溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關基于Vue中SEO優化的方案有哪些,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
前言:眾所周知,Vue SPA單頁面應用對SEO不友好,當然也有相應的解決方案,下面列出幾種最近研究和使用過的SEO方案,SRR和靜態化基于Nuxt來說。
1.SSR服務器渲染;
2.靜態化;
3.預渲染prerender-spa-plugin;
4.使用Phantomjs針對爬蟲做處理。
1.SSR服務器渲染
關于服務器渲染:Vue官網介紹 ,對Vue版本有要求,對服務器也有一定要求,需要支持nodejs環境。
使用SSR權衡之處:
開發條件所限,瀏覽器特定的代碼,只能在某些生命周期鉤子函數 (lifecycle hook) 中使用;一些外部擴展庫 (external library) 可能需要特殊處理,才能在服務器渲染應用程序中運行;
環境和部署要求更高,需要Node.js server 運行環境;
高流量的情況下,請準備相應的服務器負載,并明智地采用緩存策略。
優勢:
更好的 SEO,由于搜索引擎爬蟲抓取工具可以直接查看完全渲染的頁面;
更快的內容到達時間 (time-to-content),特別是對于緩慢的網絡情況或運行緩慢的設備。
不足:(開發中遇到的坑)
1.一套代碼兩套執行環境,會引起各種問題,比如服務端沒有window、document對象,處理方式是增加判斷,如果是客戶端才執行:
if(process.browser){
console.log(window);
}引用npm包,帶有dom操作的,例如: wowjs ,不能用 import 的方式,改用:
if (process.browser) {
var { WOW } = require('wowjs');
require('wowjs/css/libs/animate.css');
}2.Nuxt asyncData方法,初始化頁面前先得到數據,但僅限于 頁面組件 調用:
// 并發加載多個接口:
async asyncData ({ app, query }) {
let [resA, resB, resC] = await Promise.all([
app.$axios.get('/api/a'),
app.$axios.get('/api/b'),
app.$axios.get('/api/c'),
])
return {
dataA: resA.data,
dataB: resB.data,
dataC: resC.data,
}
}在asyncData中獲取參數:
1.獲取動態路由參數,如:
/list/:id' ==> '/list/123
接收:
async asyncData ({ app, query }) {
console.log(app.context.params.id) //123
}2.獲取url?獲取參數,如:
/list?id=123
接收:
async asyncData ({ app, query }) {
console.log(query.id) //123
}3.如果你使用 v-if 語法,部署到線上大概也會遇到這個錯誤:
Error while initializing app DOMException: Failed to execute 'appendChild' on 'Node': This node type does not support this method.
at Object.We [as appendChild]
根據github nuxt上的 issue第1552條 提示,要將 v-if 改為 v-show 語法。
4.坑太多,留坑,晚點更。
2.靜態化
在 Nuxt.js 執行 generate 靜態化打包時,動態路由會被忽略。
-| pages/ ---| index.vue ---| users/ -----| _id.vue
需要動態路由先生成靜態頁面,你需要指定動態路由參數的值,并配置到 routes 數組中去。
// nuxt.config.js
module.exports = {
generate: {
routes: [
'/users/1',
'/users/2',
'/users/3'
]
}
}運行打包,即可看見打包出來的頁面。
但是如果路由動態參數的值是動態的而不是固定的,應該怎么做呢?
使用一個返回 Promise 對象類型 的 函數;
使用一個回調是 callback(err, params) 的 函數。
// nuxt.config.js
import axios from 'axios'
export default {
generate: {
routes: function () {
return axios.get('https://my-api/users')
.then((res) => {
return res.data.map((user) => {
return {
route: '/users/' + user.id,
payload: user
}
})
})
}
}
}現在我們可以從 /users/_id.vue 訪問的 payload ,如下所示:
async asyncData ({ params, error, payload }) {
if (payload) return { user: payload }
else return { user: await backend.fetchUser(params.id) }
}如果你的動態路由的參數很多,例如商品詳情,可能高達幾千幾萬個。需要一個接口返回所有id,然后打包時遍歷id,打包到本地,如果某個商品修改了或者下架了,又要重新打包,數量多的情況下打包也是非常慢的,非常不現實。
優勢:
純靜態文件,訪問速度超快;
對比SSR,不涉及到服務器負載方面問題;
靜態網頁不宜遭到黑客攻擊,安全性更高。
不足:
如果動態路由參數多的話不適用。
3.預渲染prerender-spa-plugin
如果你只是用來改善少數營銷頁面(例如 /, /about, /contact 等)的 SEO,那么你可能需要預渲染。無需使用 web 服務器實時動態編譯 HTML,而是使用預渲染方式,在構建時 (build time) 簡單地生成針對特定路由的靜態 HTML 文件。優點是設置預渲染更簡單,并可以將你的前端作為一個完全靜態的站點。
$ cnpm install prerender-spa-plugin --save
vue cli 3 vue.config.js 配置:
const PrerenderSPAPlugin = require('prerender-spa-plugin');
const Renderer = PrerenderSPAPlugin.PuppeteerRenderer;
const path = require('path');
module.exports = {
configureWebpack: config => {
if (process.env.NODE_ENV !== 'production') return;
return {
plugins: [
new PrerenderSPAPlugin({
// 生成文件的路徑,也可以與webpakc打包的一致。
// 下面這句話非常重要!!!
