溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何使用Python爬取QQ音樂評論并制成詞云圖,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
Python主要應用于:1、Web開發;2、數據科學研究;3、網絡爬蟲;4、嵌入式應用開發;5、游戲開發;6、桌面應用開發。
環境:Ubuntu16.4 python版本:3.6.4 庫:wordcloud
這次我們要講的是爬取QQ音樂的評論并制成云詞圖,我們這里拿周杰倫的等你下課來舉例。
第一步:獲取評論
我們先打開QQ音樂,搜索周杰倫的《等你下課》,直接拉到底部,發現有5000多頁的評論。
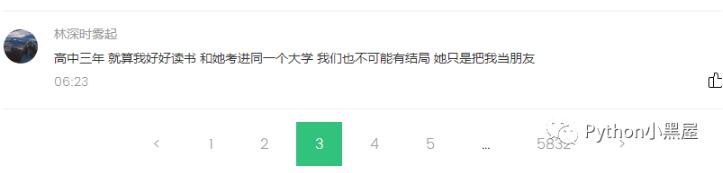
這時候我們要研究的就是怎樣獲取每頁的評論,這時候我們可以先按下F12,選擇NetWork,我們可以先點擊小紅點清空數據,然后再點擊一次,開始監控,然后點擊下一頁,看每次獲取評論的時候訪問獲取的是哪幾條數據。最后我們就能看到下圖的樣子,我們發現,第一條數據就是我們所要找的內容,點擊第一條數據,打開它的response拉到最下面,發現他的最后一條評論rootcommentcontent跟我們網頁中最后一條評論是一致的,那這時候已經成功了一般了,我們接下來只需要研究這條數據獲取的規律就可以獲取到所有的評論了。
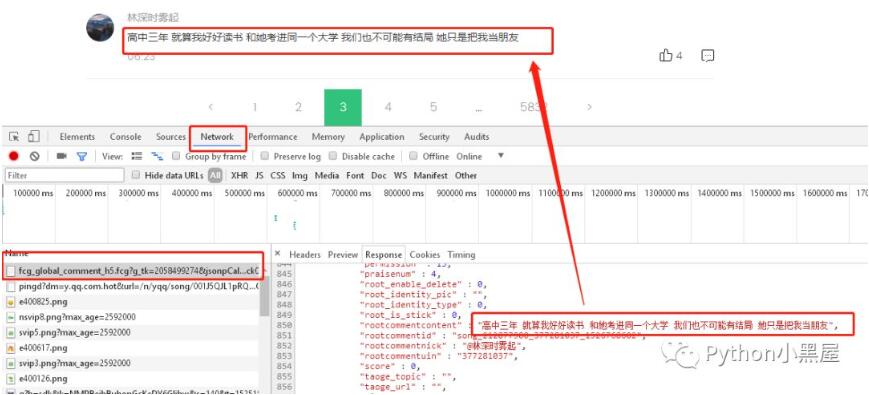
我們先查看這條數據的Headers分析下Request URL,通過點開不同的頁碼進行比較,發現每次發出的情況網址大部分內容是相同,不同的地方有兩個,就是pagenum跟JsonCallBack,pagenum從英文上很明顯能看出來就是頁碼,JsonCallBack又是啥呢?
https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h6.fcg?g_tk=2058499274&jsonpCallback=jsoncallback7494258674829413&loginUin=2230661779&hostUin=0&format=jsonp&inCharset=utf8&outCharset=GB2312¬ice=0&platform=yqq&needNewCode=0&cid=205360772&reqtype=2&biztype=1&topid=212877900&cmd=8&needmusiccrit=0&pagenum=4&pagesize=25&lasthotcommentid=song_212877900_23831021_1526748144&callback=jsoncallback7494258674829413&domain=qq.com&ct=24&cv=101010

