溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹使用python腳本怎么識別驗證碼,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
首先進行二值化處理。由于圖片中的噪點顏色比較淺,所以可以設定一個閾值直接過濾掉。這里我設置的閾值是150,像素大于150的賦值為1,小于的賦為0.
def set_table(a):
table = []
for i in range(256):
if i < a:
table.append(0)
else:
table.append(1)
return table
img = Image.open("D:/python/單個字體/A"+str(i)+".jpg")
pix = img.load()
#將圖片進行灰度化處理
img1 = img.convert('L')
#閾值為150,參數為1,將圖片進行二值化處理
img2 = img1.point(set_table(150),'1')處理后的圖片如下。
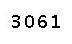
閾值不同產生的不同效果:

接下來對圖片進行分割。遍歷圖片中所有像素點,計算每一列像素為0的點的個數(jd)。對于相鄰兩列,若其中一列jd=0,而另一列jd!=0,則可以認為這一列是驗證碼中字符邊界,由此對驗證碼進行分割。這樣分割能達到比較好的效果,分割后得到的字符圖片幾乎能與模板完全相同。
(Width,Height) = img2.size pix2 = img2.load() x0 = [] y0 = [] for x in range(1,Width): jd = 0 # print x for y in range(1,Height): # print y if pix2[x,y] == 0: jd+=1 y0.append(jd) if jd > 0: x0.append(x) #分別對各個字符邊界進行判斷,這里只舉出一個 for a in range(1,Width): if (y0[a] != 0)&(y0[a+1] != 0): sta1 = a+1 break
分割完成后,對于識別,目前有幾種方法。可以遍歷圖片的每一個像素點,獲取像素值,得到一個字符串,將該字符串與模板的字符串進行比較,計算漢明距離或者編輯距離(即兩個字符串的差異度),可用Python-Levenshtein庫來實現。
我采用的是比較特征向量來進行識別的。首先設定了4個豎直特征向量,分別計算第0、2、4、6列每一列像素值為0的點的個數,與模板進行比較,若小于閾值則認為該字符與模板相同。為了提高識別率,如果通過豎直特征向量未能識別成功,引入水平特征向量繼續識別,原理與豎直特征向量相同。
另外,還可以通過局部特征進行識別。這對于加入了旋轉干擾的驗證碼有很好效果。由于我寫的腳本識別率已經達到了要求,所以并沒有用到這個。
最后的結果是這樣的:
關于使用python腳本怎么識別驗證碼就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





