溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
針對排序來說,order by 是我們使用非常頻繁的關鍵字。結合之前我們對索引的了解再來看這篇文章會讓我們深刻理解在排序的時候,是如何利用索引來達到少掃描表或者使用外部排序的。
先定義一個表輔助我們后面理解:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `city` varchar(16) NOT NULL, `name` varchar(16) NOT NULL, `age` int(11) NOT NULL, `addr` varchar(128) DEFAULT NULL, PRIMARY KEY (`id`), KEY `city` (`city`) ) ENGINE=InnoDB;
這時我們寫一條查詢語句
select city,name,age from t where city='杭州' order by name limit 1000 ;
根據上面的表定義來看,city=xxx 可以使用到我們定義的一個索引。但是 order by name 明顯我們沒有索引,所以肯定需要先用索引查詢到 city=xxx 然后再進行回表查詢,最后再排序。
全字段排序
在 city 字段上面創建索引之后,我們使用執行計劃來查看這個語句

可以看到有索引的情況下 我們這里還是使用了 "Using filesort" 表示需要排序,MySQL 會給每個線程分配一塊內存用于排序 稱為 sort_buffer。
我們在執行上面 select 語句的時候通常經歷了這樣一個過程
1. 初始化 sort_buffer, 確認放入 name, city, age 這三個字段。
2. 從索引 city 找到第一個滿足 city='杭州'條件的主鍵 id。
3. 回表取到 name, city, age 三個字段值,存入 sort_buffer 中。
4. 從索引 city 取下一個主鍵 id 記錄。
5. 重復 3-4 步驟,直到 city 不滿足條件。
6. 對 sort_buffer 中的數據按照字段 name 做快速排序。
7. 排序結果取前 1000 行返回給客戶端。
這被我們稱為全字段排序。
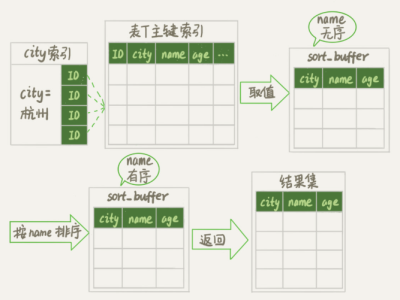
按照 name 排序這個動作即可能在內存中完成,也可以能使用外部文件排序。這取決于 sort_buffer_size 。sort_buffer_size 的默認值是1048576 byte 也就是 1M,如果要排序的數據量小于 1m 排序就在內存中完成,如果排序數據量大,內存放不下,則使用磁盤臨時文件輔助排序。
Rowid 排序
如果單行很大,需要的字段全部放進 sort_buffer 效果就不會很好。
MySQL 中專門用于控制排序的行數據長度有個參數 max_length_for_sort_data 默認是1024,如果超過了這個值就會使用 rowid 排序。那么執行上面語句的流程就變成了
1. 初始化 sort_buffe 確定放入兩個字段即 name 和 id 。
2. 從索引 city 找到第一個滿足 city = '杭州'條件的主鍵 id。
3. 回表取 name 和 id 兩個字段 存入 sort_buffer 中。
4. 取下個滿足條件的記錄 重復 2 3 步驟。
5. 對 sort_buffer 中的 name 進行排序。
6.遍歷結果取前 1000 行。然后按照 id 再回一次表取的結果字段返回給客戶端。
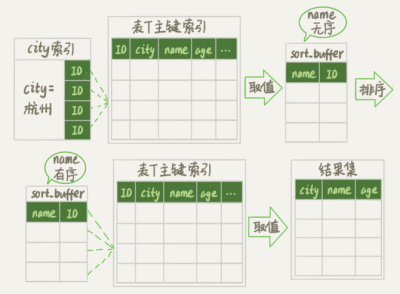
其實并不是所有 oder by 語句都需要進行上面的二次排序操作。從上面分析的執行過程,我們可以注意到。MySQL 之所以需要生成臨時表,是因為要在臨時表上做排序,是因為之前我們取得的是數據是無序的。
如果我們對剛才的索引修改一下,使得他是一個聯合索引,那么第二個字段我們拿到的值其實就是有序的了。
聯合索引滿足這么一個條件,當我們的第一個索引字段是相等的情況下,第二個字段是有序的。
這能保證如果我們建立 (city,name) 索引的話,當我們在搜索 city='杭州'的情況的是時候找到的目標第二個字段 name 其實是有序的。所以查詢過程可以簡化成。
1. 從索引 (city, name) 找到第一個滿足 city = '杭州'條件的主鍵 id 。
2. 回表取到 name city age 三個值返回。
3. 取下一個 id 。
4. 重復2 3 兩個步驟直到 1000 條記錄,或者是不滿足 city = '杭州'條件結束。
也因為查詢過程都可以使用到索引的有序性,所以不再需要排序也不需要時使用 sort buffer 了。
更近一步的優化就是之前說過的索引覆蓋,將需要查詢的字段也覆蓋進索引中,再省掉回表的步驟,可以讓整個查詢的速度更快。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





