溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關MySQL中 Innodb索引的原理是什么,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
什么是索引?
索引(index)翻譯為一個目錄,用于快速定位我們想要找的數據的位置。例如:我們把一個數據庫比作一本書,而索引(index)就是書中的目錄,此刻要找到書的某個感興趣的內容,我們一般是不會整本書翻完再去確認該內容在哪里,而是通過書的目錄,定位到該內容章節所在頁數,最后直接翻到該頁面。
我們來看看在數據庫中的索引:
全表掃描 VS 索引掃描
以字典為例,全表掃描就是如果我們查找某個字時,那么通讀一遍新華字典,然后找到我們想要找到的字,而跟全表掃描相對應的就是索引查找,索引查找就是在表的索引部分找到我們想要找的數據具體位置,然后會到表里面將我們想要找的數據全部查出。
OK,廢話不多說,開始啰嗦!
正文
索引的科普
先引進聚簇索引和非聚簇索引的概念!
我們平時在使用的Mysql中,使用下述語句
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [USING index_type] ON tbl_name (index_col_name,...) index_col_name: col_name [(length)] [ASC | DESC]
創建的索引,如復合索引、前綴索引、唯一索引,都是屬于非聚簇索引,在有的書籍中,又將其稱為輔助索引(secondary index)。在后文中,我們稱其為非聚簇索引,其數據結構為B+樹。
那么,這個聚簇索引,在Mysql中是沒有語句來另外生成的。在Innodb中,Mysql中的數據是按照主鍵的順序來存放的。那么聚簇索引就是按照每張表的主鍵來構造一顆B+樹,葉子節點存放的就是整張表的行數據。由于表里的數據只能按照一顆B+樹排序,因此一張表只能有一個聚簇索引。
在Innodb中,聚簇索引默認就是主鍵索引。
這個時候,機智的讀者,應該要問我
如果我的表沒建主鍵呢?
回答是,如果沒有主鍵,則按照下列規則來建聚簇索引
沒有主鍵時,會用一個唯一且不為空的索引列做為主鍵,成為此表的聚簇索引如果沒有這樣的索引,InnoDB會隱式定義一個主鍵來作為聚簇索引。
ps:大家還記得,自增主鍵和uuid作為主鍵的區別么?由于主鍵使用了聚簇索引,如果主鍵是自增id,,那么對應的數據一定也是相鄰地存放在磁盤上的,寫入性能比較高。如果是uuid的形式,頻繁的插入會使innodb頻繁地移動磁盤塊,寫入性能就比較低了。
索引原理介紹
先來一張帶主鍵的表,如下所示,pId是主鍵
| pId | name | birthday |
|---|---|---|
| 5 | zhangsan | 2016-10-02 |
| 8 | lisi | 2015-10-04 |
| 11 | wangwu | 2016-09-02 |
| 13 | zhaoliu | 2015-10-07 |
畫出該表的結構圖如下
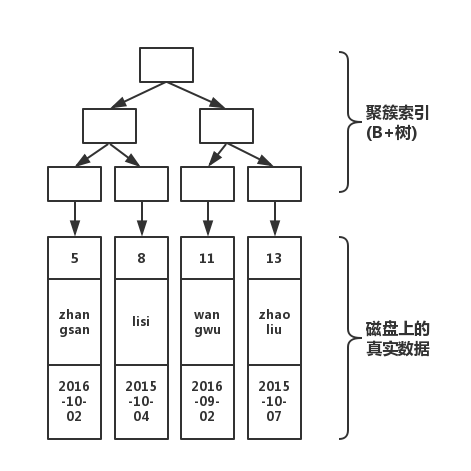
如上圖所示,分為上下兩個部分,上半部分是由主鍵形成的B+樹,下半部分就是磁盤上真實的數據!那么,當我們, 執行下面的語句
select * from table where pId='11'
那么,執行過程如下
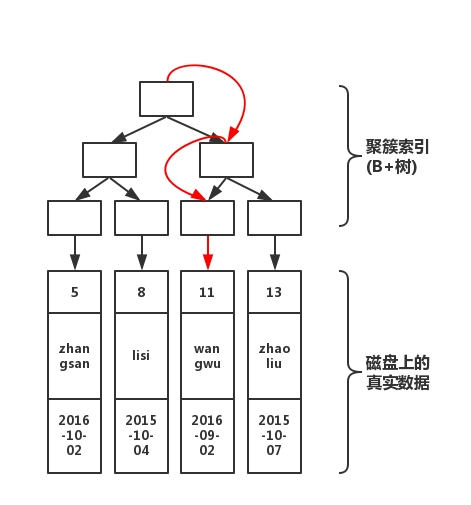
如上圖所示,從根開始,經過3次查找,就可以找到真實數據。如果不使用索引,那就要在磁盤上,進行逐行掃描,直到找到數據位置。顯然,使用索引速度會快。但是在寫入數據的時候,需要維護這顆B+樹的結構,因此寫入性能會下降!
