溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Python3從零開始怎么搭建一個語音對話機器人,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
01-初心緣由
目前來說最流行的語音識別算法主要是依賴于深度學習的神經網絡算法,其中RNN扮演了非常重要的作用,深度學習的應用真正讓語音識別達到了商用級別。然后我想動手自己做一個語音識別系統,從GitHub上下載了兩個流行的開源項目MASR和ASRT來進行復現,發現語音識別的效果沒有寫的那么好,其中如果要從零來訓練自己的語言模型勢必會非常耗時。
因此,就有了一個新的想法,借助一些開源的語音識別SDK來實現語音識別,來看看他們語音識別的效果如何。于是想到了百度和科大訊飛,然后就百度了一下,百度搜索舉賢不避親的給我推薦了百度AI開放平臺!然后查看了百度語音識別的技術文檔,發現對python的支持非常友好,而科大訊飛好像沒有提供對python的接口支持,因而選定了百度。

雖然百度目前槽點很多,但是不得不說百度在AI方面的投入和開放是值得點贊的!百度的AI開放平臺確實為開發者們帶來很多的便利性,開放了非常多的AI服務,大家自行去注冊使用,百度大腦AI開放平臺地址:http://ai.baidu.com/ (PS:我確實沒收廣告費!)
經過體驗發現百度的語音識別準確率高的嚇人,完爆了GitHub上的開源項目N條街,然后在CSDN瀏覽各位博主的博客時發現,用百度語音識別的API和圖靈機器人的API可以做一個實時語音對話的機器人,感覺特別興奮,從而決定搭建一個自己的語音對話機器人。目前,我已經實現了我的語音對話機器人,因此特意來分享一下整個的實現過程和遇到的坑,讓大家可以快速的構建你們的語音對話機器人。好啦,我們開始吧!
02-準備工作
(1)準備python開發環境
