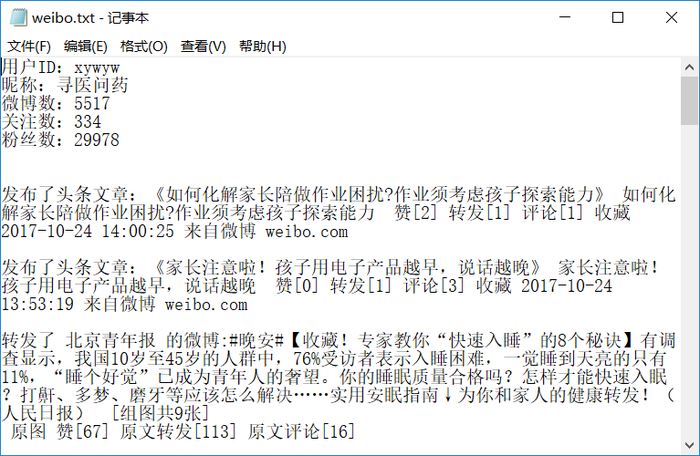
這種方法有個缺陷,就是爬取較多內容會被封IP:

以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





