溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關怎么在Python中利用sklearn實現一個回歸算法,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
使用sklearn做各種回歸
基本回歸:線性、決策樹、SVM、KNN
集成方法:隨機森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
1. 數據準備
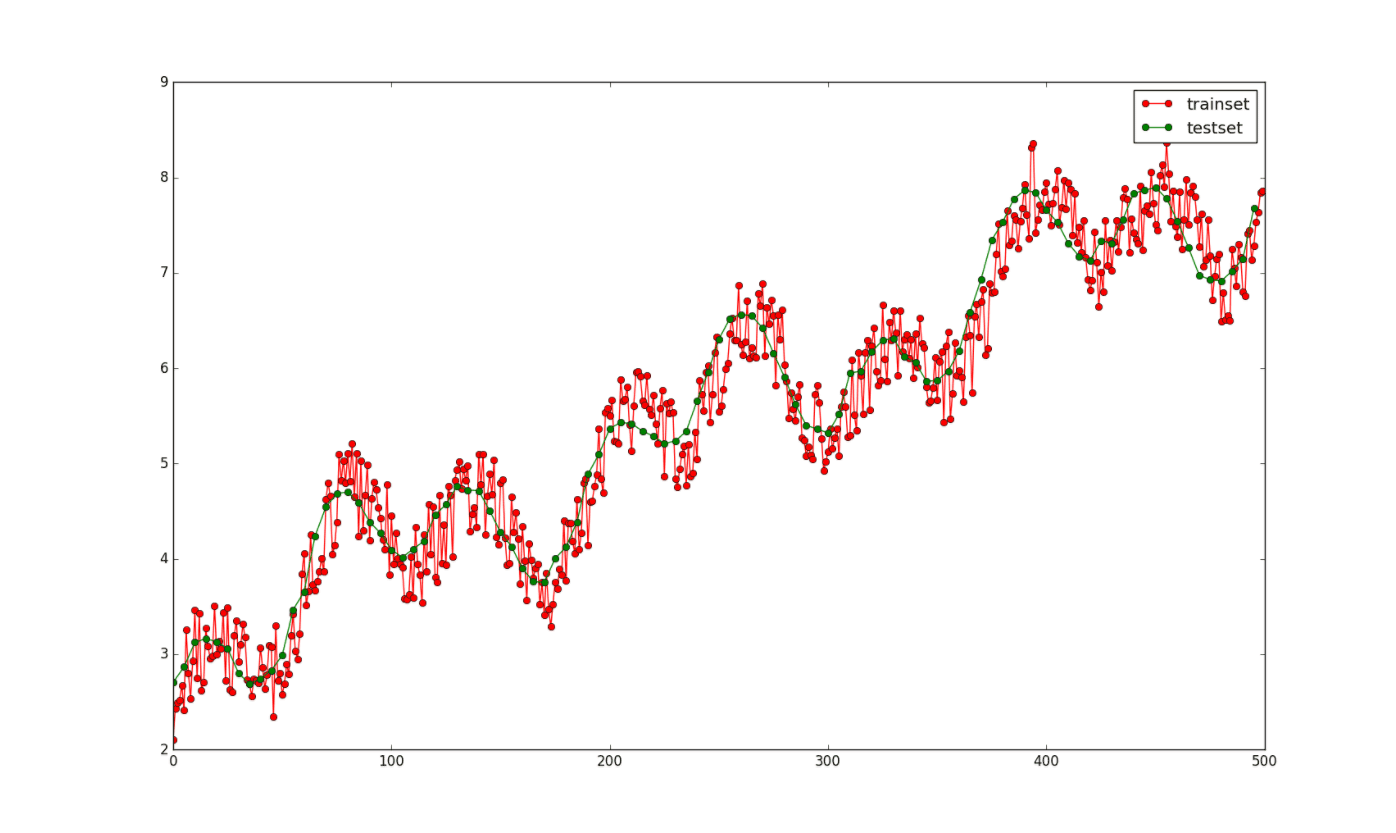
為了實驗用,我自己寫了一個二元函數,y=0.5*np.sin(x1)+ 0.5*np.cos(x2)+0.1*x1+3。其中x1的取值范圍是0~50,x2的取值范圍是-10~10,x1和x2的訓練集一共有500個,測試集有100個。其中,在訓練集的上加了一個-0.5~0.5的噪聲。生成函數的代碼如下:
def f(x1, x2): y = 0.5 * np.sin(x1) + 0.5 * np.cos(x2) + 0.1 * x1 + 3 return y def load_data(): x1_train = np.linspace(0,50,500) x2_train = np.linspace(-10,10,500) data_train = np.array([[x1,x2,f(x1,x2) + (np.random.random(1)-0.5)] for x1,x2 in zip(x1_train, x2_train)]) x1_test = np.linspace(0,50,100)+ 0.5 * np.random.random(100) x2_test = np.linspace(-10,10,100) + 0.02 * np.random.random(100) data_test = np.array([[x1,x2,f(x1,x2)] for x1,x2 in zip(x1_test, x2_test)]) return data_train, data_test
其中訓練集(y上加有-0.5~0.5的隨機噪聲)和測試集(沒有噪聲)的圖像如下:
2. scikit-learn的簡單使用
scikit-learn非常簡單,只需實例化一個算法對象,然后調用fit()函數就可以了,fit之后,就可以使用predict()函數來預測了,然后可以使用score()函數來評估預測值和真實值的差異,函數返回一個得分。
完整程式化代碼為:
import numpy as np
import matplotlib.pyplot as plt
###########1.數據生成部分##########
def f(x1, x2):
y = 0.5 * np.sin(x1) + 0.5 * np.cos(x2) + 3 + 0.1 * x1
return y
def load_data():
x1_train = np.linspace(0,50,500)
x2_train = np.linspace(-10,10,500)
data_train = np.array([[x1,x2,f(x1,x2) + (np.random.random(1)-0.5)] for x1,x2 in zip(x1_train, x2_train)])
x1_test = np.linspace(0,50,100)+ 0.5 * np.random.random(100)
x2_test = np.linspace(-10,10,100) + 0.02 * np.random.random(100)
data_test = np.array([[x1,x2,f(x1,x2)] for x1,x2 in zip(x1_test, x2_test)])
return data_train, data_test
train, test = load_data()
x_train, y_train = train[:,:2], train[:,2] #數據前兩列是x1,x2 第三列是y,這里的y有隨機噪聲
x_test ,y_test = test[:,:2], test[:,2] # 同上,不過這里的y沒有噪聲
###########2.回歸部分##########
def try_different_method(model):
model.fit(x_train,y_train)