需要準備的python包包括:speech_recognition(語音識別包)、pyaudio(錄音接口)、wave(打開錄音文件并設置音頻參數)、pyttst3(文本轉語音)、json(解析json串)、requests(get/post)、baid_aip(百度語音識別的aip)。
(2)準備百度API
登錄百度AI開放平臺語音識別:https://ai.baidu.com/tech/speech/asr ,如果沒有賬號自己注冊即可,免費試用哦。
點擊技術文檔:閱讀語音識別的技術文檔,重點查看API文檔和Python SDK,了解如何在python中調用API接口。

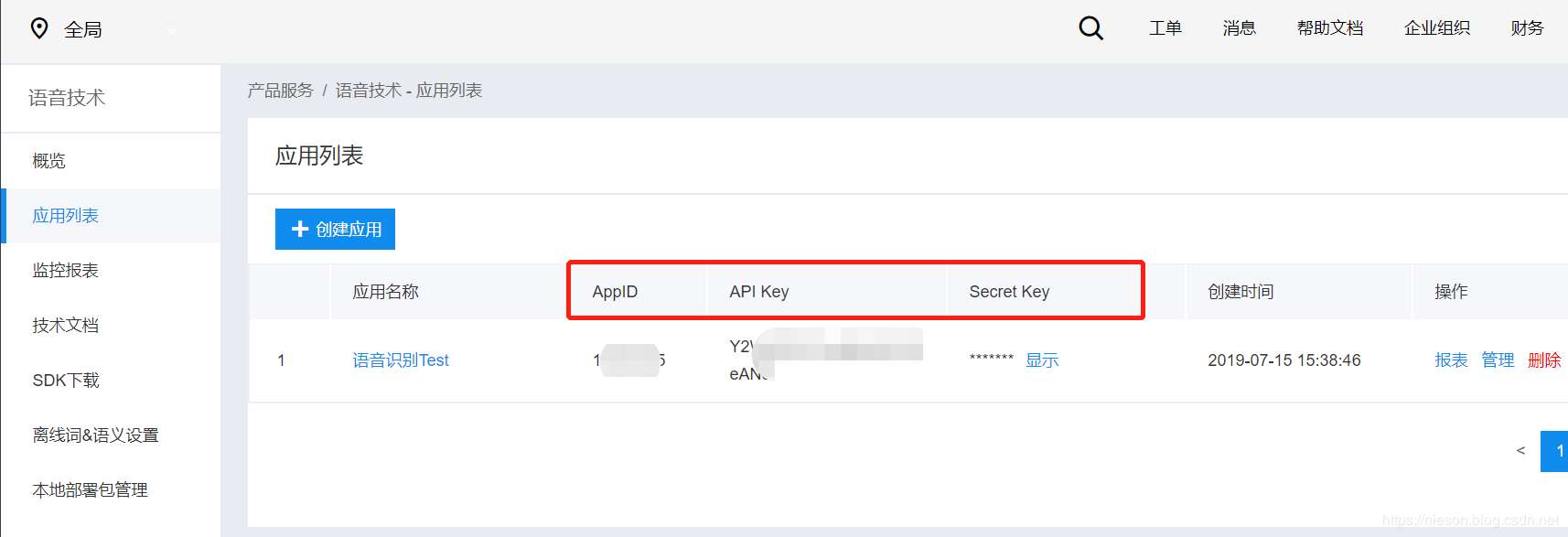
點擊立即使用:進入到服務界面,創建應用。記住最重要的App ID、API Key、Secret Key,后面調用時需要用到。
(3)準備圖靈機器人:
圖靈機器人大腦具備強大的中文語義分析能力,可準確理解中文含義并作出回應,是最擅長聊中文的機器人大腦,賦予軟硬件產品自然流暢的人機對話能力。圖靈機器人是中文語境下智能度最高的“機器人大腦”,是全球較為先進的機器人中文語言認知與計算平臺,圖靈機器人對中文語義理解準確率已達90%,可為智能化軟硬件產品提供中文語義分析、自然語言對話、深度問答等人工智能技術服務。——源于百科(好吧,又和百度扯上點關系了。)
總之,就是需要你去圖靈機器人官網http://www.turingapi.com/注冊成功后,構建一個屬于你的圖靈機器人,用于后續將翻譯后的文本內容對圖靈機器人提問獲取回答,然后我們通過TTS處理就可以獲取語音輸出了。
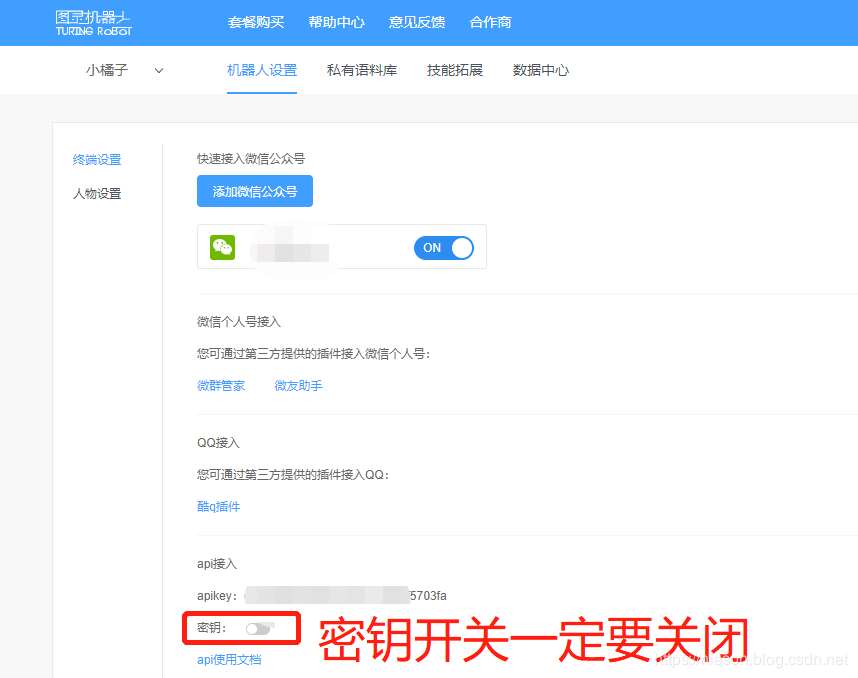
注冊后創建自己的機器人,然后在機器人設置的終端設置中查看自己的apikey(這個key非常重要),另外一定要把密鑰開關關閉,不然后面在調用api時會報3001錯誤,無法調用圖靈機器人(此處有坑,已填)!
