溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
python中怎么實現匹配用戶評論標簽,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
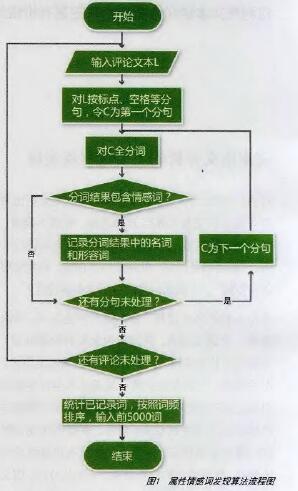
算法流程圖如下:
評論數據如下:

代碼如下:
#encoding=utf-8
#############################
#
# 功能:給定一些中文的產品評論,希望從中找到評價對象及評價詞。
#
# @author:licl
#
##############################
fdata = open('JD_DFB_comments_out.txt','r')
Output = open('Pattern_Result.txt','a')
try:
data = fdata.readlines()
listline = []
for line in data:
listline = line.replace(" ","/")
listline = listline.split("/")
i = 1
while i < len(listline):
if listline[i] != "名詞":
i = i+2
else:
new_list = ["","",""]
new_list[0] = listline[i-1]
a = i-1
i = i+2
while i < len(listline):
if listline[i] == "標點":
i = i+2
break
else:
if listline[i-1]=='不' or listline[i-1]=='不怎么樣' or listline[i-1]=='不怎么' or listline[i-1]=='不太':
new_list[1] = listline[i-1]
if listline[i] == "形容詞" or listline[i] == "形謂詞":
new_list[1] += listline[i-1]
b = i-1
t = (b-a)/2
new_list[2] = str(t)
for line in new_list:
Output.write(line + " ")
Output.write("\n")
break
else:
i = i+2
except:
print "‘文件不存在'或者‘文件無法打開'"
finally:
fdata.close()
Output.close()看完上述內容,你們掌握python中怎么實現匹配用戶評論標簽的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





