溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Tags: APM
pinpoint調用鏈工具初識
===
在本文中重點講一下pinpoint工具的架構,安裝和部署;
??Pinpoint是一款對Java編寫的大規模分布式系統的APM工具,有些人也喜歡稱呼這類工具為調用鏈系統、分布式跟蹤系統。我們知道,前端向后臺發起一個查詢請求,后臺服務可能要調用多個服務,每個服務可能又會調用其它服務,最終將結果返回,匯總到頁面上。如果某個環節發生異常,工程師很難準確定位這個問題到底是由哪個服務調用造成的,Pinpoint等相關工具的作用就是追蹤每個請求的完整調用鏈路,收集調用鏈路上每個服務的性能數據,方便工程師能夠快速定位問題。
??pinpoint對服務器性能的影響非常小(只增加約3%資源利用率),安裝agent是無侵入式的,只需要在被測試的Tomcat中加上3句話,打下探針,就可以監控整套程序了。類似的工具包括google的Dapper,twitter的Zipkin,淘寶的鷹眼(EdleEye),大眾點評的CAT,還有國內開源的skywalking,商業的聽云APM工具等;
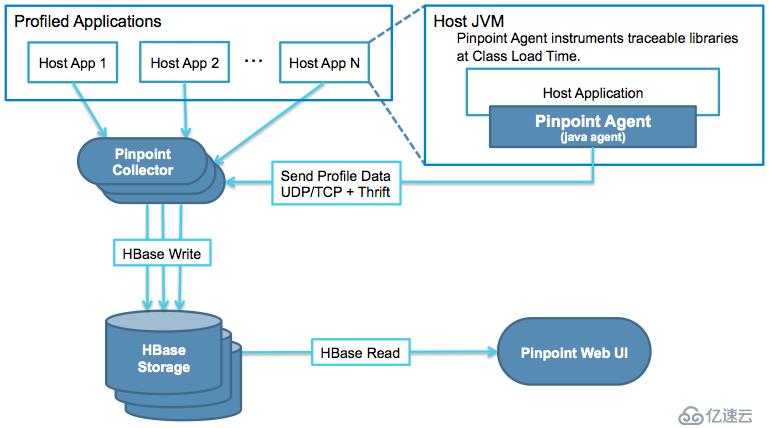
??Pinpoint以Hbase作為存儲的數據庫。HBase是Apache Hadoop的數據庫,能夠對大型數據提供隨機、實時的讀寫訪問,是Google的BigTable的開源實現。HBase的目標是存儲并處理大型的數據,更具體地說僅用普通的硬件配置,能夠處理成千上萬的行和列所組成的大型數據庫。HBase是一個開源的、分布式的、多版本的、面向列的存儲模型。可以直接使用本地文件系統,也可使用Hadoop的HDFS文件存儲系統。為了提高數據的可靠性和系統的健壯性,并且發揮HBase處理大型數據的能力,還是使用HDFS作為文件存儲系統更佳。
??HBase的服務器體系結構遵從簡單的主從服務器架構,它由HRegion Server群和HBase Master服務器構成。HBase Master負責管理所有的HRegionServer,而HBase中的所有RegionServer都是通過ZooKeeper來協調,并處理HBase服務器運行期間可能遇到的錯誤。
??HBase Master Server本身并不存儲HBase中的任何數據,HBase邏輯上的表可能會被劃分成多個Region,然后存儲到HRegion Server群中。HBase Master Server中存儲的是從數據到HRegion Server的映射.
