溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何使用python實現百度新歌榜、熱歌榜下載器,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
前言
首先聲明,本工具僅僅為學習之用,不涉及版權問題,因為百度音樂里面的歌曲本身是可以下載的,而且現在百度也提供了”百度音樂播放器”,可以通過這個工具進行批量下載。
我當時做這個工具的時候,百度還沒有提供”百度音樂播放器”,而我又想批量下載,所以做了這樣的一個下載工具。當然,主要還是為了學習。
工具采用Python2.7.3+PyQt開發。
功能:
1.集中展示百度新歌榜或熱歌榜可下載的歌單。
2.支持單個、多個歌曲的下載。
3.可復制歌單中所有的鏈接內容,方便在迅雷等下載工具中創建下載組。
缺陷:
目前采用單線程,效率不高,UI界面容易假死。
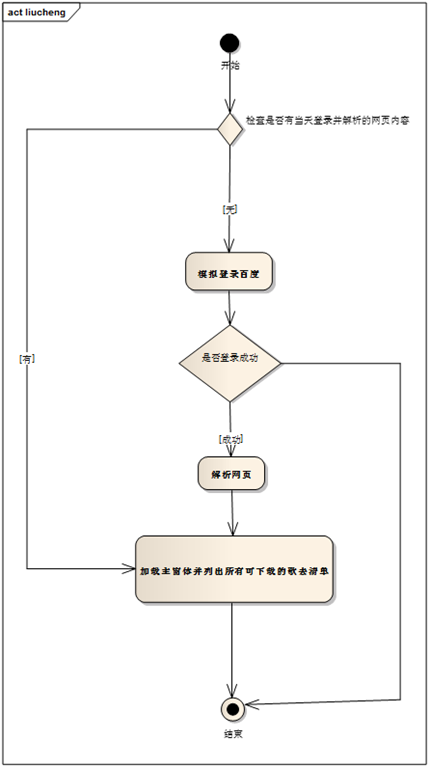
本工具運行流程:
1.模擬用戶登錄百度。
2.若登錄成功,采集并解析頁面內容,加載歌單列表。
3.用戶點擊下載按鈕或者批量下載按鈕后,下載歌曲。
使用方法:
1.在配置文件setting.py的最后,配置可登錄百度的賬號和密碼,及百度熱歌榜或新歌榜的URL.
username = "your baidu acount" #配置你的百度賬號 password = "your baidu password" #配置你的百度密碼 musiclistUrl = "http://music.baidu.com/top/dayhot" # http://music.baidu.com/top/new
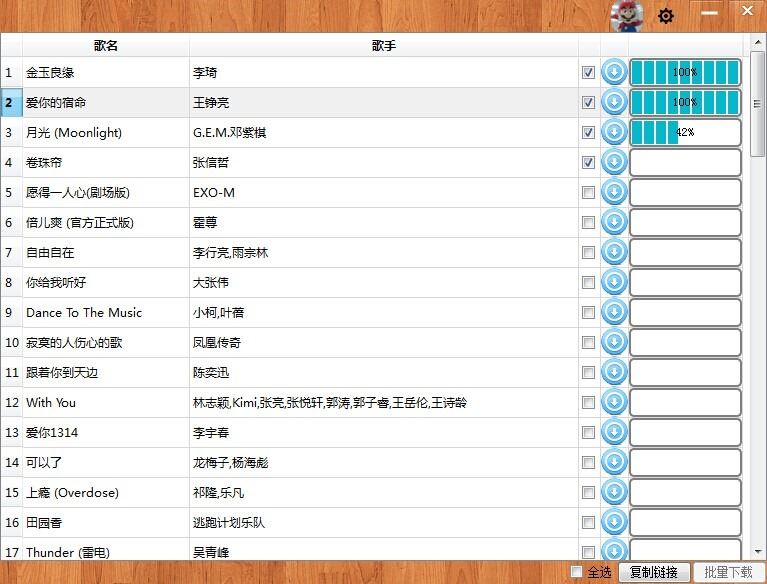
2.直接運行mainWindow.py文件即可,如果網速不給力的話可能要等上3、4分鐘。
運行后如圖:
用到的知識:
1.首先用到了PyQt的GUI編程,窗體布局及QTableWidget、QProgressBar、QPushButton等控件及控件的重寫
2.用到了網絡編程的部分內容,利用urllib,urllib2,cookielib請求網頁,模擬登錄百度。
3.利用HTMLParser解析網頁內容,匹配網頁元素。
4.利用codecs進行文件的讀寫。
遇到的問題:
1.編碼問題,由于在創建文件時將文件編碼設置為UTF-8,當需要向文件寫入的內容為中文等非ASCII碼內容時,總是提示編碼問題。其實,百度音樂的網頁全部為UTF-8格式,因此從網頁中獲取的內容也是UTF-8格式,但是,要講內容寫入UTF-8的文本中,必須將網頁內容進行decode(“utf8”)解碼為unicode格式,才能正常寫入。
檢測內容編碼,可以用chardet模塊的chardet.detect(“內容”)的方法。
另外,HTMLParser解析網頁內容過程中,有的下載頁面會出現問題,根據提示信息發現還是編碼問題,將feed()方法中的內容參數進行decode(“utf8”)后,結果正常。
decode將內容根據參數內容解碼為unicode類型,具體要根據所采集的頁面的編碼。
關于“如何使用python實現百度新歌榜、熱歌榜下載器”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





