溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何使用sklearn進行對數據標準化、歸一化以及將數據還原,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
在對模型訓練時,為了讓模型盡快收斂,一件常做的事情就是對數據進行預處理。
這里通過使用sklearn.preprocess模塊進行處理。
一、標準化和歸一化的區別
歸一化其實就是標準化的一種方式,只不過歸一化是將數據映射到了[0,1]這個區間中。
標準化則是將數據按照比例縮放,使之放到一個特定區間中。標準化后的數據的均值=0,標準差=1,因而標準化的數據可正可負。
二、使用sklearn進行標準化和標準化還原
原理:
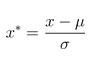
即先求出全部數據的均值和方差,再進行計算。
最后的結果均值為0,方差是1,從公式就可以看出。
但是當原始數據并不符合高斯分布的話,標準化后的數據效果并不好。
導入模塊
from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import MinMaxScaler from matplotlib import gridspec import numpy as np import matplotlib.pyplot as plt
通過生成隨機點可以對比出標準化前后的數據分布形狀并沒有發生變化,只是尺度上縮小了。
cps = np.random.random_integers(0, 100, (100, 2)) ss = StandardScaler() std_cps = ss.fit_transform(cps) gs = gridspec.GridSpec(5,5) fig = plt.figure() ax1 = fig.add_subplot(gs[0:2, 1:4]) ax2 = fig.add_subplot(gs[3:5, 1:4]) ax1.scatter(cps[:, 0], cps[:, 1]) ax2.scatter(std_cps[:, 0], std_cps[:, 1]) plt.show()
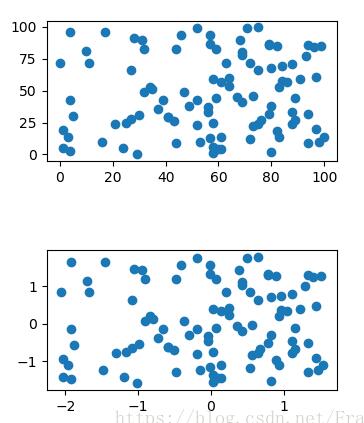
sklearn.preprocess.StandardScaler的使用:
先是創建對象,然后調用fit_transform()方法,需要傳入一個如下格式的參數作為訓練集。
X : numpy array of shape [n_samples,n_features]Training set.
data = np.random.uniform(0, 100, 10)[:, np.newaxis]
ss = StandardScaler()
std_data = ss.fit_transform(data)
origin_data = ss.inverse_transform(std_data)
print('data is ',data)
print('after standard ',std_data)
print('after inverse ',origin_data)
print('after standard mean and std is ',np.mean(std_data), np.std(std_data))通過invers_tainsform()方法就可以得到原來的數據。
打印結果如下:
可以看到生成的數據的標準差是1,均值接近0。
data is [[15.72836992] [62.0709697 ] [94.85738359] [98.37108557] [ 0.16131774] [23.85445883] [26.40359246] [95.68204855] [77.69245742] [62.4002485 ]] after standard [[-1.15085842] [ 0.18269178] [ 1.12615048] [ 1.22726043] [-1.59881442] [-0.91702287] [-0.84366924] [ 1.14988096] [ 0.63221421] [ 0.19216708]] after inverse [[15.72836992] [62.0709697 ] [94.85738359] [98.37108557] [ 0.16131774] [23.85445883] [26.40359246] [95.68204855] [77.69245742] [62.4002485 ]] after standard mean and std is -1.8041124150158794e-16 1.0
三、使用sklearn進行數據的歸一化和歸一化還原
原理:
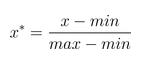
從上式可以看出歸一化的結果跟數據的最大值最小值有關。
使用時類似上面的標準化
data = np.random.uniform(0, 100, 10)[:, np.newaxis]
mm = MinMaxScaler()
mm_data = mm.fit_transform(data)
origin_data = mm.inverse_transform(mm_data)
print('data is ',data)
print('after Min Max ',mm_data)
print('origin data is ',origin_data)結果:
G:\Anaconda\python.exe G:/python/DRL/DRL_test/DRL_ALL/Grammar.py data is [[12.19502214] [86.49880021] [53.10501326] [82.30089405] [44.46306969] [14.51448347] [54.59806596] [87.87501465] [64.35007178] [ 4.96199642]] after Min Max [[0.08723631] [0.98340171] [0.58064485] [0.93277147] [0.47641582] [0.11521094] [0.59865231] [1. ] [0.71626961] [0. ]] origin data is [[12.19502214] [86.49880021] [53.10501326] [82.30089405] [44.46306969] [14.51448347] [54.59806596] [87.87501465] [64.35007178] [ 4.96199642]] Process finished with exit code 0
其他標準化的方法:
上面的標準化和歸一化都有一個缺點就是每當來一個新的數據的時候就要重新計算所有的點。
因而當數據是動態的時候可以使用下面的幾種計算方法:
1、arctan反正切函數標準化:
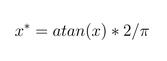
2、ln函數標準化
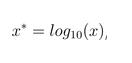
關于“如何使用sklearn進行對數據標準化、歸一化以及將數據還原”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





