溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文跟著小編一起來學習在linux kernel態下如何使用NEON對算法進行加速的技巧,內容通過圖文實例給大家做了詳細分析,一起來看下。
ARM處理器從cortex系列開始集成NEON處理單元,該單元可以簡單理解為協處理器,專門為矩陣運算等算法設計,特別適用于圖像、視頻、音頻處理等場景,應用也很廣泛。
本文先對NEON處理單元進行簡要介紹,然后介紹如何在內核態下使用NEON,最后列舉實例說明。
一.NEON簡介
其實最好的資料就是官方文檔,Cortex™-A Series Programmer's Guide ,以下描述摘自該文檔
1.1 SIMD
NEON采用SIMD架構,single instruction multy data,一條指令處理多個數據,NEON中這多個數據可以很多,而且配置靈活(8bit、16bit、32bit為單位,可多個單位數據),這是優勢所在。
如下圖,APU需要至少四條指令完成加操作,而NEON只需要1條,考慮到ld和st,節省的指令更多。
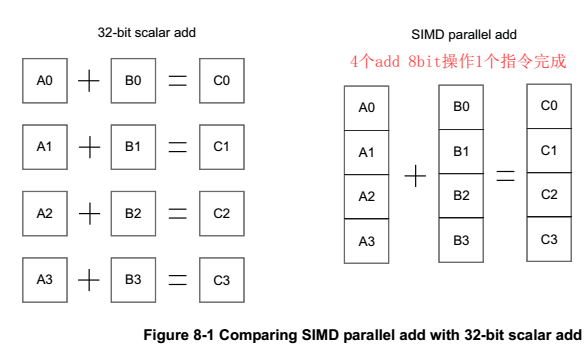
上述特性,使NEON特別適合處理塊數據、圖像、視頻、音頻等。
1.2 NEON architecture overview
NEON也是load/store架構,寄存器為64bit/128bit,可形成向量化數據,配合若干便于向量操作的指令。
1.2.1 commonality with VFP 1.2.2 data type

指令中的數據類型表示,例如VMLAL.S8:

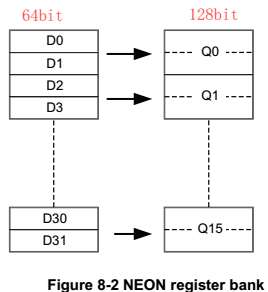
1.2.3 registers
32個64bit寄存器,D0~D31;同時可組成16個128 bit寄存器,Q0~Q15。與VFP公用。
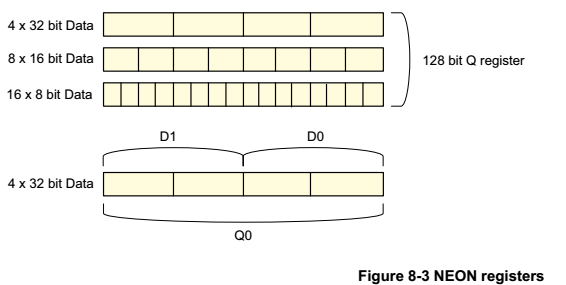
寄存器內部的數據單位為8bit、16bit、32bit,可以根據需要靈活配置。
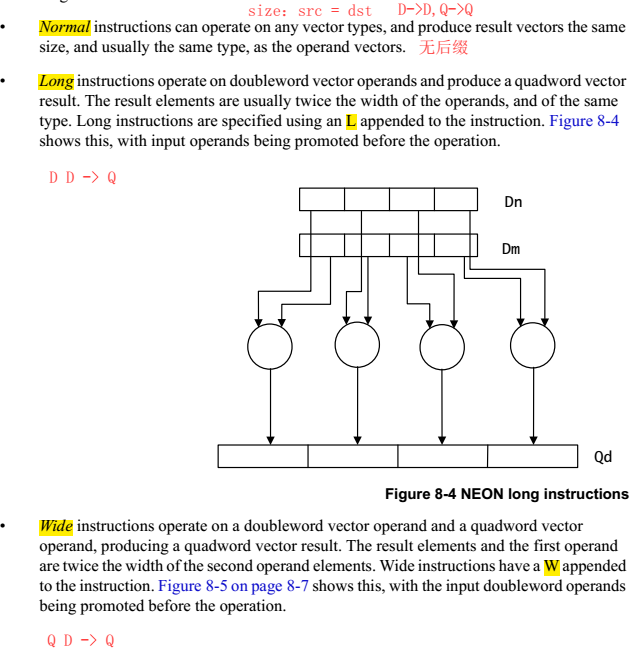
NEON的指令有Normal,Long,Wide,Narrow和Saturating variants等幾種后綴,是根據操作的源src和dst寄存器的類型確定的。
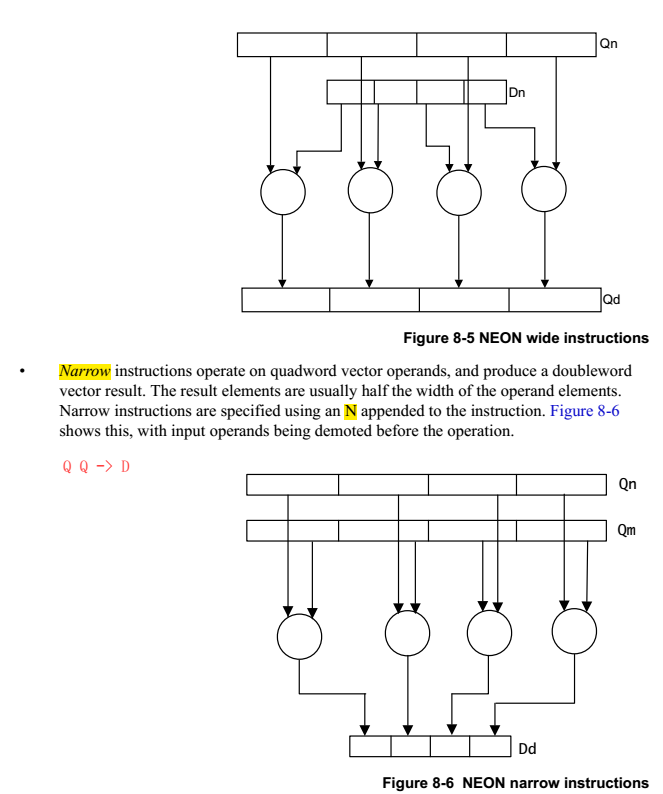
1.2.4 instruction set

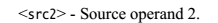
1.3 NEON 指令分類概述
指令比較多, 詳細可參考Cortex™-A Series Programmer's Guide。可大體分為:
NEON general data processing instructions NEON shift instructions NEON logical and compare operations NEON arithmetic instructions NEON multiply instructions NEON load and store element and structure instructions B.8 NEON and VFP pseudo-instructions
