溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
python之冒泡排序
概念: 重復地走訪過要排序的元素列,依次比較兩個相鄰的元素,如果他們的順序(如從大到小、首字母從A到Z)錯誤就把他們交換過來。走訪元素的工作是重復地進行直到沒有相鄰元素需要交換,也就是說該元素已經排序完成
這個算法的名字由來是因為越大的元素會經由交換慢慢“浮”到數列的頂端(升序或降序排列),就如同碳酸飲料中二氧化碳的氣泡最終會上浮到頂端一樣,故名“冒泡排序”。

算法原理
冒泡排序算法的原理如下:
比較相鄰的元素。如果第一個比第二個大,就交換他們兩個。
對每一對相鄰元素做同樣的工作,從開始第一對到結尾的最后一對。在這一點,最后的元素應該會是最大的數。
針對所有的元素重復以上的步驟,除了最后一個。
持續每次對越來越少的元素重復上面的步驟,直到沒有任何一對數字需要比較。
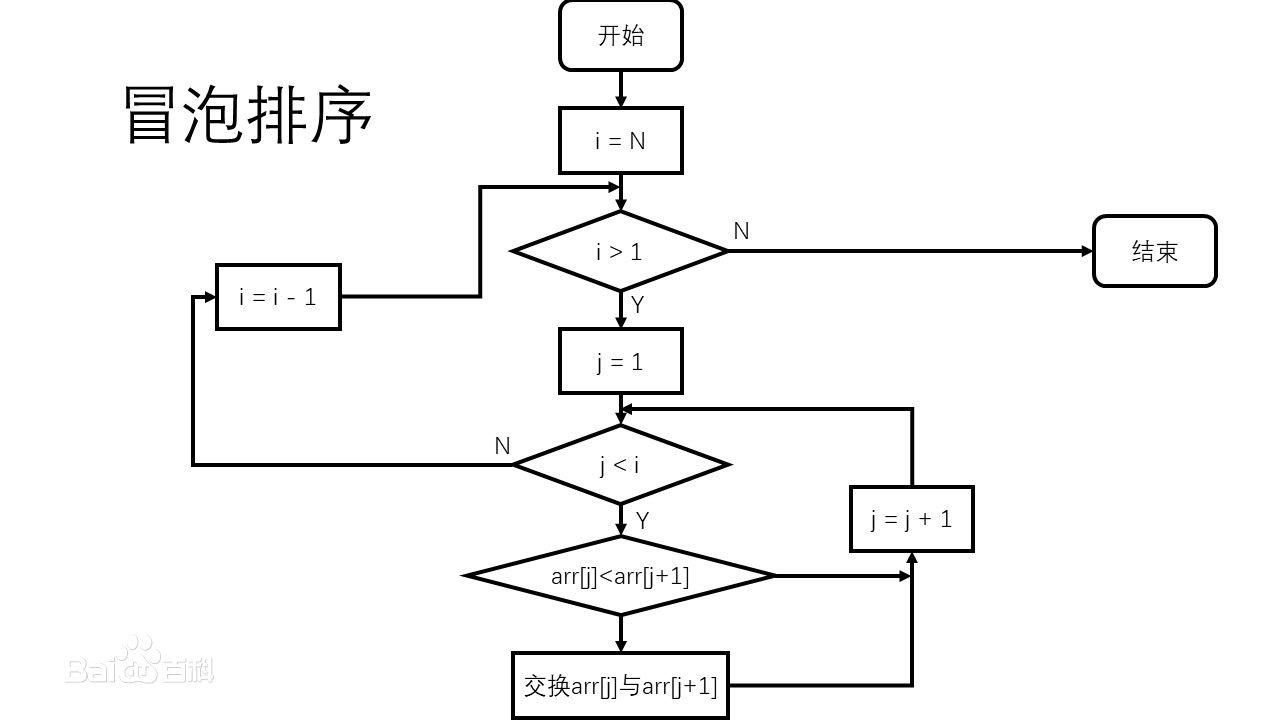
算法分析
時間復雜度
若文件的初始狀態是正序的,一趟掃描即可完成排序。所需的關鍵字比較次數
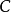 和記錄移動次數
和記錄移動次數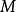 均達到最小值:
均達到最小值: ,
,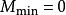 。
。
所以,冒泡排序最好的時間復雜度為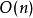 。
。
冒泡排序的最壞時間復雜度為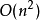
代碼實現
偽代碼
function bubble_sort (array, length) {
var i, j;
for(i from 1 to length-1){
for(j from 0 to length-1-i){
if (array[j] > array[j+1])
swap(array[j], array[j+1])
}
}
}
偽代碼解釋
函數 冒泡排序 輸入 一個數組名稱為array 其長度為length
i 從 1 到 (length - 1)
j 從 0 到 (length - 1 - i)
如果 array[j] > array[j + 1]
交換 array[j] 和 array[j + 1] 的值
如果結束
j循環結束
i循環結束
函數結束
助記碼
i∈[0,N-1) //循環N-1遍 j∈[0,N-1-i) //每遍循環要處理的無序部分 swap(j,j+1) //兩兩排序(升序/降序)
python代碼
#-*-coding:utf-8-*-
'''冒泡排序也稱 bubble sort從小到大排序'''
import time
def bubble_sort(lst):
'''冒泡排序'''
# 第一次循環
for n in range(len(lst) - 1, 0, -1): #計算原列表的長度-1,取倒序索引
for i in range(n):
if lst[i] > lst[i + 1]: # 比較最后一個與倒數第二個數的值,如果倒數第二個的值,大于最后一個的值
temp = lst[i] # 則將倒數第二個值賦值給臨時變量temp
lst[i] = lst[i + 1] # 替換原列表中倒數第二個索引的值為最后一個
lst[i + 1] = temp # 同時改變原列表中最后一個索引值為倒數第二個的值
return lst
if __name__ == "__main__":
lst = [54, 26, 93, 17, 77, 31, 44, 55, 20]
af_sort=bubble_sort(lst)
print(af_sort)
總結冒泡排序的實現(類似下面)通常會對已經排序好的數列拙劣地運行(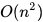 ),而插入排序在這個例子只需要
),而插入排序在這個例子只需要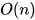 個運算。算法的核心知識點是: 循環比較, 交叉換位!
個運算。算法的核心知識點是: 循環比較, 交叉換位!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





