溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“如何安裝配置hadoop”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“如何安裝配置hadoop”吧!
由于我的java系統是已經安裝完畢,而且是1.8版本滿足hadoop要求,只要將java home 指向安裝的目錄即可
先要取得java的安裝目錄
先取得java命令路徑,命令路徑頭就是java的安裝目錄
ll了兩次都是軟鏈接,最后在/usr/lib...下找到了java的目錄,目錄我們只要復制到jre即可,多了少了都報錯。
vim /etc/profile #配置java home
#------------------------
# properties jdk
#------------------------
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64/jre
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar:${JRE_HOME}/lib
export PATH=${PATH}:${JAVA_HOME}/bin:${JRE_HOME}/binhttp://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz
#下載地址
mkdir /hadoop/
#創建hadoop 文件夾,將上面的文件下載到該文件夾,并解壓
ln -s hadoop-3.1.2 hadoop.soft
#創建個軟連接文件
vim /etc/profile #配置 hadoop home
#---------------------------
# property hadoop
#------------------------
export HADOOP_HOME=/hadoop/hadoop.soft
export PATH=${PATH}:${HADOOP_HOME}/sbin:${HADOOP_HOME}/binsource /etc/profile
#重載下配置文件
hadoop version
#執行hadoop 驗證命令,如果出現以下字符說明安裝成功了
cd /hadoop/hadoop.soft/etc/hadoop #進入配置文件文件夾
需要修改的以下文件
slaves
hadoop-env.sh