簡單羅列一下各指令
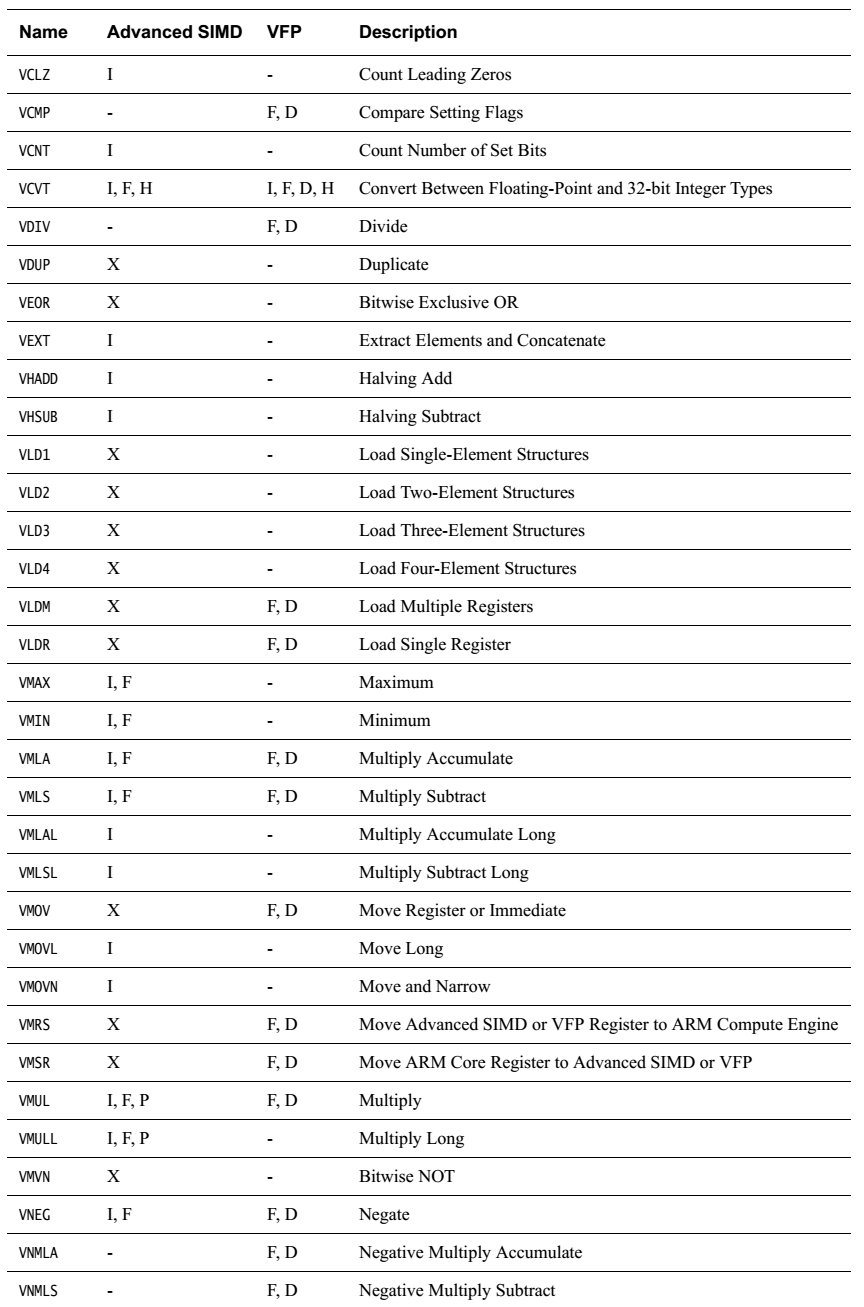
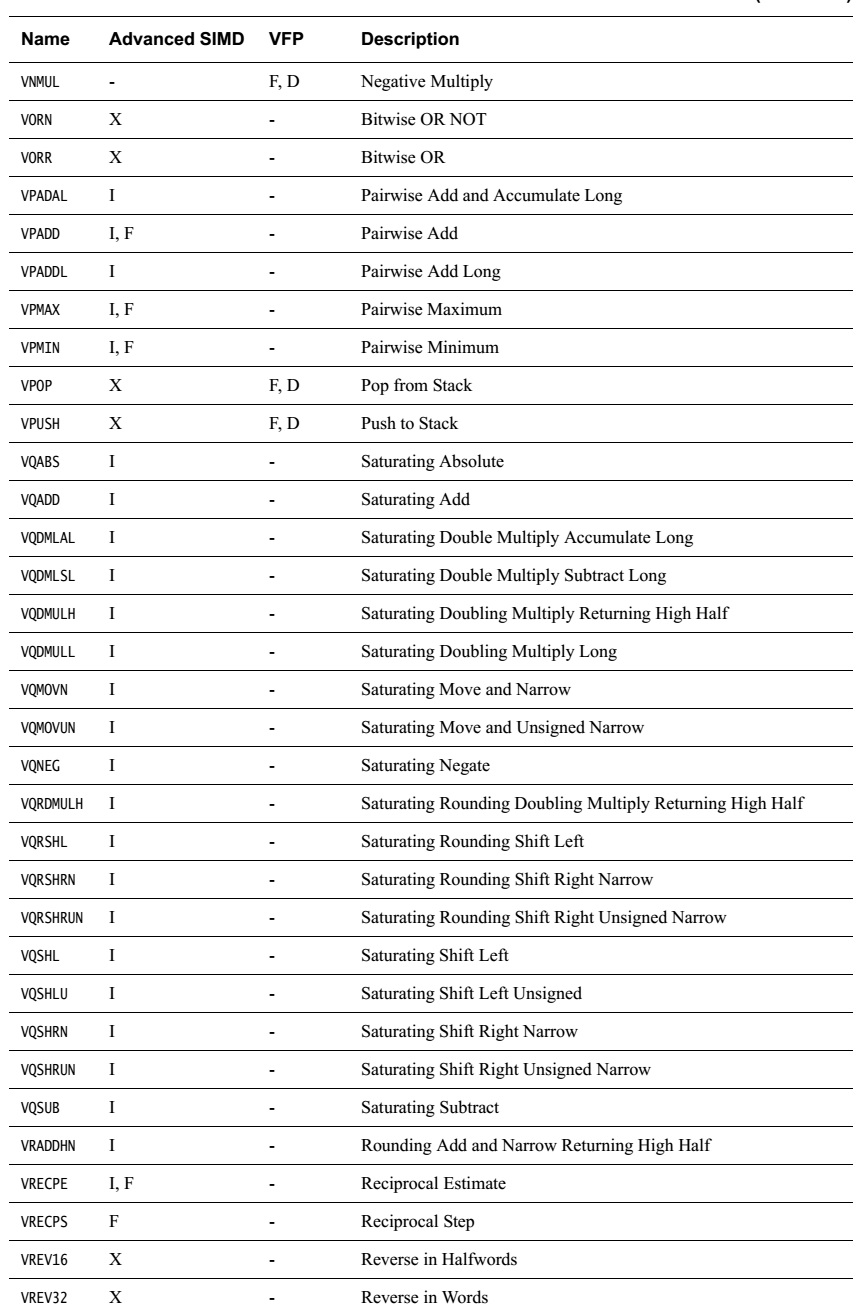
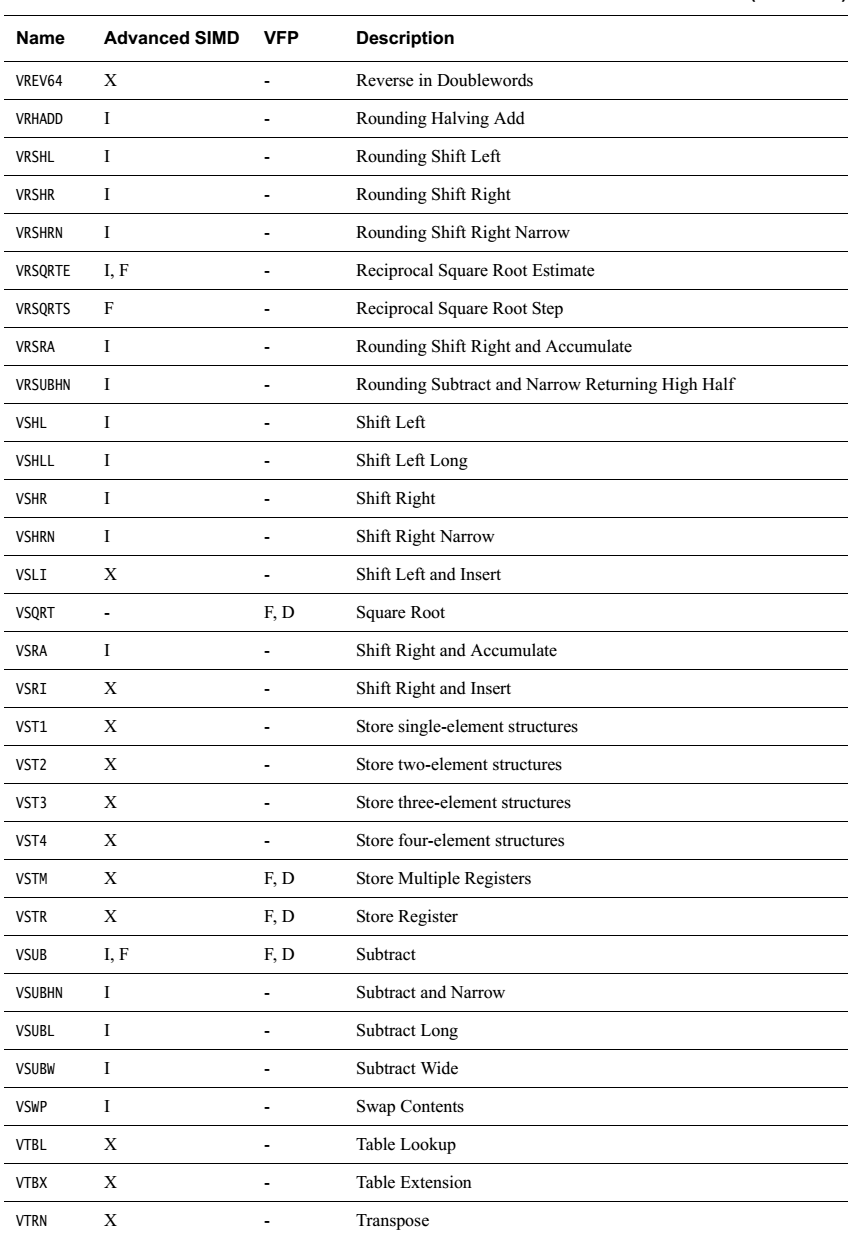
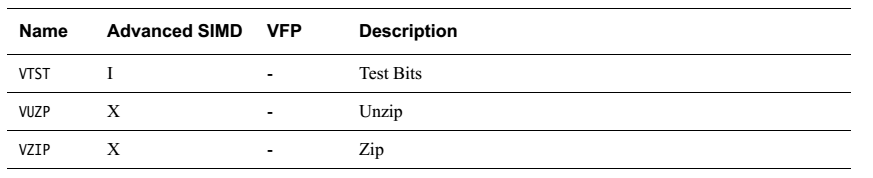
無循環左移,負數左移按右移處理。
load和store指令不太好理解,說明一下。

1.4 NEON 使用方式
1.4.1 NEON使用方式
NEON有若干種使用方式:
C語言被編譯器自動向量化,需要增加編譯選項,且C語言編碼時有若干注意事項。這種方式不確定性太大,沒啥實用價值 NEON匯編,可行,匯編稍微復雜一點,但是核心算法還是值得的 intrinsics,gcc和armcc等編譯器提供了若干與NEON對應的inline函數,可直接在C語言里調用,這些函數反匯編時會直接編程響應的NEON指令。這種方式比較實用與C語言環境,且相對簡單。本文后續使用這種方式進行詳細說明。 1.4.2 C語言NEON數據類型
需包含arm_neon.h頭文件,該頭文件在gcc目錄里。都是向量數據。
typedef __builtin_neon_qi int8x8_t __attribute__ ((__vector_size__ (8)));
typedef __builtin_neon_hi int16x4_t __attribute__ ((__vector_size__ (8)));
typedef __builtin_neon_si int32x2_t __attribute__ ((__vector_size__ (8)));
typedef __builtin_neon_di int64x1_t;
typedef __builtin_neon_sf float32x2_t __attribute__ ((__vector_size__ (8)));
typedef __builtin_neon_poly8 poly8x8_t __attribute__ ((__vector_size__ (8)));
typedef __builtin_neon_poly16 poly16x4_t __attribute__ ((__vector_size__ (8)));
typedef __builtin_neon_uqi uint8x8_t __attribute__ ((__vector_size__ (8)));
typedef __builtin_neon_uhi uint16x4_t __attribute__ ((__vector_size__ (8)));
typedef __builtin_neon_usi uint32x2_t __attribute__ ((__vector_size__ (8)));