??HBase的安裝也有三種模式:單機模式、偽分布模式和完全分布式模式,在這里只介紹完全分布模式。前提是Hadoop集群和Zookeeper已經安裝完畢,并能正確運行。
#在第一臺節點上面安裝zookeeper:
tar xzvf zookeeper-3.4.8.tar.gz -C /usr/local/
cd /usr/local/
ln -sv zookeeper-3.4.8 zookeeper
cd /usr/local/zookeeper
mkdir -p data3
mkdir -p logs3
cd /usr/local/zookeeper/conf
cp -r zoo_sample.cfg zoo.cfg
vim zoo.cfg
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/usr/local/zookeeper/data3
dataLogDir=/usr/local/zookeeper/logs3
clientPort=2181
server.189=192.168.1.189:2888:3888
server.190=192.168.1.190:2888:3888
server.191=192.168.1.191:2888:3888
echo "189" >> /usr/local/zookeeper/data3/myid
#將服務器的標識內容登記到/usr/local/zookeeper/data3/myid文件中,這個189是我的服務器的IP地址最后一位。
/usr/local/zookeeper/bin/zkServer.sh start
#啟動服務
/usr/local/zookeeper/bin/zkServer.sh stop
#停止服務
/usr/local/zookeeper/bin/zkServer.sh status
#查看主從角色,leader是主角色,follower是從角色??安裝完成zk集群之后,就需要HDFS文件系統了,因為Hbase數據庫依賴于HDFS文件系統,其實Hbase數據庫也可以使用本地文件系統。只不過使用HDFS文件系統更有利用系統的健壯和性能;因為我剛開始接觸Hbase數據庫,對大數據方面的中間件還不是很熟悉,所以我的HDFS文件系統是單機的。然后我把Hbase數據庫安裝的是集群結構的。分為Hmaster和HRegionServer。
# 安裝hbase數據庫的三臺服務器都必須能夠使用root登錄,并且端口是默認端口22
chattr -i /etc/ssh/sshd_config
sed -i 's#PermitRootLogin no#PermitRootLogin yes#g' /etc/ssh/sshd_config
sed -i 's#AllowUsers ttadm#AllowUsers ttadm root#g' /etc/ssh/sshd_config
sed -i 's#10022#22#g' /etc/ssh/sshd_config
systemctl restart sshd
# 然后再master的這臺機器上面配置公鑰和私鑰,拷貝公鑰到另外兩臺機器
ssh-keygen -t rsa
ssh-copy-id 192.168.1.190
ssh-copy-id 192.168.1.191
cd /usr/local/hbase-1.4.10/conf/
vim hbase-env.sh
# 這個參數如果是true,表示使用Hbase自帶的zk,因為我們安裝了獨立的zk集群,所以需要將這個參數設置為false
export HBASE_MANAGES_ZK=false
# The java implementation to use. Java 1.7+ required.
export JAVA_HOME=/usr/local/jdk1.8.0_131
# Extra Java CLASSPATH elements. Optional.
export HBASE_CLASSPATH=/usr/local/hbase-1.4.10/conf
# vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://192.168.1.189:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98后的新變動,之前版本沒有.port,默認端口為60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>192.168.1.189:2181,192.168.1.190:2181,192.168.1.191:2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper/data3</value>
</property>
</configuration>
# hbase-site.xml這個配置文件主要配置了Hbase的數據庫存儲路徑,依賴zk的一些信息;Hbase數據庫存儲可以使用本地存儲,也可以使用HDFS文件系統。如果是本地存儲,格式如下:
<name>hbase.rootdir</name>
<value>file:/usr/src/pinpoint_resource/hbase-1.2.4/data</value>
vim regionservers
192.168.1.189
192.168.1.190
192.168.1.191
# 配置regionserver的服務器地址
cd /usr/local/hbase-1.4.10/bin
./start-hbase.sh
# 啟動hbase數據庫,啟動之前需要將hbase的安裝程序和配置文件都拷貝到另外兩臺機器上面,然后配置好免密登錄之后,執行start-hbase.sh之后,會自動在另外兩臺機器上面HRegionServer。檢查的方式就是jps命令
# 兩臺從節點上面查看hbase進程
[root@SZ1PRDOAM00AP010 ~]# jps
17408 HRegionServer #表示hbase的RegionServer
16931 QuorumPeerMain #這個是zk的進程
18475 Bootstrap
24047 Jps
# 在主節點上查看hbase進程
[root@SZ1PRDOAM00AP009 conf]# jps
21968 SecondaryNameNode # hdfs文件系統的進程
21793 DataNode #這個是hdfs文件系統的進程,存儲數據
98883 Jps
73397 QuorumPeerMain #zk的進程
81286 Bootstrap
74201 HRegionServer #hbase的進程
21659 NameNode # hdfs文件系統的進程,管理元數據
74061 HMaster #
# 初始化pinpoint的數據庫
wget https://github.com/naver/pinpoint/blob/1.8.5/hbase/scripts/hbase-create.hbase
hbase shell hbase-create.hbase
# 如果需要清除數據,就下載hbase-drop.hbase腳本
Hbase數據庫安裝成功之后,有個web管理頁面可以查看數據庫表的。http://192.168.1.189:16010/master-status,訪問16010端口就可以查看了。其中可以看到我們剛才初始化的TABLE.