score = model.score(x_test, y_test)
result = model.predict(x_test)
plt.figure()
plt.plot(np.arange(len(result)), y_test,'go-',label='true value')
plt.plot(np.arange(len(result)),result,'ro-',label='predict value')
plt.title('score: %f'%score)
plt.legend()
plt.show()
###########3.具體方法選擇##########
####3.1決策樹回歸####
from sklearn import tree
model_DecisionTreeRegressor = tree.DecisionTreeRegressor()
####3.2線性回歸####
from sklearn import linear_model
model_LinearRegression = linear_model.LinearRegression()
####3.3SVM回歸####
from sklearn import svm
model_SVR = svm.SVR()
####3.4KNN回歸####
from sklearn import neighbors
model_KNeighborsRegressor = neighbors.KNeighborsRegressor()
####3.5隨機森林回歸####
from sklearn import ensemble
model_RandomForestRegressor = ensemble.RandomForestRegressor(n_estimators=20)#這里使用20個決策樹
####3.6Adaboost回歸####
from sklearn import ensemble
model_AdaBoostRegressor = ensemble.AdaBoostRegressor(n_estimators=50)#這里使用50個決策樹
####3.7GBRT回歸####
from sklearn import ensemble
model_GradientBoostingRegressor = ensemble.GradientBoostingRegressor(n_estimators=100)#這里使用100個決策樹
####3.8Bagging回歸####
from sklearn.ensemble import BaggingRegressor
model_BaggingRegressor = BaggingRegressor()
####3.9ExtraTree極端隨機樹回歸####
from sklearn.tree import ExtraTreeRegressor
model_ExtraTreeRegressor = ExtraTreeRegressor()
###########4.具體方法調用部分##########
try_different_method(model_DecisionTreeRegressor)3.結果展示
決策樹回歸結果: 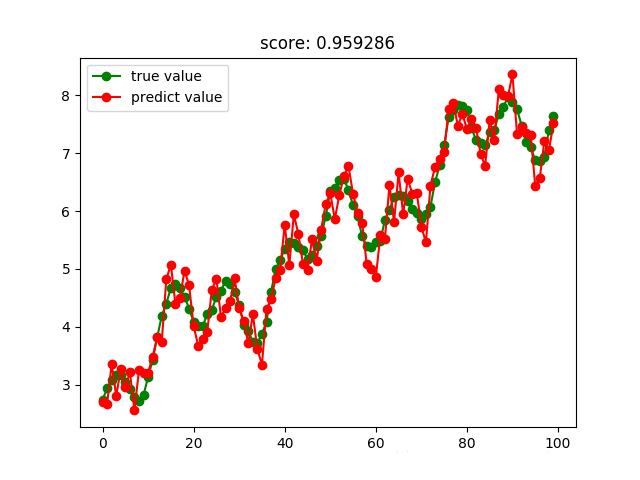
線性回歸結果: 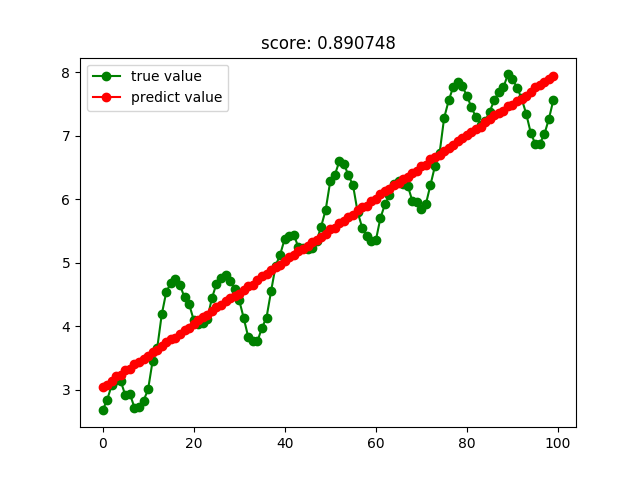
SVM回歸結果: 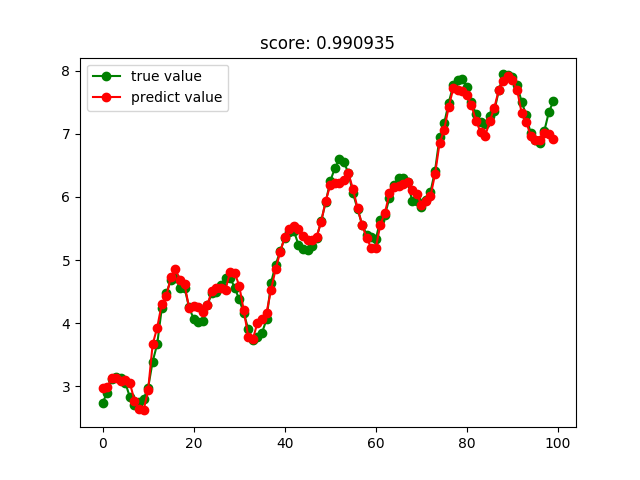
KNN回歸結果: 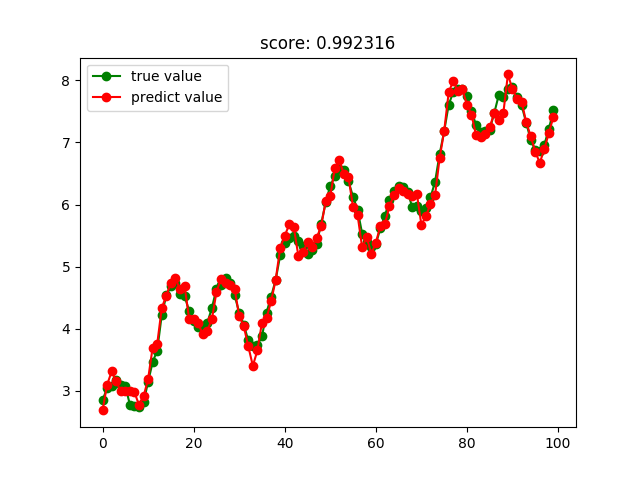
隨機森林回歸結果: 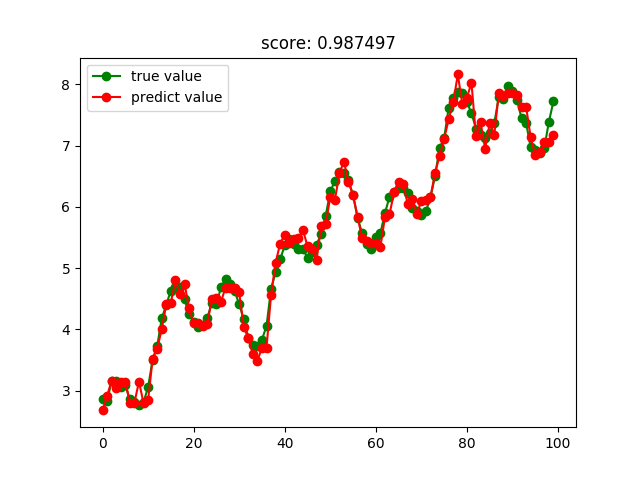
Adaboost回歸結果: 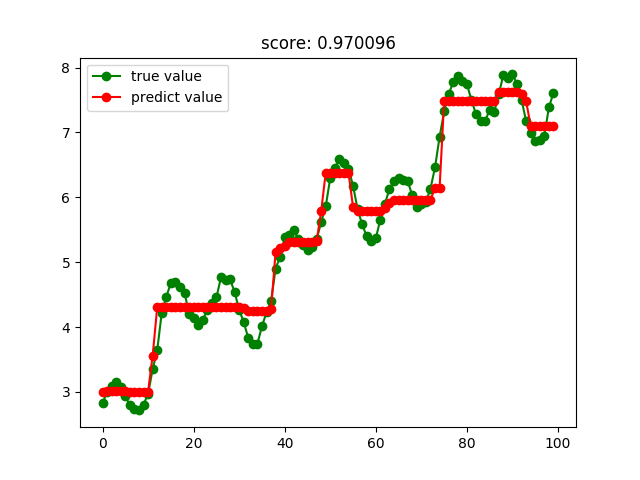
GBRT回歸結果: 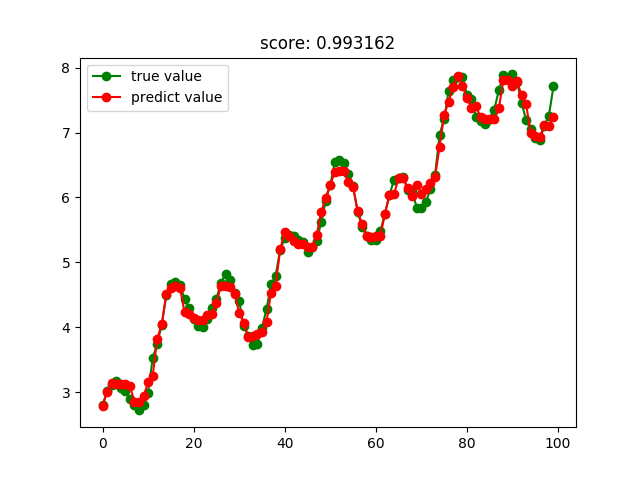
Bagging回歸結果: 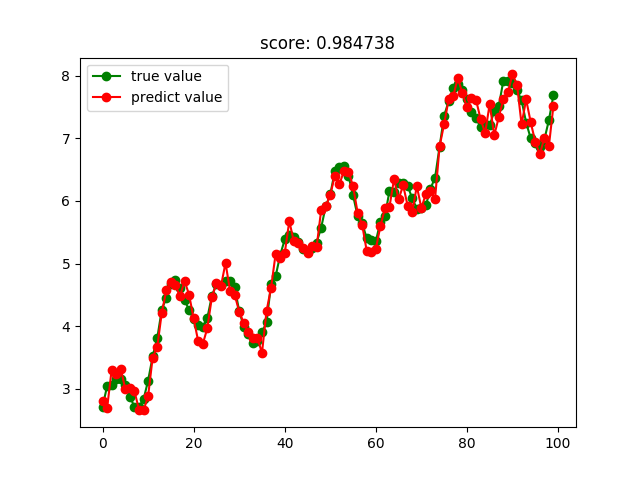
極端隨機樹回歸結果: 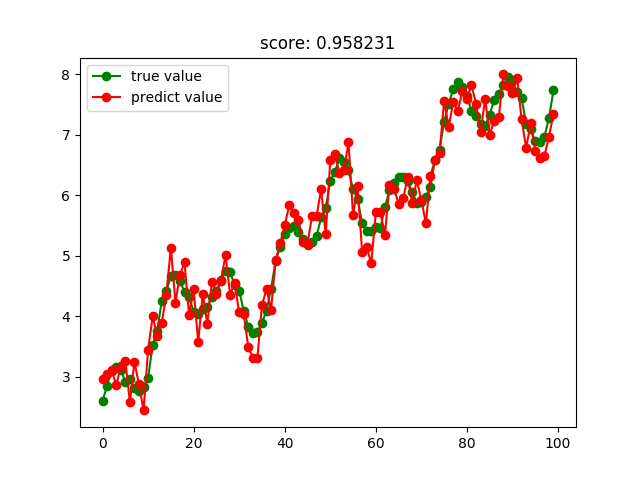
關于怎么在Python中利用sklearn實現一個回歸算法就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





