溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Python如何實現AI目標檢測技術,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
示例:
from imageai.Detection import ObjectDetection import os execution_path = os.getcwd() detector = ObjectDetection() detector.setModelTypeAsRetinaNet() detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h6")) detector.loadModel() detections = detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg")) for eachObject in detections: print(eachObject["name"] + " : " + eachObject["percentage_probability"] )
沒錯,用這寥寥10行代碼,就能實現目前AI產品中應用廣泛的目標檢測技術。
看完了代碼,下面容我們聊聊目標檢測背后的技術背景,并解讀這10行Python代碼的由來和實現原理。
目標檢測簡介
人工智能的一個重要領域就是計算機視覺,它是指計算機及軟件系統識別和理解圖像與視頻的科學。計算機視覺包含很多細分方向,比如圖像識別、目標檢測、圖像生成和圖像超分辨率等。其中目標檢測由于用途廣泛,在計算機視覺領域的意義最為深遠。
目標檢測是指計算機和軟件系統能夠定位出圖像/畫面中的物體,并識別出它們。目標檢測技術已經廣泛應用于人臉檢測、車輛檢測、人流量統計、網絡圖像、安防系統和無人車等領域。和其它計算機視覺技術一樣,目標檢測未來會進一步成為人工智能的重要組成部分,有著廣闊的發展前景。
不過,在軟件應用和系統中使用現代目標檢測方法以及根據這些方法創建應用,并非簡單直接。早期的目標檢測實現主要是應用一些經典算法,比如OpenCV中支持的算法。然而這些算法的表現并不穩定,在不同情況下差異巨大。
2012年深度學習技術的突破性進展,催生了一大批高度精準的目標檢測算法,比如R-CNN,Fast-RCNN,Faster-RCNN,RetinaNet和既快又準的SSD及YOLO。使用這些基于深度學習的方法和算法,需要理解大量的數學和深度學習框架。現在全世界有數以百萬計的開發者在借助目標檢測技術創造新產品新項目,但由于理解和使用較為復雜困難,仍有很多人不得要領。
為了解決這個困擾開發者們的問題,計算機視覺專家Moses Olafenwa帶領團隊推出了Python庫ImageAI,能讓開發人員只需寥寥數行代碼就能很容易的將最先進的計算機視覺技術應用到自己的項目和產品中。
我們開頭所示的10行代碼實現,就是要用到ImageAI。
如何借助ImageAI輕松實現目標檢測
使用ImageAI執行目標檢測,你只需以下4步:
1.在電腦上安裝Python
2.安裝ImageAI及其環境依賴
3.下載目標檢測模塊文件
4.運行示例代碼,就是我們展示的那10行
下面我們一步步詳細講解。
1)從Python官網下載和安裝Python 3
python.org/
2)通過pip安裝如下環境依賴
1.Tensorflow
pip install tensorflow
2.Numpy
pip install numpy
3.SciPy
pip install scipy
4.OpenCV
pip install opencv-python
5.Pillow
pip install pillow
6.Matplotlib
pip install matplotlib
7.H5py
pip install h6py
8.Keras
pip install keras
9.ImageAI
pip install
3)通過該 鏈接 下載RetinaNet 模型文件用于目標檢測。
到了這里我們已經安裝好了所有依賴,就可以準備寫自己的首個目標檢測代碼了。 創建一個Python文件,為其命名(比如FirstDetection.py),然后將如下代碼寫到文件中,再把RetinaNet模型文件以及你想檢測的圖像拷貝到包含該Python文件的文件夾里。
FirstDetection.py
from imageai.Detection import ObjectDetection import os execution_path = os.getcwd() detector = ObjectDetection() detector.setModelTypeAsRetinaNet() detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h6")) detector.loadModel() detections = detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg")) for eachObject in detections: print(eachObject["name"] + " : " + eachObject["percentage_probability"] )
然后運行代碼,等待控制臺打印結果。等控制臺打印出結果后,就可以打開FirstDetection.py所在的文件夾,你就會發現有新的圖像保存在了里面。比如下面兩張示例圖像,以及執行目標檢測后保存的兩張新圖像。
目標檢測之前:


目標檢測之后:
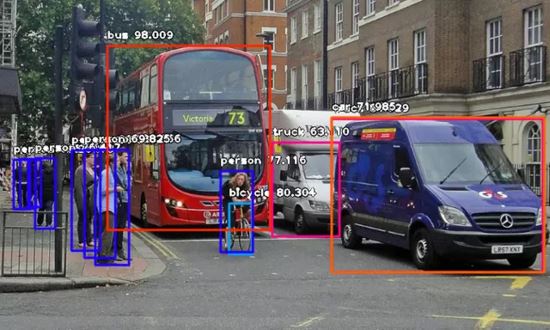

我們可以看到圖像上顯示了檢測出的物體名稱及概率。
解讀10行代碼
下面我們解釋一下這10行代碼的工作原理。
from imageai.Detection import ObjectDetection import os execution_path = os.getcwd()
在上面3行代碼中,我們在第一行導入了ImageAI目標檢測類,在第二行導入Python os類,在第三行定義了一個變量,獲取通往我們的Python文件、RetinaNet模型文件和圖像所在文件夾的路徑。
detector = ObjectDetection() detector.setModelTypeAsRetinaNet() detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h6")) detector.loadModel() detections = detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg"))
在上面5行代碼中,我們在第一行定義我們的目標檢測類,在第二行設定RetinaNet的模型類型,在第三行將模型路徑設置為RetinaNet模型的路徑,在第四行將模型加載到目標檢測類中,然后我們在第五行調用檢測函數,并在輸入和輸出圖像路徑中進行解析。
for eachObject in detections: print(eachObject["name"] + " : " + eachObject["percentage_probability"] )
在上面兩行代碼中,我們迭代了第一行中detector.detectObjectFromImage函數返回的所有結果,然后打印出第二行中模型對圖像上每個物體的檢測結果(名稱和概率)。
ImageAI支持很多強大的目標檢測自定義功能,其中一項就是能夠提取在圖像上檢測到的每個物體的圖像。只需將附加參數extract_detected_objects=True解析為detectObjectsFromImage函數,如下所示,目標檢測類就會為圖像物體創建一個文件夾,提取每張圖像,將它們保存在新創建的文件夾中,并返回一個包含通過每張圖像的路徑的額外數組。
detections, extracted_images = detector.detectObjectsFromImage(input_image=os.path.join(execution_path , "image.jpg"), output_image_path=os.path.join(execution_path , "imagenew.jpg"), extract_detected_objects=True)
我們用前面的第一張圖像作為例子,可以得到圖像中檢測到的各個物體的單獨圖像:

ImageAI提供了很多功能,能夠用于各類目標檢測任務的自定義和生產部署。包括:
-調整最小概率:默認概率小于50%的物體不會顯示,如有需要,你可以自行調整這個數字。
-自定義目標檢測:使用提供的CustomObject類,你可以檢測一個或多個特定物體。
-調整檢測速度:可以通過將檢測速度設為“快”“更快”“最快”三個不同等級,調整檢測速度。
-輸入輸出類型:你可以自定義圖像的路徑,Numpy數組或圖像的文件流為輸入輸出。
誠然,單看這10行代碼每一行,談不上驚艷,也借助了不少庫,但是僅用10行代碼就能讓我們輕松實現之前很麻煩的目標檢測,還是能談得上“給力”二字。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“Python如何實現AI目標檢測技術”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