OK,接下來引入非聚簇索引!我們執行下面的語句
create index index_name on table(name);
此時結構圖如下所示
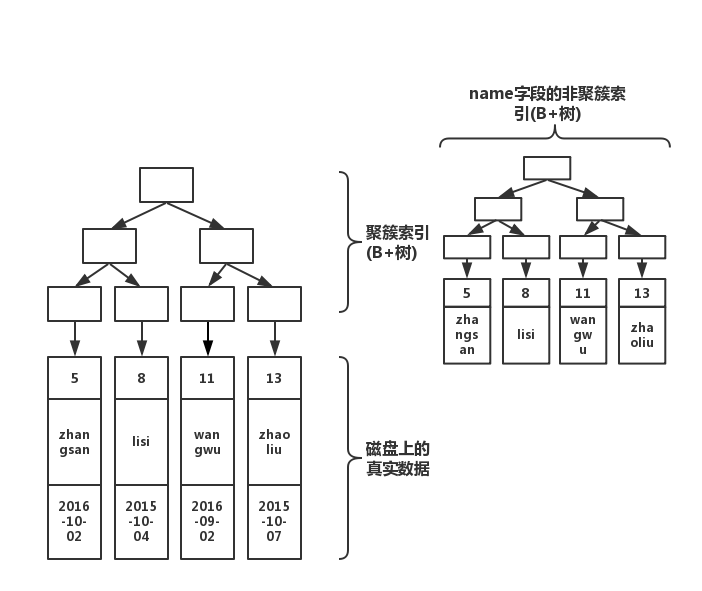
大家注意看,會根據你的索引字段生成一顆新的B+樹。因此, 我們每加一個索引,就會增加表的體積, 占用磁盤存儲空間。然而,注意看葉子節點,非聚簇索引的葉子節點并不是真實數據,它的葉子節點依然是索引節點,存放的是該索引字段的值以及對應的主鍵索引(聚簇索引)。
如果我們執行下列語句
select * from table where name='lisi'
此時結構圖如下所示
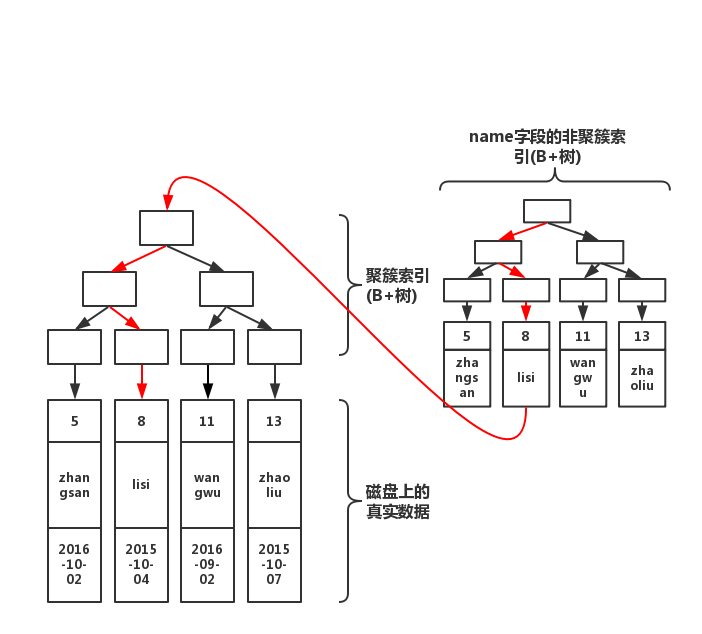
通過上圖紅線可以看出,先從非聚簇索引樹開始查找,然后找到聚簇索引后。根據聚簇索引,在聚簇索引的B+樹上,找到完整的數據!