??因為Hbase數據庫依賴于HDFS文件系統,所以我們順便說一下安裝HDFS文件系統了。安裝HDFS文件系統首先先按照hadoop.
??Hadoop Common是在Hadoop0.2版本之后分離出來的HDFS和MapReduce獨立子項目的內容,是Hadoop的核心部分,能為其他模塊提供一些常用工具集,如序列化機制、Hadoop抽象文件系統FileSystem、系統配置工具Configuration,并且在為其平臺上的軟件開發提供KPI等。其他Hadoop子項目都是以此為基礎而建立來的
??HDFS是分布式文件存儲系統,類似于FAT32,NTFS,是一種文件格式,是底層的HDFS是Hadoop體系中數據存儲管理的基礎,它是一個高度容錯的系統,能檢測和應對硬件故障,在低成本的通用硬件上運行。
??Hbase是Hadoop database,即Hadoop數據庫。它是一個適合于非結構化數據存儲的數據庫,HBase基于列的而不是基于行的模式。HBase是一個建立在HDFS之上,面向結構化數據的可伸縮、高可靠、高性能、分布式和面向列的動態模式數據庫。 Hbase的數據一般都存儲在HDFS上。Hadoop HDFS為他們提供了高可靠性的底層存儲支持
cd /usr/local
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.9.0/hadoop-2.9.0.tar.gz
tar xzvf hadoop-2.9.0.tar.gz
cd /usr/local/hadoop-2.9.0/etc/hadoop
vim hadoop-env.sh
# set JAVA_HOME in this file, so that it is correctly defined on
export JAVA_HOME=/usr/local/jdk1.8.0_13
# 查看hadoop版本
cd /usr/local/hadoop-2.9.0/bin
[root@SZ1PRDOAM00AP009 bin]# ./hadoop version
Hadoop 2.9.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 756ebc8394e473ac25feac05fa493f6d612e6c50
Compiled by arsuresh on 2017-11-13T23:15Z
Compiled with protoc 2.5.0
From source with checksum 0a76a9a32a5257331741f8d5932f183
This command was run using /usr/local/hadoop-2.9.0/share/hadoop/common/hadoop-common-2.9.0.jar
[root@SZ1PRDOAM00AP009 bin]#
# 配置hadoop的環境變量
[root@SZ1PRDOAM00AP009 bin]# cat /etc/profile.d/hadoop.sh
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
安裝完成hadoop之后,我們接下來安裝hdfs文件系統。HDFS文件系統和Hadoop軟件包是一個,修改幾個配置文件就可以了;
vim /usr/local/hadoop-2.9.0/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.1.189:9000</value>
</property>
</configuration>
#配置nameNode:接收請求的地址,客戶端將請求該地址
vim /usr/local/hadoop-2.9.0/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///usr/local/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///usr/local/hadoop/hdfs/datanode</value>
</property>
</configuration>
# 配置數據副本,因為我們是單機,所以就配置了1副本。存儲目錄是本地文件的目錄。
#ssh免密碼登錄
ssh localhost
#如果不支持,按順序執行下面三行命令即可
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
#格式化
#初次使用hdfs需要進行格式化
hdfs namenode -format
#啟動
#格式化完成以后,我們就可以啟動hdfs了
sbin/start-dfs.sh
#啟動完成,我們查看一下hdfs進程
ps -ef|grep hdfs
#你會看到:nameNode\dataNode\secondaryNameNode這三個進程,則表示啟動成功,否則到logs下的對應日志中查看錯誤信息。
#安裝好HDFS文件系統之后,可以通過web管理頁面查看狀態;
http://192.168.1.189:50070/dfshealth.html#tab-overview??pinpoint一般由三個組件組成。分別是pinpoint-Collector用來收集數據,Pinpoint-Web用來展示數據,pinpoint-agent是收集客戶端。Hbase是用來存儲數據。我們先看看pinpoint-Collector的安裝;
wget https://github.com/naver/pinpoint/releases/download/1.8.5/pinpoint-agent-1.8.5.tar.gz
