溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
前言
上回說到我們如何把拉勾的數據抓取下來的,既然獲取了數據,就別放著不動,把它拿出來分析一下,看看這些數據里面都包含了什么信息。
(本次博客源碼地址:https://github.com/MaxLyu/Lagou_Analyze (本地下載))
下面話不多說了,來一起看看詳細的介紹吧
一、前期準備
由于上次抓的數據里面包含有 ID 這樣的信息,我們需要將它去掉,并且查看描述性統計,確認是否存在異常值或者確實值。
read_file = "analyst.csv" # 讀取文件獲得數據 data = pd.read_csv(read_file, encoding="gbk") # 去除數據中無關的列 data = data[:].drop(['ID'], axis=1) # 描述性統計 data.describe()
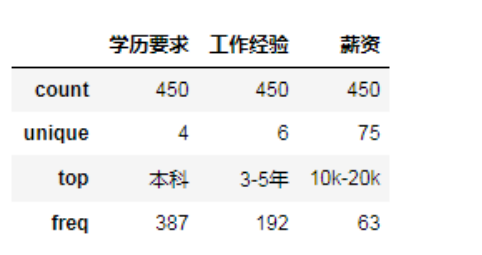
結果中的 unique 表示的是在該屬性列下面存在的不同值個數,以學歷要求為例子,它包含【本科、大專、碩士、不限】這4個不同的值,top 則表示數量最多的值為【本科】,freq 表示出現的頻率為 387。由于薪資的 unique 比較多,我們查看一下存在什么值。
print(data['學歷要求'].unique()) print(data['工作經驗'].unique()) print(data['薪資'].unique())

二、預處理
從上述兩張圖可以看到,學歷要求和工作經驗的值比較少且沒有缺失值與異常值,可以直接進行分析;但薪資的分布比較多,總計有75種,為了更好地進行分析,我們要對薪資做一個預處理。根據其分布情況,可以將它分成【5k 以下、5k-10k、10k-20k、20k-30k、30k-40k、40k 以上】,為了更加方便我們分析,取每個薪資范圍的中位數,并劃分到我們指定的范圍內。
# 對薪資進行預處理
def pre_salary(data):
salarys = data['薪資'].values
salary_dic = {}
for salary in salarys:
# 根據'-'進行分割并去掉'k',分別將兩端的值轉換成整數
min_sa = int(salary.split('-')[0][:-1])
max_sa = int(salary.split('-')[1][:-1])
# 求中位數
median_sa = (min_sa + max_sa) / 2
# 判斷其值并劃分到指定范圍
if median_sa < 5:
salary_dic[u'5k以下'] = salary_dic.get(u'5k以下', 0) + 1
elif median_sa > 5 and median_sa < 10:
salary_dic[u'5k-10k'] = salary_dic.get(u'5k-10k', 0) + 1
elif median_sa > 10 and median_sa < 20:
salary_dic[u'10k-20k'] = salary_dic.get(u'10k-20k', 0) + 1
elif median_sa > 20 and median_sa < 30:
salary_dic[u'20k-30k'] = salary_dic.get(u'20k-30k', 0) + 1
elif median_sa > 30 and median_sa < 40:
salary_dic[u'30k-40k'] = salary_dic.get(u'30k-40k', 0) + 1
else:
salary_dic[u'40以上'] = salary_dic.get(u'40以上', 0) + 1
print(salary_dic)
return salary_dic
對【薪資】進行預處理之后,還要對【任職要求】的文本進行預處理。因為要做成詞云圖,需要對文本進行分割并去除掉一些出現頻率較多但沒有意義的詞,我們稱之為停用詞,所以我們用 jieba 庫進行處理。jieba 是一個python實現的分詞庫,對中文有著很強大的分詞能力。
import jieba def cut_text(text): stopwords =['熟悉','技術','職位','相關','工作','開發','使用','能力', '優先','描述','任職','經驗','經驗者','具有','具備','以上','善于', '一種','以及','一定','進行','能夠','我們'] for stopword in stopwords: jieba.del_word(stopword) words = jieba.lcut(text) content = " ".join(words) return content
預處理完成之后,就可以進行可視化分析了。
三、可視化分析
我們先繪制環狀圖和柱狀圖,然后將數據傳進去就行了,環狀圖的代碼如下:
def draw_pie(dic):
labels = []
count = []
for key, value in dic.items():
labels.append(key)
count.append(value)
fig, ax = plt.subplots(figsize=(8, 6), subplot_kw=dict(aspect="equal"))
# 繪制餅狀圖,wedgeprops 表示每個扇形的寬度
wedges, texts = ax.pie(count, wedgeprops=dict(width=0.5), startangle=0)
# 文本框設置
bbox_props = dict(box, fc="w", ec="k", lw=0)
# 線與箭頭設置
kw = dict(xycoords='data', textcoords='data', arrowprops=dict(arrow),
bbox=bbox_props, zorder=0, va="center")
for i, p in enumerate(wedges):
ang = (p.theta2 - p.theta1)/2. + p.theta1
y = np.sin(np.deg2rad(ang))
x = np.cos(np.deg2rad(ang))
# 設置文本框在扇形的哪一側
horizontalalignment = {-1: "right", 1: "left"}[int(np.sign(x))]
# 用于設置箭頭的彎曲程度
connectionstyle = "angle,angleA=0,angleB={}".format(ang)
kw["arrowprops"].update({"connectionstyle": connectionstyle})
# annotate()用于對已繪制的圖形做標注,text是注釋文本,含 'xy' 的參數跟坐標點有關
text = labels[i] + ": " + str('%.2f' %((count[i])/sum(count)*100)) + "%"
ax.annotate(text, size=13, xy=(x, y), xytext=(1.35*np.sign(x), 1.4*y),
horizontalalignment=horizontalalignment, **kw)
plt.show()
柱狀圖的代碼如下:
def draw_workYear(data):
workyears = list(data[u'工作經驗'].values)
wy_dic = {}
labels = []
count = []
# 得到工作經驗對應的數目并保存到count中
for workyear in workyears:
wy_dic[workyear] = wy_dic.get(workyear, 0) + 1
print(wy_dic)
# wy_series = pd.Series(wy_dic)
# 分別得到 count 的 key 和 value
for key, value in wy_dic.items():
labels.append(key)
count.append(value)
# 生成 keys 個數的數組
x = np.arange(len(labels)) + 1
# 將 values 轉換成數組
y = np.array(count)
fig, axes = plt.subplots(figsize=(10, 8))
axes.bar(x, y, color="#1195d0")
plt.xticks(x, labels, size=13, rotation=0)
plt.xlabel(u'工作經驗', fontsize=15)
plt.ylabel(u'數量', fontsize=15)
# 根據坐標將數字標在圖中,ha、va 為對齊方式
for a, b in zip(x, y):
plt.text(a, b+1, '%.0f' % b, ha='center', va='bottom', fontsize=12)
plt.show()
我們再把學歷要求和薪資的數據稍微處理一下變成字典形式,傳進繪制好的環狀圖函數就行了。另外,我們還要對【任職要求】的文本進行可視化。
from wordcloud import WordCloud
# 繪制詞云圖
def draw_wordcloud(content):
wc = WordCloud(
font_path = 'c:\\Windows\Fonts\msyh.ttf',
background_color = 'white',
max_font_size=150, # 字體最大值
min_font_size=24, # 字體最小值
random_state=800, # 隨機數
collocations=False, # 避免重復單詞
width=1600,height=1200,margin=35, # 圖像寬高,字間距
)
wc.generate(content)
plt.figure(dpi=160) # 放大或縮小
plt.imshow(wc, interpolation='catrom',vmax=1000)
plt.axis("off") # 隱藏坐標
四、成果與總結