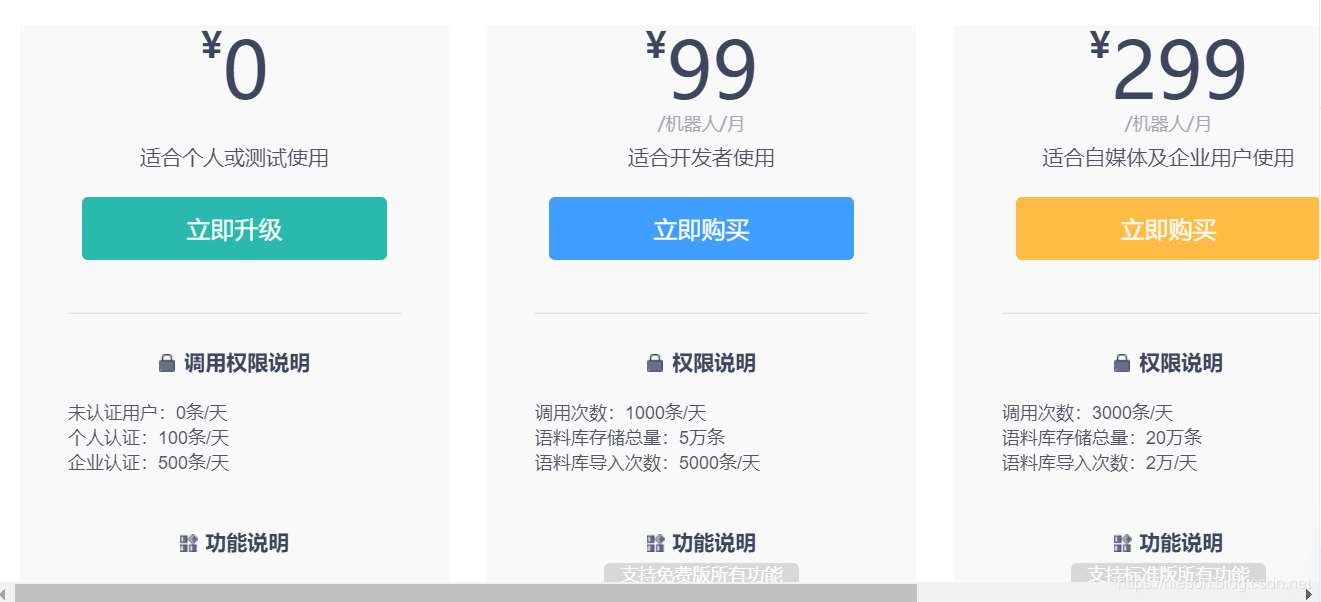
圖靈機器人未進行身份認證時,是不能夠進行調用的,如果調用會出現“請求次數超限制”的問題,通過個人身份認證后,每天能夠調用100次,這是免費版。100次當然是不夠用的,如果你想要更多的服務,就只能購買會員了,99和299每月的套餐,具體看下圖。如果是自己玩,那就免費版,如果是開發,可以考慮99的,如果是做一個產品,那就得企業采購了,咱們沒那么土豪!
03-語音機器人的搭建思路
1、首先明確我們要實現的目標,是要實現純語音對話聊天,不需要輸入文字交流。我們實時說,機器人實時回復,真正實現語音交互對話。
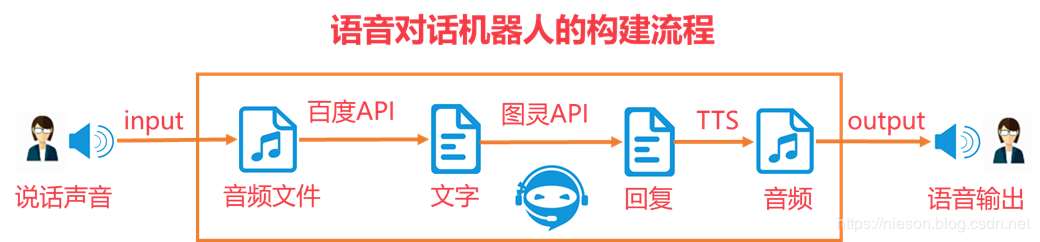
2、整個過程的實現流程是這樣的,我們說一句話,通過錄音保存為語音文件,然后調用百度API實現語音轉文本STT,再然后調用圖靈機器人API將文本輸入得到圖靈機器人的回復,最后將回復的文本轉成語音輸出TTS,就這樣我們就實現了和機器人的語音對話了!是不是有點繞,來個流程圖吧!