typedef __builtin_neon_udi uint64x1_t;
typedef __builtin_neon_qi int8x16_t __attribute__ ((__vector_size__ (16)));
typedef __builtin_neon_hi int16x8_t __attribute__ ((__vector_size__ (16)));
typedef __builtin_neon_si int32x4_t __attribute__ ((__vector_size__ (16)));
typedef __builtin_neon_di int64x2_t __attribute__ ((__vector_size__ (16)));
typedef __builtin_neon_sf float32x4_t __attribute__ ((__vector_size__ (16)));
typedef __builtin_neon_poly8 poly8x16_t __attribute__ ((__vector_size__ (16)));
typedef __builtin_neon_poly16 poly16x8_t __attribute__ ((__vector_size__ (16)));
typedef __builtin_neon_uqi uint8x16_t __attribute__ ((__vector_size__ (16)));
typedef __builtin_neon_uhi uint16x8_t __attribute__ ((__vector_size__ (16)));
typedef __builtin_neon_usi uint32x4_t __attribute__ ((__vector_size__ (16)));
typedef __builtin_neon_udi uint64x2_t __attribute__ ((__vector_size__ (16)));
typedef float float32_t;
typedef __builtin_neon_poly8 poly8_t;
typedef __builtin_neon_poly16 poly16_t;
typedef struct int8x8x2_t
{
int8x8_t val[2];
} int8x8x2_t;
typedef struct int8x16x2_t
{
int8x16_t val[2];
} int8x16x2_t;
typedef struct int16x4x2_t
{
int16x4_t val[2];
} int16x4x2_t;
typedef struct int16x8x2_t
{
int16x8_t val[2];
} int16x8x2_t;
typedef struct int32x2x2_t
{
int32x2_t val[2];
} int32x2x2_t;
typedef struct int32x4x2_t
{
int32x4_t val[2];
} int32x4x2_t;