yarn-en.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
1.修改slaves
vim slaves
Slave1 Slave2 #兩個子節點
2.修改hadoop-env.sh,JAVA_HOME=$JAVA_HOME這一行,把它注釋掉,另外增加一行,添加內容。export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64/jre
#添加java home的路徑
3.修改yarn-env.sh,JAVA_HOME=$JAVA_HOME這一行,把它注釋掉,另外增加一行,添加內容。export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64/jre
4.修改core-site.xml,在<configuration> </configuration>之間添加內容。
<property> <name>hadoop.tmp.dir</name> <value>/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.default.name</name> <value>hdfs://Master:9000</value> #這里填主機的host </property>
5.修改hdfs-site.xml,同樣在<configuration></configuration>之間添加內容。
<property> <name>dfs.namenode.secondary.http-address</name> <value>Master:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/hadoop/dfs/date</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property>
6.修改mapred-site.xml文件,配置文件中沒有這個文件,首先需要將mapred-site.xml.tmporary文件改名為mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>Master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>Master:19888</value> </property>
7.修改yarn-site.xml
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>Master</value> </property>
在把需要的文件夾創建下
cd /hadoop
mkdir -pv tmp
mkdir -pv dfs/{name,date}
在把整個文件夾傳送給兩個子節點,保證所有節點的文件文件路徑都一樣,java 和hadoop 的home也配置成一樣,主節點怎么配子節點一樣配
scp -r /hadoop Slave1:/ #將整個hadoop文件夾復制一份給節點1
scp -r /hadoop Slave2:/
四,格式化節點,啟動hadoop
hdfs namenode -format #格式化節點
這一步,在配置完所有文件后,開啟hdfs,star-dfs.sh之前。只使用一次,之后每次開啟hadoop都不需要,格式化名稱節點,如果沒有格式化名稱節點,就啟動hadoop,start-dfs.sh,后面會出問題。
解決方法:
關閉hdfs,把tmp,logs文件刪除,重新格式化namenode
stop-all.sh #關閉所有節點
rm -rf tmp
rm -rf logs
hdfs namenode -format
啟動節點
su hadoop #切換到hadoop賬號
start-all.sh #啟動所有有節點
netstat -nltp #查看監聽端口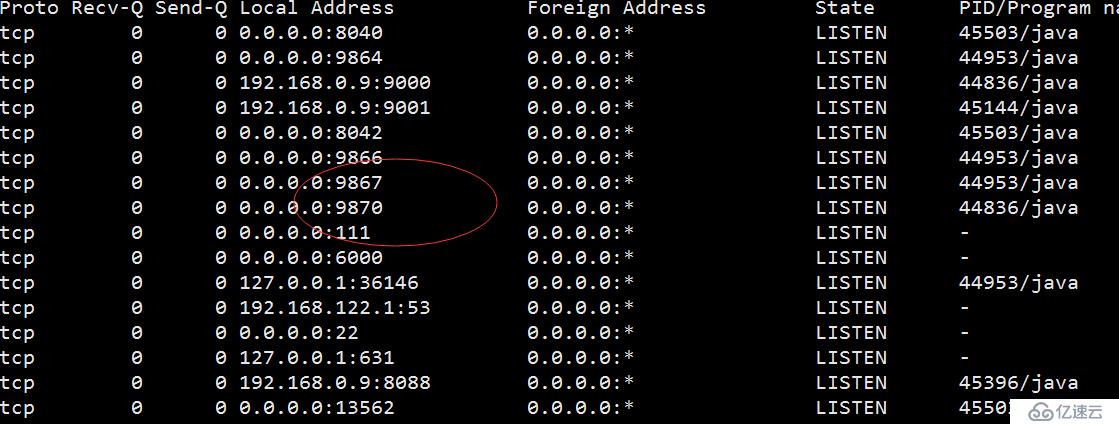
訪問9870端口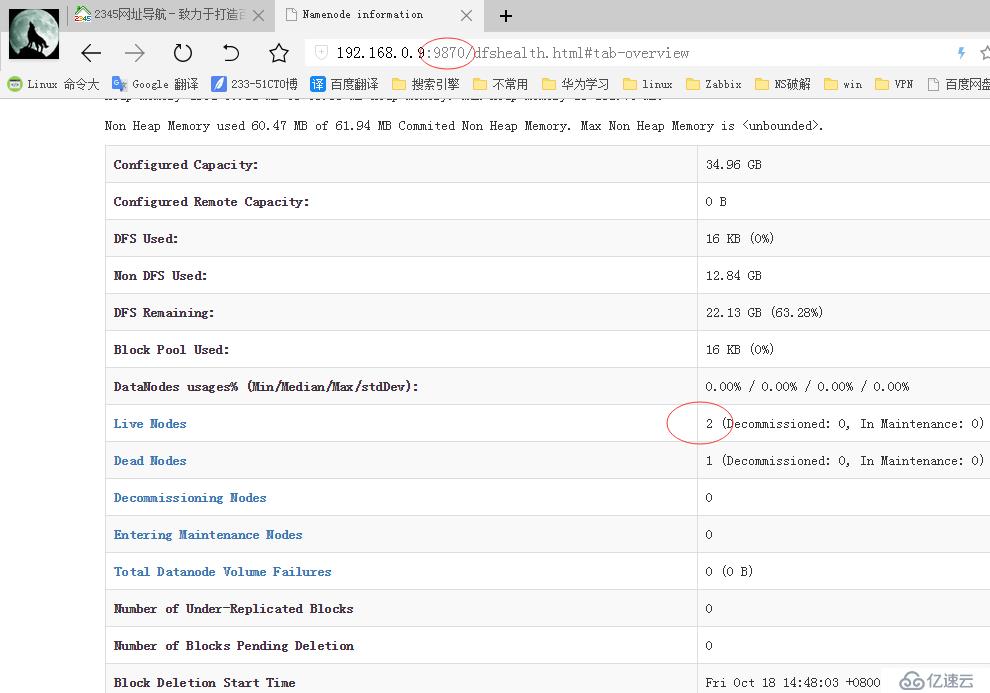
我這有兩個節點在線,另一個我關閉測試的,如果花紅圈的地方只有一個主節點的話
可以登錄到子節點 運行以下命令,在子節點上啟動
su hadoop
hadoop-daemon.sh start datanode #啟動本機節點
hadoop fs -mkdir /666 新建文件夾
hdfs dfs -put test.txt /666 上傳文件
hadoop fs -ls / 查看根目錄
hadoop fs -rmr /666 刪除666目錄
上傳一張圖片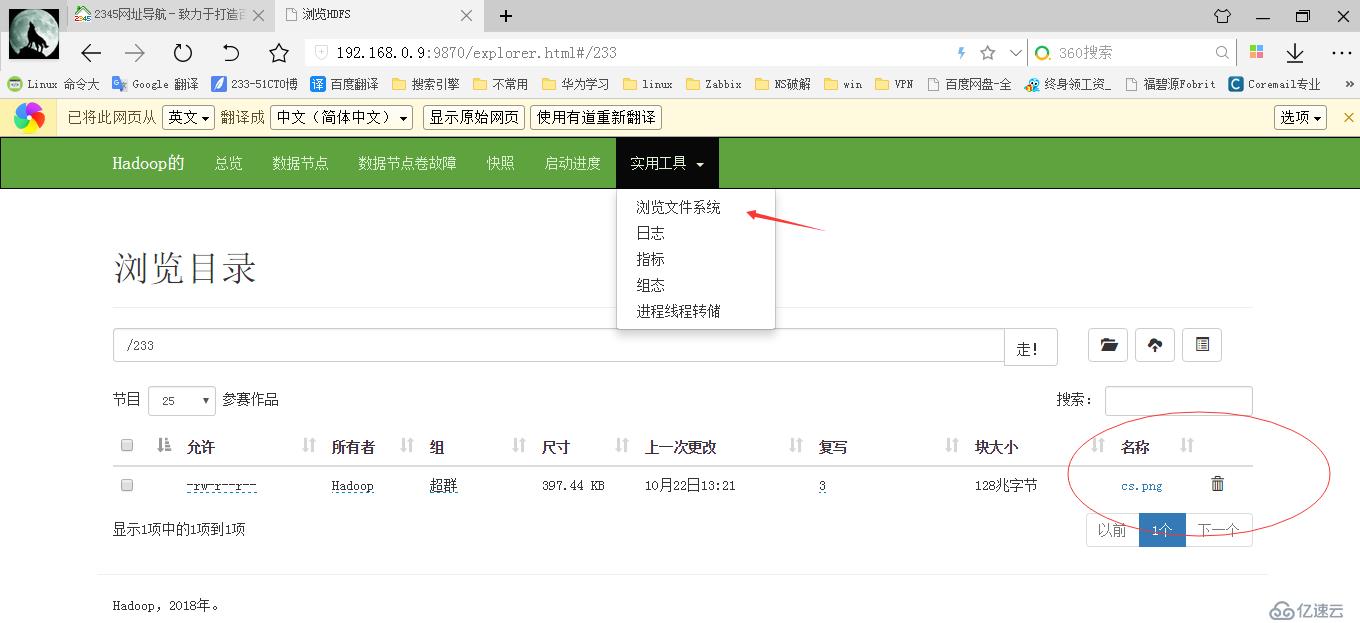
到瀏覽器上看看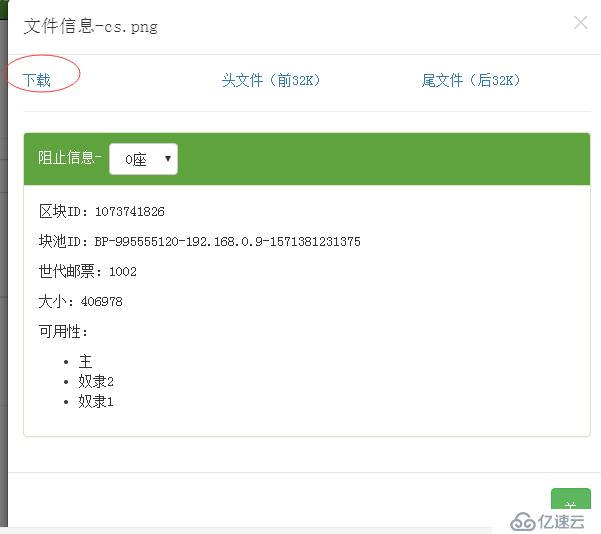
下載下來看看
感謝各位的閱讀,以上就是“如何安裝配置hadoop”的內容了,經過本文的學習后,相信大家對如何安裝配置hadoop這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