3、語音對話機器人的構建具體流程圖,就是各種掉API,千萬不要覺得頭暈哦,思路清晰才能走下去。
04-語音生成音頻文件
語音生產文件就需要進行錄音,將我們說的話保存下來,至于保存的格式我一般都是保存為wav,其他格式支持pcm,不太建議mp3,因為需要多次轉換。【百度服務端會將非pcm格式,轉為pcm格式,因此使用wav會有額外的轉換耗時,但是windows自帶播放器識別不了pcm格式的,所以我還是喜歡用wav格式】
第一種錄音方式:使用speech_recognition包進行錄音,這個錄音出來的效果比較好,而且代碼量非常少。
import speech_recognition as sr
# Use SpeechRecognition to record 使用語音識別包錄制音頻
def my_record(rate=16000):
r = sr.Recognizer()
with sr.Microphone(sample_rate=rate) as source:
print("please say something")
audio = r.listen(source)
with open("voices/myvoices.wav", "wb") as f:
f.write(audio.get_wav_data())
print("錄音完成!")
my_record()第二種錄音方式:使用wave和pyaudio包進行錄音,在python中直接使用pip install即可。
import wave
from pyaudio import PyAudio, paInt16
framerate = 16000 # 采樣率
num_samples = 2000 # 采樣點
channels = 1 # 聲道
sampwidth = 2 # 采樣寬度2bytes
FILEPATH = 'voices/myvoices.wav'
def save_wave_file(filepath, data):
wf = wave.open(filepath, 'wb')
wf.setnchannels(channels)
wf.setsampwidth(sampwidth)
wf.setframerate(framerate)
wf.writeframes(b''.join(data))
wf.close()
#錄音
def my_record():
pa = PyAudio()
#打開一個新的音頻stream
stream = pa.open(format=paInt16, channels=channels,
rate=framerate, input=True, frames_per_buffer=num_samples)
my_buf = [] #存放錄音數據
t = time.time()
print('正在錄音...')
while time.time() < t + 10: # 設置錄音時間(秒)
#循環read,每次read 2000frames
string_audio_data = stream.read(num_samples)
my_buf.append(string_audio_data)
print('錄音結束.')
save_wave_file(FILEPATH, my_buf)
stream.close()05-音頻文件轉文字STT
我們已經在上面獲取到了音頻文件,那要怎么把音頻文件轉化為文字呢?在這里,我們就需要調用百度的語音識別API接口,同時我們需要安裝這個接口包,導入模塊:pip install baidu_aip。導入我們需要的模塊名,然后將音頻文件發送給出去,返回文字。
# 音頻文件轉文字:采用百度的語音識別python-SDK
# 百度語音識別API配置參數
from aip import AipSpeech
APP_ID = 'your app_id'
API_KEY = 'your api_key'
SECRET_KEY = 'your secret_key'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
path = 'voices/myvoices.wav'
# 將語音轉文本STT
def listen():
# 讀取錄音文件
with open(path, 'rb') as fp:
voices = fp.read()
try:
# 參數dev_pid:1536普通話(支持簡單的英文識別)、1537普通話(純中文識別)、1737英語、1637粵語、1837四川話、1936普通話遠場
result = client.asr(voices, 'wav', 16000, {'dev_pid': 1537, })
# result = CLIENT.asr(get_file_content(path), 'wav', 16000, {'lan': 'zh', })
# print(result)
# print(result['result'][0])
# print(result)
result_text = result["result"][0]
print("you said: " + result_text)
return result_text
except KeyError:
print("KeyError")06-與圖靈機器人對話
上一步我們已經成功將我們的聲音轉化為文字了,然后我們再調用圖靈機器人的API接口,做自動應答。圖靈機器人對中文的識別準確率高達90%,是目前中文語境下智能度最高的機器人。有很多在Python中使用圖靈機器人API的博客,但都是1.0版本,本博客介紹的是在Python中使用圖靈機器人API v2.0的方法,1.0版本的調用方式已失效。
代碼如下(這里需要導入requests、json模塊):
# 與機器人對話:調用的是圖靈機器人
import requests
import json
# 圖靈機器人的API_KEY、API_URL
turing_api_key = "your turing_api_key"
api_url = "http://openapi.tuling123.com/openapi/api/v2" # 圖靈機器人api網址
headers = {'Content-Type': 'application/json;charset=UTF-8'}
# 圖靈機器人回復
def Turing(text_words=""):
req = {
"reqType": 0,
"perception": {
"inputText": {
"text": text_words
},
"selfInfo": {
"location": {
"city": "北京",
"province": "北京",
"street": "車公莊西大街"
}
}
},
"userInfo": {
"apiKey": turing_api_key, # 你的圖靈機器人apiKey
"userId": "Nieson" # 用戶唯一標識(隨便填, 非密鑰)
}
}
req["perception"]["inputText"]["text"] = text_words
response = requests.request("post", api_url, json=req, headers=headers)
response_dict = json.loads(response.text)
result = response_dict["results"][0]["values"]["text"]
print("AI Robot said: " + result)
return result07-文字轉語音
我們得到了圖靈機器人的回復之后,就需要把結果轉化為語音輸出,從而實現語音交互。在python中我們如何將文字轉為語音并輸出呢?這里就需要用到另一個模塊pyttsx3,它會將文字轉為語音。
import pyttsx3
# 初始化語音
engine = pyttsx3.init() # 初始化語音庫
# 設置語速
rate = engine.getProperty('rate')
engine.setProperty('rate', rate-50)
# 輸出語音
engine.say("你好,很高興認識你!") # 合成語音
engine.runAndWait()使用python進行編程就是有很多好處,比如音頻的輸出我們就可以采用多種方式,下面提供一種更加簡便的音頻輸出方式:
import win32com.client
speaker = win32com.client.Dispatch("SAPI.SpVoice")
speaker.Speak("我是語音助手,小靈!")好了,至此,我們語音機器人的所有元素都已經準備妥當,接下來進行組裝!
