溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了UNION和UNION ALL怎么在MySQL中使用,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
MySQL中的UNION
UNION在進行表鏈接后會篩選掉重復的記錄,所以在表鏈接后會對所產生的結果集進行排序運算,刪除重復的記錄再返回結果。實際大部分應用中是不會產生重復的記錄,最常見的是過程表與歷史表UNION。如:
select * from gc_dfys union select * from ls_jg_dfys
這個SQL在運行時先取出兩個表的結果,再用排序空間進行排序刪除重復的記錄,最后返回結果集,如果表數據量大的話可能會導致用磁盤進行排序。
MySQL中的UNION ALL
而UNION ALL只是簡單的將兩個結果合并后就返回。這樣,如果返回的兩個結果集中有重復的數據,那么返回的結果集就會包含重復的數據了。
從效率上說,UNION ALL 要比UNION快很多,所以,如果可以確認合并的兩個結果集中不包含重復的數據的話,那么就使用UNION ALL,如下:
select * from gc_dfys union all select * from ls_jg_dfys
使用Union,則所有返回的行都是唯一的,如同您已經對整個結果集合使用了DISTINCT,若果多表查詢結果中有完全一致的數據,mysql將自動去重
使用Union all,則不會排重,返回所有的行
如果您想使用ORDER BY或LIMIT子句來對全部UNION結果進行分類或限制,則應對單個地SELECT語句加圓括號,并把ORDER BY或LIMIT放到最后一個的后面:
(SELECT a FROM tbl_name WHERE a=10 AND B=1) UNION (SELECT a FROM tbl_name WHERE a=11 AND B=2) ORDER BY a LIMIT 10;
麻煩一點也可以這么干:
select userid from ( select userid from testa union all select userid from testb) t order by userid limit 0,1;
在子句中。order by 配合limit使用才有意義,如果不配合使用,將被語法分析器優化時除去
如果你還想group by,而且還有條件,那么:
select userid from (select userid from testa union all select userid from testb) t group by userid having count(userid) = 2;
注意:在union的括號后面必須有個別名,否則會報錯
當然了,如果當union的幾個表的數據量很大時,建議還是采用先導出文本,然后用腳本來執行
因為純粹用sql,效率會比較低,而且它會寫臨時文件,如果你的磁盤空間不夠大,就有可能會出錯
Error writing file '/tmp/MYLsivgK' (Errcode: 28)
例子:
DROP TABLE IF EXISTS `ta`;
CREATE TABLE `ta` (
`id` varchar(255) DEFAULT NULL,
`num` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of ta
-- ----------------------------
INSERT INTO `ta` VALUES ('a', '5');
INSERT INTO `ta` VALUES ('b', '10');
INSERT INTO `ta` VALUES ('c', '15');
INSERT INTO `ta` VALUES ('d', '10');
-- ----------------------------
-- Table structure for `tb`
-- ----------------------------
DROP TABLE IF EXISTS `tb`;
CREATE TABLE `tb` (
`id` varchar(255) DEFAULT NULL,
`num` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of tb
-- ----------------------------
INSERT INTO `tb` VALUES ('b', '5');
INSERT INTO `tb` VALUES ('c', '15');
INSERT INTO `tb` VALUES ('d', '20');
INSERT INTO `tb` VALUES ('e', '99');此時 ta tb 對應的c字段的num是一樣的
sql:
SELECT id,SUM(num) FROM ( SELECT * FROM ta UNION ALL SELECT * FROM tb) as tmp GROUP BY id
運行結果:
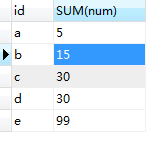
若:
SELECT id,SUM(num) FROM ( SELECT * FROM ta UNION SELECT * FROM tb) as tmp GROUP BY id
運行結果:
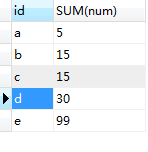
使用Union,則所有返回的行都是唯一的,如同您已經對整個結果集合使用了DISTINCT,若果多表查詢結果中有完全一致的數據,mysql將自動去重
使用Union all,則不會排重,返回所有的行
上述內容就是UNION和UNION ALL怎么在MySQL中使用,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