// 這個目錄只能有一級,如果目錄層次大于一級,在生成的時候不會有任何錯誤提示,在預渲染的時候只會卡著不動。
staticDir: path.join(__dirname,'dist'),
// 對應自己的路由文件,比如a有參數,就需要寫成 /a/param1。
routes: ['/', '/product','/about'],
// 這個很重要,如果沒有配置這段,也不會進行預編譯
renderer: new Renderer({
inject: {
foo: 'bar'
},
headless: false,
// 在 main.js 中 document.dispatchEvent(new Event('render-event')),兩者的事件名稱要對應上。
renderAfterDocumentEvent: 'render-event'
})
}),
],
};
}
}在main.js中添加:
new Vue({
router,
render: h => h(App),
mounted () {
document.dispatchEvent(new Event('render-event'))
}
}).$mount('#app')注意:router中必須設置 mode: “history” 。
打包出來可以看見文件,打包出文件夾 /index.html ,例如: about => about/index.html ,里面有html內容。
優勢:
改動小,引入個插件就完事;
不足:
無法使用動態路由;
只適用少量頁面的項目,頁面多達幾百個的情況下,打包會很很很慢;
4.使用Phantomjs針對爬蟲做處理
Phantomjs是一個基于webkit內核的無頭瀏覽器,即沒有UI界面,即它就是一個瀏覽器,只是其內的點擊、翻頁等人為相關操作需要程序設計實現。
雖然“PhantomJS宣布終止開發”,但是已經滿足對Vue的SEO處理。
這種解決方案其實是一種旁路機制,原理就是通過Nginx配置, 判斷訪問的來源UA是否是爬蟲訪問,如果是則將搜索引擎的爬蟲請求轉發到一個node server,再通過PhantomJS來解析完整的HTML,返回給爬蟲。
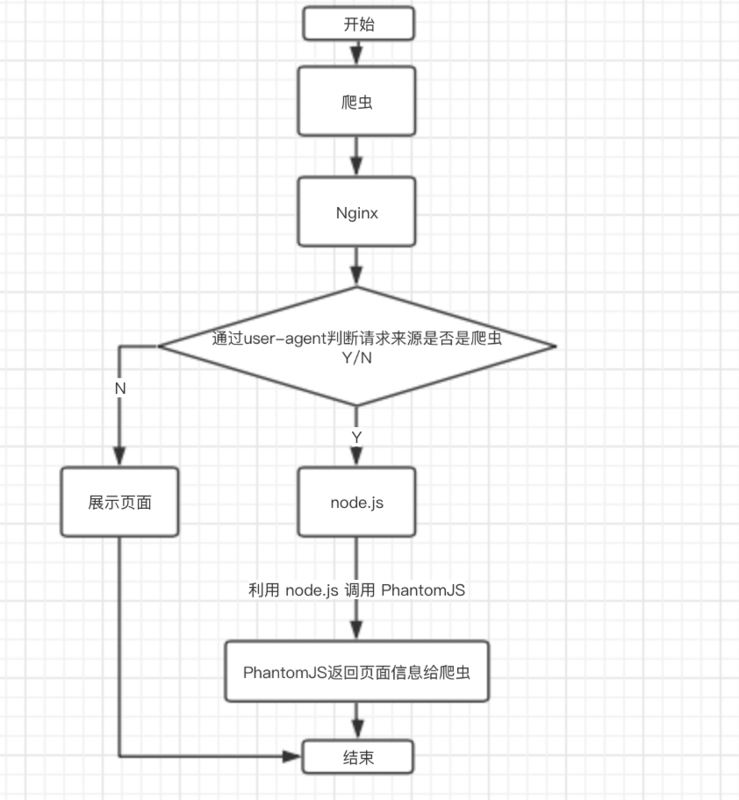
具體代碼戳這里: vue-seo-phantomjs 。
要安裝全局 phantomjs ,局部 express ,測試:
$ phantomjs spider.js 'https://www.baidu.com'
如果見到在命令行里出現了一推html,那恭喜你,你已經征服PhantomJS啦。
啟動之后或者用postman在請求頭增加 User-Agent 值為 Baiduspider ,效果一樣的。
部署上線
線上要安裝 node 、 pm2 、 phantomjs ,nginx相關配置:
upstream spider_server {
server localhost:3000;
}
server {
listen 80;
server_name example.com;
location / {
proxy_set_header Host $host:$proxy_port;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
if ($http_user_agent ~* "Baiduspider|twitterbot|facebookexternalhit|rogerbot|linkedinbot|embedly|quora link preview|showyoubot|outbrain|pinterest|slackbot|vkShare|W3C_Validator|bingbot|Sosospider|Sogou Pic Spider|Googlebot|360Spider") {
proxy_pass http://spider_server;
}
}
}優勢:
完全不用改動項目代碼,按原本的SPA開發即可,對比開發SSR成本小不要太多;
對已用SPA開發完成的項目,這是不二之選。
不足:
部署需要node服務器支持;
爬蟲訪問比網頁訪問要慢一些,因為定時要定時資源加載完成才返回給爬蟲;
如果被惡意模擬百度爬蟲大量循環爬取,會造成服務器負載方面問題,解決方法是判斷訪問的IP,是否是百度官方爬蟲的IP。
關于“基于Vue中SEO優化的方案有哪些”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