那
什么情況不去聚簇索引樹上查詢呢?
還記得我們的非聚簇索引樹上存著該索引字段的值么。如果,此時我們執行下面的語句
select name from table where name='lisi'
此時結構圖如下
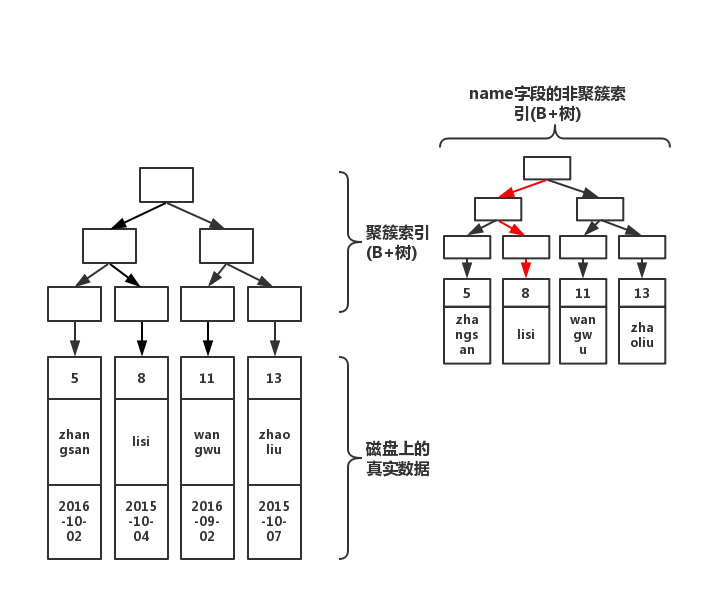
如上圖紅線所示,如果在非聚簇索引樹上找到了想要的值,就不會去聚簇索引樹上查詢。還記得,博主在《select的正確姿勢》提到的索引問題么:
當執行select col from table where col = ?,col上有索引的時候,效率比執行select * from table where col = ? 速度快好幾倍!
看完上面的圖,你應該對這句話有更深層的理解了。
那么這個時候,我們執行了下述語句,又會發生什么呢?
create index index_birthday on table(birthday);
此時結構圖如下
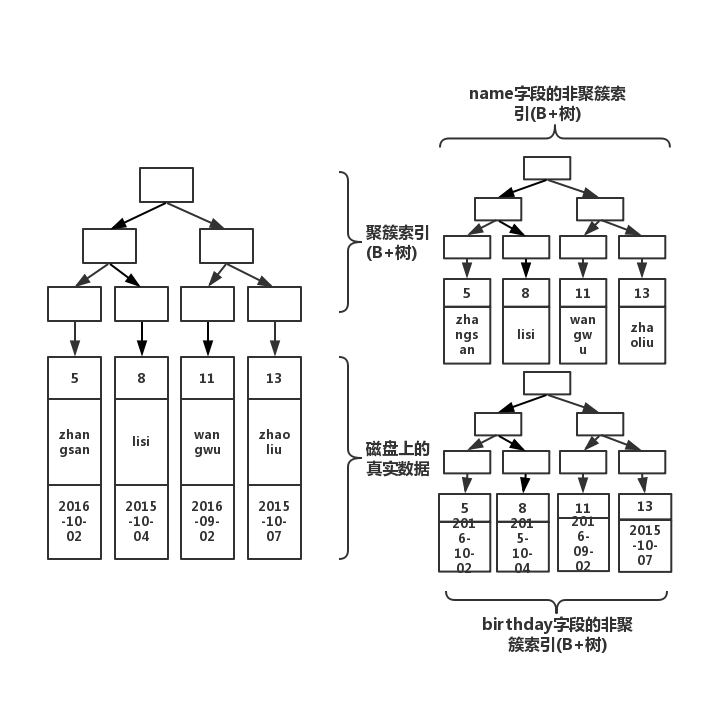
以上就是MySQL中 Innodb索引的原理是什么,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