typedef struct int64x1x2_t
{
int64x1_t val[2];
} int64x1x2_t;
typedef struct int64x2x2_t
{
int64x2_t val[2];
} int64x2x2_t;
typedef struct uint8x8x2_t
{
uint8x8_t val[2];
} uint8x8x2_t;
typedef struct uint8x16x2_t
{
uint8x16_t val[2];
} uint8x16x2_t;
typedef struct uint16x4x2_t
{
uint16x4_t val[2];
} uint16x4x2_t;
typedef struct uint16x8x2_t
{
uint16x8_t val[2];
} uint16x8x2_t;
typedef struct uint32x2x2_t
{
uint32x2_t val[2];
} uint32x2x2_t;
typedef struct uint32x4x2_t
{
uint32x4_t val[2];
} uint32x4x2_t;
typedef struct uint64x1x2_t
{
uint64x1_t val[2];
} uint64x1x2_t;
typedef struct uint64x2x2_t
{
uint64x2_t val[2];
} uint64x2x2_t;
typedef struct float32x2x2_t
{
float32x2_t val[2];
} float32x2x2_t;
typedef struct float32x4x2_t
{
float32x4_t val[2];
} float32x4x2_t;
typedef struct poly8x8x2_t
{
poly8x8_t val[2];
} poly8x8x2_t;
typedef struct poly8x16x2_t
{
poly8x16_t val[2];
} poly8x16x2_t;
typedef struct poly16x4x2_t
{
poly16x4_t val[2];
} poly16x4x2_t;
typedef struct poly16x8x2_t
{
poly16x8_t val[2];
} poly16x8x2_t;
typedef struct int8x8x3_t
{
int8x8_t val[3];
} int8x8x3_t;
typedef struct int8x16x3_t
{
int8x16_t val[3];
} int8x16x3_t;
typedef struct int16x4x3_t
{
int16x4_t val[3];
} int16x4x3_t;
typedef struct int16x8x3_t
{
int16x8_t val[3];
} int16x8x3_t;
typedef struct int32x2x3_t
{
int32x2_t val[3];
} int32x2x3_t;