python數據分析師的學歷大部分要求是本科,占了86%。
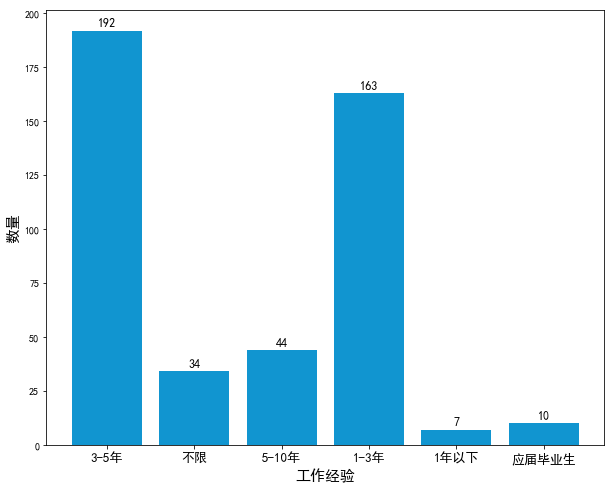
從柱狀圖可以看出,python數據分析師的工作經驗絕大部分要求1-5年。
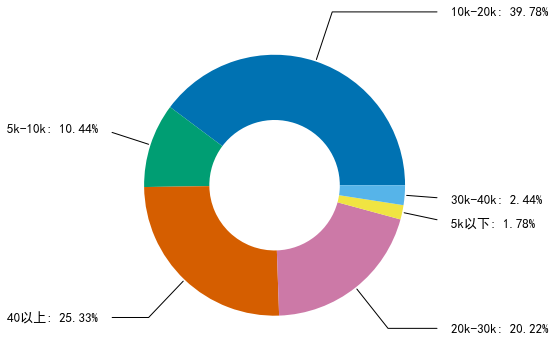
由此可以得出python數據分析的工資為10k-20k的比較多,40以上的也不少,工資高估計要求會比較高,所以我們看一下職位要求。

從詞云圖可看出,數據分析肯定要對數據比較敏感,并且對統計學、excel、python、數據挖掘、hadoop等也有一定的要求。不僅如此,還要求具有一定的抗壓能力、解決問題的能力、良好的表達能力、思維能力等。
總結
以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作具有一定的參考學習價值,謝謝大家對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