08-語音對話機器人的完整代碼
經過我的努力,已經將代碼優化到了100行左右哦,按照我的步驟來,你就可以快速復現構建你的語音機器人了!
# -*- coding: utf-8 -*-#
# -------------------------------
# Name:SpeechRobot
# Author:Nieson
# Date:2019/7/19 16:31
# 用python3實現自己的語音對話機器人
# -------------------------------
from aip import AipSpeech
import requests
import json
import speech_recognition as sr
import win32com.client
# 初始化語音
speaker = win32com.client.Dispatch("SAPI.SpVoice")
# 1、語音生成音頻文件,錄音并以當前時間戳保存到voices文件中
# Use SpeechRecognition to record 使用語音識別錄制
def my_record(rate=16000):
r = sr.Recognizer()
with sr.Microphone(sample_rate=rate) as source:
print("please say something")
audio = r.listen(source)
with open("voices/myvoices.wav", "wb") as f:
f.write(audio.get_wav_data())
# 2、音頻文件轉文字:采用百度的語音識別python-SDK
# 導入我們需要的模塊名,然后將音頻文件發送給出去,返回文字。
# 百度語音識別API配置參數
APP_ID = 'your app_id'
API_KEY = 'your api_key'
SECRET_KEY = 'your secret_key'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
path = 'voices/myvoices.wav'
# 將語音轉文本STT
def listen():
# 讀取錄音文件
with open(path, 'rb') as fp:
voices = fp.read()
try:
# 參數dev_pid:1536普通話(支持簡單的英文識別)、1537普通話(純中文識別)、1737英語、1637粵語、1837四川話、1936普通話遠場
result = client.asr(voices, 'wav', 16000, {'dev_pid': 1537, })
# result = CLIENT.asr(get_file_content(path), 'wav', 16000, {'lan': 'zh', })
# print(result)
# print(result['result'][0])
# print(result)
result_text = result["result"][0]
print("you said: " + result_text)
return result_text
except KeyError:
print("KeyError")
speaker.Speak("我沒有聽清楚,請再說一遍...")
# 3、與機器人對話:調用的是圖靈機器人
# 圖靈機器人的API_KEY、API_URL
turing_api_key = "your turing_api_key"
api_url = "http://openapi.tuling123.com/openapi/api/v2" # 圖靈機器人api網址
headers = {'Content-Type': 'application/json;charset=UTF-8'}
# 圖靈機器人回復
def Turing(text_words=""):
req = {
"reqType": 0,
"perception": {
"inputText": {
"text": text_words
},
"selfInfo": {
"location": {
"city": "北京",
"province": "北京",
"street": "車公莊"
}
}
},
"userInfo": {
"apiKey": turing_api_key, # 你的圖靈機器人apiKey
"userId": "Nieson" # 用戶唯一標識(隨便填, 非密鑰)
}
}
req["perception"]["inputText"]["text"] = text_words
response = requests.request("post", api_url, json=req, headers=headers)
response_dict = json.loads(response.text)
result = response_dict["results"][0]["values"]["text"]
print("AI Robot said: " + result)
return result
# 語音合成,輸出機器人的回答
while True:
my_record()
request = listen()
response = Turing(request)
speaker.Speak(response)09-結束語
至此,我們就構建了一個完整的語音對話機器人,它可以在你無聊、寂寞、有壓力、想開心的時候出現在你身邊,哄你開心喲!這個機器人太聰明了,你可千萬不要被她調戲了!