typedef struct int32x4x3_t
{
int32x4_t val[3];
} int32x4x3_t;
typedef struct int64x1x3_t
{
int64x1_t val[3];
} int64x1x3_t;
typedef struct int64x2x3_t
{
int64x2_t val[3];
} int64x2x3_t;
typedef struct uint8x8x3_t
{
uint8x8_t val[3];
} uint8x8x3_t;
typedef struct uint8x16x3_t
{
uint8x16_t val[3];
} uint8x16x3_t;
typedef struct uint16x4x3_t
{
uint16x4_t val[3];
} uint16x4x3_t;
typedef struct uint16x8x3_t
{
uint16x8_t val[3];
} uint16x8x3_t;
typedef struct uint32x2x3_t
{
uint32x2_t val[3];
} uint32x2x3_t;
typedef struct uint32x4x3_t
{
uint32x4_t val[3];
} uint32x4x3_t;
typedef struct uint64x1x3_t
{
uint64x1_t val[3];
} uint64x1x3_t;
typedef struct uint64x2x3_t
{
uint64x2_t val[3];
} uint64x2x3_t;
typedef struct float32x2x3_t
{
float32x2_t val[3];
} float32x2x3_t;
typedef struct float32x4x3_t
{
float32x4_t val[3];
} float32x4x3_t;
typedef struct poly8x8x3_t
{
poly8x8_t val[3];
} poly8x8x3_t;
typedef struct poly8x16x3_t
{
poly8x16_t val[3];
} poly8x16x3_t;
typedef struct poly16x4x3_t
{
poly16x4_t val[3];
} poly16x4x3_t;
typedef struct poly16x8x3_t
{
poly16x8_t val[3];
} poly16x8x3_t;
typedef struct int8x8x4_t
{
int8x8_t val[4];
} int8x8x4_t;
typedef struct int8x16x4_t
{
int8x16_t val[4];
} int8x16x4_t;
typedef struct int16x4x4_t
{
int16x4_t val[4];
} int16x4x4_t;
typedef struct int16x8x4_t
{
int16x8_t val[4];
} int16x8x4_t;
typedef struct int32x2x4_t