wget https://github.com/naver/pinpoint/releases/download/1.8.5/pinpoint-collector-1.8.5.war
wget https://github.com/naver/pinpoint/releases/download/1.8.5/pinpoint-web-1.8.5.war
# pinpoint-collector和pinpoint-web都是war包,運行在tomcat里面就可以了.如果在生產環境,建議收集器和web管理界面安裝在不同的機器上面;
cd /usrl/local/tomcat/webapps/
rm -rf *
unzip pinpoint-collector-1.6.1.war -d ROOT
cd /usr/local/tomcat/webapps/ROOT/WEB-INF/classes
vim pinpoint-collector.properties
cluster.zookeeper.address=192.168.1.191
#修改zookeeper地址
vim hbase.properties
hbase.client.host=192.168.1.191
hbase.client.port=2181
#配置數據庫存儲的地址
/usr/local/tomcat/bin/startup.sh
#啟動tomcat
cd /usrl/local/tomcat/webapps/
rm -rf *
unzip pinpoint-web-1.8.5.war -d ROOT
cd /usr/local/tomcat/webapps/ROOT/WEB-INF/classes
vim hbase.properties
hbase.client.host=192.168.1.191
hbase.client.port=2181
#配置數據庫存儲的地址
vim pinpoint-web.properties
cluster.enable=false
cluster.web.tcp.port=9997
cluster.zookeeper.address=192.168.1.191
# web集群功能禁用掉,然后配置zk的地址
/usr/local/tomcat/bin/startup.sh
#啟動tomcat
mkdir -p /usr/local/pinpoint-agent
cd /usr/local
tar xzvf pinpoint-agent-1.8.5.tar.gz -C pinpoint-agent
vim pinpoint.config
profiler.collector.ip=192.168.1.190
# 配置collector服務器的地址
cd scripts
[root@SZ1PRDOAM00AP009 script]# sh networktest.sh
CLASSPATH=./tools/pinpoint-tools-1.8.5.jar:
2019-10-15 16:13:17 [INFO ](com.navercorp.pinpoint.bootstrap.config.DefaultProfilerConfig) configuration loaded successfully.
UDP-STAT:// SZ1PRDOAM00AP010.bf.cn
=> 192.168.1.190:9995 [SUCCESS]
UDP-SPAN:// SZ1PRDOAM00AP010.bf.cn
=> 192.168.1.190:9996 [SUCCESS]
TCP:// SZ1PRDOAM00AP010.bf.cn
=> 192.168.1.190:9994 [SUCCESS]
[root@SZ1PRDOAM00AP009 script]#
#有個網絡測試腳本,可以測試agent到collector之間的網絡是否正常。我這里遇到了一個問題,一直是9995端口不通。后續經過排查,將三臺主機的ip和主機名配置到/etc/hosts文件之中就可以了。
vim /usr/local/tomcat/bin/catalina.sh
JAVA_OPTS="$JAVA_OPTS -javaagent:/usr/local/pinpoint-agent/pinpoint-bootstrap-1.8.5.jar"
JAVA_OPTS="$JAVA_OPTS -Dpinpoint.agentId=gytest"
JAVA_OPTS="$JAVA_OPTS -Dpinpoint.applicationName=gytest01"
# 給增加agent,只需要修改catalina.sh啟動腳本就可以,增加pinpoint的jar包路徑,應用的標識而已;
-Dpinpoint.agentId - 唯一標記agent運行所在的應用(如,loan-33)
-Dpinpoint.applicationName - 將許多的同樣的應用實例分組為單一服務(如,loan)
# 注意:pinpoint.agentId 必須全局唯一來標識應用實例, 而所有共用相同 pinpoint.applicationName 的應用被當成單個服務的多個實例
??差不多有近三個月沒有寫技術博文了,最近老婆生了二胎家里的事情比較多,加上年底了公司的工作也比較忙,所以一直沒有抽出時間來寫博客了,也希望大家能夠諒解。最近我在公司換了一個項目在做,主要是關于統一監控的項目。涉及到了APM鏈路跟蹤,zabbix監控,業務監控等內容,有時間的話我也會將一些經驗分享出來給大家。感謝大家的持續關注。 我的微信公眾號是“云時代IT運維”,大家可以掃碼關注。 
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