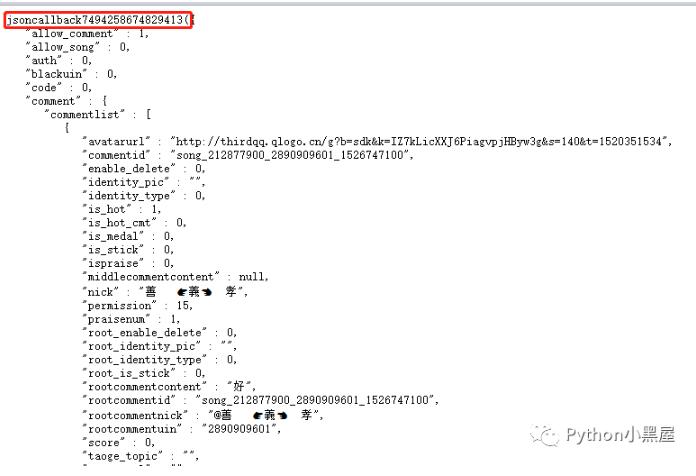
我們不妨將網址直接放在地址欄打開看看是怎樣。我們可以發現是直接返回一個不正規的json格式,為什么說是不正規呢?因為他在開頭多了個
jsoncallback7494258674829413
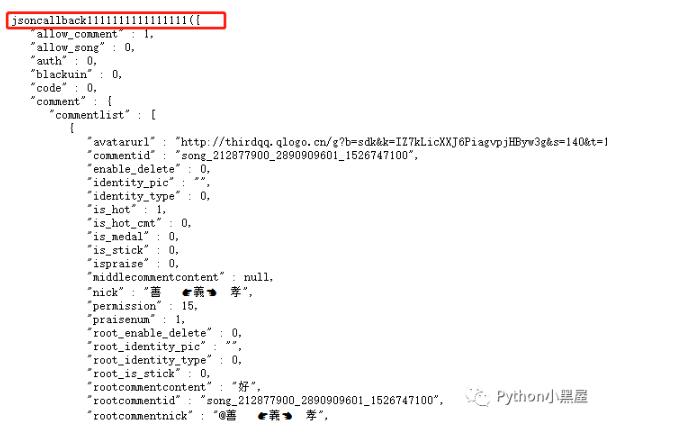
這個就是我們上面那個不知道怎么來的參數,我們嘗試在把這個數據改一下后再打開網址,結果發現,獲取的json內容是沒有變化,唯一變的是開頭jsoncallback1111111111
變成了我們輸入的那個數值,所以我們可以猜測這是一個隨機數,無論你輸入什么,都不會影響我們要獲取的內容。那這樣就好辦多了。
我們就直接放代碼獲取:
import requests
import json
def get_comment():
for i in range(1,7000):
# 打印頁碼
print(i)
# headers頭部
headers = {'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:59.0) Gecko/20100101 Firefox/59.0',
'Referer': "https://y.qq.com/n/yqq/song/0031TAKo0095np.html"}
# 請求的url
url = 'https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h6.fcg?g_tk=2058499274&jsonpCallback=jsoncallback06927647062927766&loginUin=2230661779&hostUin=0&format=jsonp&inCharset=utf8&outCharset=GB2312¬ice=0&platform=yqq&needNewCode=0&cid=205360772&reqtype=2&biztype=1&topid=212877900&cmd=8&needmusiccrit=0&pagenum=%s&pagesize=25&lasthotcommentid=song_212877900_3035803620_1526783365&callback=jsoncallback06927647062927766&domain=qq.com&ct=24&cv=101010' %i
# 打印當前訪問的url地址
print (url)
# 將請求得到的頁面賦值為req
req = requests.get(url,headers=headers,verify=False)
# 對獲取到的內容進行utf-8編碼
html = str(req.content,'UTF-8')
# 對非正規的json進行處理,去掉頭部跟尾部多余的部分
html= html.strip("jsoncallback06927647062927766(")
html = html.replace(")","")
# 去掉兩邊的空格
html = html.strip()
# 將處理后的json轉為python的json
data = json.loads(html)
# 獲取json中評論的部分
list = data['comment']['commentlist']
# 每次都重新定義一個列表來存儲每一頁的評論
content = []
# 遍歷當前頁的評論并通過調用write()函數來保存
for i in list:
# 偶爾也會有一頁的評論獲取不到,這時候如果報錯了可以直接忽略那一頁,繼續運行
try:
content.append(i['rootcommentcontent'].replace("[em]","").replace("[/em]","").replace("e400",""))
except KeyError:
content = []
break
write(content)
# 將當前頁面的評論傳遞過來
def write(content):
# 打開一個文件,將列表的內容一行一行的存儲下來
with open('comments.txt', 'a', encoding = 'UTF-8') as f:
for i in range(len(content)):
# 因為轉為json后\n不胡自動換行,所以我們這里將\n給手換行
string = content[i].split("\\n")
for i in string:
# 因為出現了很多評論被刪除的情況,所有我們把這句給過濾掉
i = i.replace("該評論已經被刪除", "")
# 打印每條評論
print (i)
# 將評論寫入文本
f.writelines(i)
# 給評論換行
f.write("\n")
if __name__ == "__main__":
get_comment()寫入文檔的內容大概就是這樣:

獲取完之后我們就能用wordcloud來進行詞云圖的制作了:
# -*- coding: utf-8 -*-
import jieba
from wordcloud import WordCloud, STOPWORDS
from os import path
from scipy.misc import imread
# 讀取mask/color圖片
d = path.dirname(__file__)
color_mask = imread("cyx.png")
#將爬到的評論放在string中
with open('nbzd.txt', 'r', encoding = 'UTF-8') as f:
string = f.read()
word = " ".join(jieba.cut(string))
wordcloud = WordCloud(background_color='white',
mask=color_mask,
max_words=100,
stopwords=STOPWORDS,
font_path='/home/azhao/桌面/素材/simsun.ttc',
max_font_size=100,
random_state=30,
margin=2).generate_from_text(word)
import matplotlib.pyplot as plt
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()最后展示的結果是這樣的:

關于“如何使用Python爬取QQ音樂評論并制成詞云圖”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