{
int32x2_t val[4];
} int32x2x4_t;
typedef struct int32x4x4_t
{
int32x4_t val[4];
} int32x4x4_t;
typedef struct int64x1x4_t
{
int64x1_t val[4];
} int64x1x4_t;
typedef struct int64x2x4_t
{
int64x2_t val[4];
} int64x2x4_t;
typedef struct uint8x8x4_t
{
uint8x8_t val[4];
} uint8x8x4_t;
typedef struct uint8x16x4_t
{
uint8x16_t val[4];
} uint8x16x4_t;
typedef struct uint16x4x4_t
{
uint16x4_t val[4];
} uint16x4x4_t;
typedef struct uint16x8x4_t
{
uint16x8_t val[4];
} uint16x8x4_t;
typedef struct uint32x2x4_t
{
uint32x2_t val[4];
} uint32x2x4_t;
typedef struct uint32x4x4_t
{
uint32x4_t val[4];
} uint32x4x4_t;
typedef struct uint64x1x4_t
{
uint64x1_t val[4];
} uint64x1x4_t;
typedef struct uint64x2x4_t
{
uint64x2_t val[4];
} uint64x2x4_t;
typedef struct float32x2x4_t
{
float32x2_t val[4];
} float32x2x4_t;
typedef struct float32x4x4_t
{
float32x4_t val[4];
} float32x4x4_t;
typedef struct poly8x8x4_t
{
poly8x8_t val[4];
} poly8x8x4_t;
typedef struct poly8x16x4_t
{
poly8x16_t val[4];
} poly8x16x4_t;
typedef struct poly16x4x4_t
{
poly16x4_t val[4];
} poly16x4x4_t;
typedef struct poly16x8x4_t
{
poly16x8_t val[4];
} poly16x8x4_t;
1.4.3 gcc的NEON函數
跟NEON指令對應,詳見gcc手冊。

二.內核狀態下使用NEON的規則
在linux里,應用態可以比較方便使用NEON instrinsic,增加頭arm_neon.h頭文件后直接使用。但是內核態下使用NEON有較多限制,在linux內核文檔 /Documentation/arm/kernel_mode_neon.txt對此有詳細說明。要點為:

還有一點特別關鍵:

CC [M] /work/platform-zynq/drivers/zynq_fpga_driver/mmi_neon/lcd_hw_fs8812_neon.o
In file included from /home/liuwanpeng/lin/lib/gcc/arm-xilinx-linux-gnueabi/4.8.3/include/arm_neon.h:39:0,
from /work/platform-zynq/drivers/zynq_fpga_driver/mmi_neon/lcd_hw_fs8812_neon.c:8:
/home/liuwanpeng/lin/lib/gcc/arm-xilinx-linux-gnueabi/4.8.3/include/stdint.h:9:26: error: no include path in which to search for stdint.h
# include_next <stdint.h>
沒有使用-ffreestanding編譯選項時,在內核態下使用出現此編譯錯誤。
三.實例
NEON一般在圖像等領域,最小處理單位就是8bit,而不是1bit,這方便的例子非常多,本文就不說明了。在實際項目中,我需要對液晶的一組數據按位操作,變換,形成新的數據,如果用傳統ARM指令,掩碼、移位、循環,想想效率就非常低。于是決定使用NEON的位相關指令完成上述任務。
3.1 任務說明
如下圖,需要對各個bit進行轉換,組成新的數據。

3.2 算法說明
使用vmsk、vshl、vadd等位操作完成。
3.3 kernel配置
必須配置內核支持NEON,否則kernel_neon_begin()和kernel_neon_end()等函數不會編輯進去。
make menuconfig:Floating point emulation,如下圖。
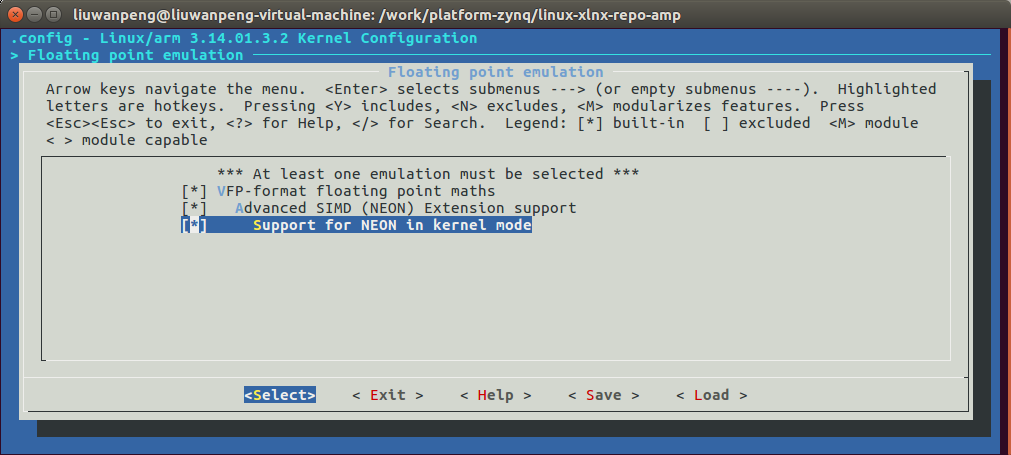
未使能“Support for NEON in kernel mode”時會報錯: mmi_module_amp: Unknown symbol kernel_neon_begin (err 0) mmi_module_amp: Unknown symbol kernel_neon_end (err 0)
3.4 模塊代碼
由于NEON代碼需要單獨設置編譯選項,所以單獨建立了一個內核模塊,makefile如下:
CFLAGS_MODULE += -O3 -mfpu=neon -mfloat-abi=softfp -ffreestanding
核心代碼:
#include <linux/module.h> #include <linux/printk.h> #include <arm_neon.h> // 來自GCC的頭文件,必須用-ffreestanding編譯選徐昂
#define LCD_8812_ROW_BYTES 16
#define LCD_8812_PAGE_ROWS 8
#define LCD_PAGE_BYTES (LCD_8812_ROW_BYTES*LCD_8812_PAGE_ROWS)