對了,你可以在圖靈機器人官網里面進行人物設置,設置她的姓名、年齡和星座,我的機器人叫做小橘子,她具有十八般武藝,它能夠閑聊、做數字計算、中英互譯、講故事、笑話、腦筋急轉彎、歇后語、繞口令、順口溜、玩成語接龍游戲,天氣和日期查詢,功能還是比較強大的!如果開通
付費版本就會擁有更多功能哦,可以訓練自己的語料庫,目前免費版只支持每天100次的調用,真真是不夠用呀!
附帶一下我和小橘子的聊天視頻吧,有心的小伙伴可以做個前端頁面哦!
優酷視頻:https://v.youku.com/v_show/id_XNDI3OTYyMTgwNA==.html?spm=a2h4j.8428770.3416059.1
10-有問必答
博客一經發出,兩天多的時間,閱讀量就已經突破5000了,得到了眾多博友的關注點贊和評論,說明大家對于語音對話機器人的熱情和興趣度都非常高,大家都在積極的搭建自己的語音對話機器人了!相信百度和圖靈機器人最近的API調用量會蹭蹭的上漲,我在考慮要不要收點推廣費了(哈哈,開個玩笑)!百度AI開放平臺你注冊調用他們的API后,過兩天百度就會有客服給你打電話問題的體驗感,大家看到一個北京號碼標記為詐騙電話的那個就是了哈哈!圖靈機器人公司則是通過會員收費模式來賺大家的錢,就看你能否攥緊自己的口袋了!
第10個模塊有問必答是為了來解答一下大家在復現語音對話機器人過程中可能會遇到的問題,根據大家的提問,我有針對性的把一些常見問題在此給各位進行一下解答,也非常歡迎博友們之間積極回復,畢竟博主的精力也是有限的,還要投入到無限的AI能力研究中去(可能也是因為懶吧)。剛好,十個模塊湊齊了十全十美,處女座看起來也舒心一些!閑話少敘,進入正題:
(1)問:我直接執行你全部代碼的時候為什么跑不通呢?
答:首先強調一點,各位在復現代碼的時候,一定要把百度和圖靈機器人的相關api_id, api_key等替換成自己的!另外圖靈機器人記得要身份驗證,通過后才能調用圖靈機器人!
(2)問:我在運行之后輸出please say something,然后我說了話,之后隔一段時間才輸出KeyError,AI Robot said: 請求次數超限制!這是什么原因?
答:因為在05-音頻文件轉文字STT中,為了避免有時候錄音文件出現問題,特別是在不帶耳機直接對著筆記本說話時,如果周圍環境嘈雜,會導致錄音質量不佳,或者是長時間不說話,這些情況就會報Key Error的問題;另外最重要的一個,那就是圖靈機器人如果你注冊后未進行身份認證,或者身份認證未通過,那么你能調用API的次數為0次,也就是說圖靈機器人不會給你回復,就會出現“請求次數超限制”。通過認證后,目前能夠每天調用100次,也就是聊天100次也會出現“請求次數超限制”了。
(3)問:Mac電腦上沒有win32com怎么辦啊?
答:如果win32com不行,那你就用可以嘗試安裝一下pyttsx3包,用前文中提到的第一種語音輸出方式。我為了代碼整潔,所以沒有把第一種方式寫到完整代碼中(其實也寫了,寫博客的時候刪了而已,別問我為啥,為了整潔好看,lol!)。
(4)問:為什么我的with open那里說文件找不到?
答:那是因為我所有的錄音文件(如myvoices.wav)都在voices目錄下,所以要記得創建一下自己的文件夾目錄voices。
(5)問:不會python,有沒有Java版本?
答:大家看完python版本,可以嘗試用Java來復現一下,畢竟你都會Java了,百度API也支持Java調用哦,看官網哈!
(6)問:安裝包出現問題,主要是from aip import AipSpeech、import speech_recognition as sr中的aip、speech_recognition包為啥安裝不成功?
答:這兩個包比較特殊,在import的時候是aip和speech_recognition,但在install安裝的時候分別是baidu-aip和SpeechRecognition,這樣就能安裝成功啦!
以上是“Python3從零開始怎么搭建一個語音對話機器人”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