int fs8812_cvt_buf( uint8 * dst, uint8 * src )
{
uint8x16_t V_src[8];
uint8x16_t V_tmp[8];
uint8x16_t V_dst[8];
uint8x16_t V_msk;
int8x16_t V_shift;
int8 RSHL_bits[8] = {0,1,2,3,4,5,6,7};
int8 row,bit;
uint8 page;
uint8 * fb_page_x = NULL;
// convert the frame_buf for fs8812
for( page=0;page<4;page++ ){
fb_page_x = src + page*LCD_PAGE_BYTES;
for( row=0;row<LCD_8812_PAGE_ROWS;row++ )
V_src[row] = vld1q_u8( fb_page_x + row*LCD_8812_ROW_BYTES );
for( bit=0;bit<8;bit++){
V_msk = vdupq_n_u8(1<<bit);
for( row=0;row<LCD_8812_PAGE_ROWS;row++){
V_tmp[row] = vandq_u8(V_src[row],V_msk); // only process the desire bit
V_shift = vdupq_n_s8( RSHL_bits[row]-bit );
V_tmp[row] = vshlq_u8( V_tmp[row],V_shift );
}
V_dst[bit] = vorrq_u8(V_tmp[0],V_tmp[1]); // all bit_x convert to one row
V_dst[bit] |= vorrq_u8(V_tmp[2],V_tmp[3]);
V_dst[bit] |= vorrq_u8(V_tmp[4],V_tmp[5]);
V_dst[bit] |= vorrq_u8(V_tmp[6],V_tmp[7]);
}
// store to ram
fb_page_x = dst + page*LCD_PAGE_BYTES;
for( row=0;row<LCD_8812_PAGE_ROWS;row++ ){
vst1q_u8(fb_page_x,V_dst[row]);
fb_page_x += LCD_8812_ROW_BYTES;
}
}
return 0;
}
EXPORT_SYMBOL_GPL(fs8812_cvt_buf);
調用模塊,務必沒有“-mfpu=neon -mfloat-abi=softfp ”選項
// convert the frame_buf for fs8812 kernel_neon_begin(); fs8812_cvt_buf( g_tmp_buf, frame_buf ); kernel_neon_end();
以上就是本篇文章的全部內容,大家有不懂的可以在下面留言區討論。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





