溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
我們平時導入第三方模塊的時候,一般使用的是 import 關鍵字,例如:
import scrapy from scrapy.spider import Spider
但是如果各位同學看過 Scrapy 的 settings.py 文件,就會發現里面會通過字符串的方式來指定pipeline 和 middleware,例如:
DOWNLOADER_MIDDLEWARES = {
'Test.middlewares.ExceptionRetryMiddleware': 545,
'Test.middlewares.BOProxyMiddlewareV2': 543,
}
SPIDER_MIDDLEWARES = {
'Test.middlewares.LoggingRequestMiddleware': 543,
}
我們知道,這里的 Test.middlewares.ExceptionRetryMiddleware 實際上對應了根目錄下面的 Test 文件夾里面的 middlewares.py 文件中的 ExceptionRetryMiddleware 類。那么 Scrapy 是如何根據這個字符串,導入這個類的呢?
在 Scrapy 源代碼中,我們可以找到 相關的代碼 :
def load_object(path):
"""Load an object given its absolute object path, and return it.
object can be a class, function, variable or an instance.
path ie: 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware'
"""
try:
dot = path.rindex('.')
except ValueError:
raise ValueError("Error loading object '%s': not a full path" % path)
module, name = path[:dot], path[dot+1:]
mod = import_module(module)
try:
obj = getattr(mod, name)
except AttributeError:
raise NameError("Module '%s' doesn't define any object named '%s'" % (module, name))
return obj
根據這段代碼,我們知道,它使用了 importlib 模塊的 import_module 函數:
首先根據字符串路徑最右側的 . 把字符串路徑分成兩個部分,例如: Test.middlewares.LoggingRequestMiddleware 分成 Test.middlewares 和 LoggingRequestMiddleware
使用 import_module 導入左邊的部分
從左邊部分通過 getattr 獲得具體的類
現在我們來測試一下。我們創建的測試文件結構如下圖所示:
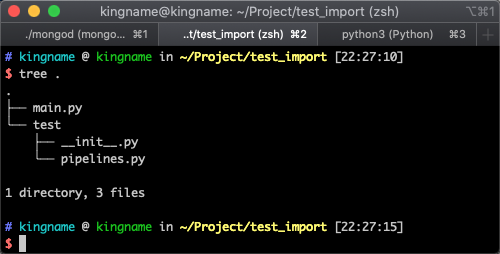
其中, pipelines.py 文件的內容如下圖所示:
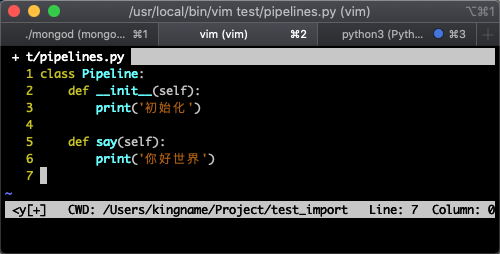
main.py 文件的內容如下圖所示:
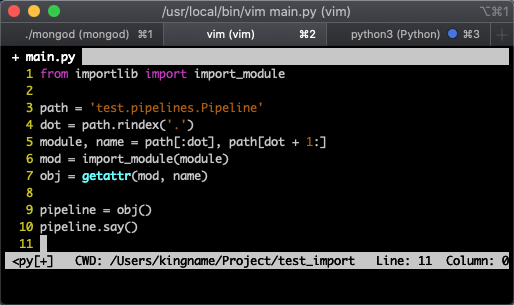
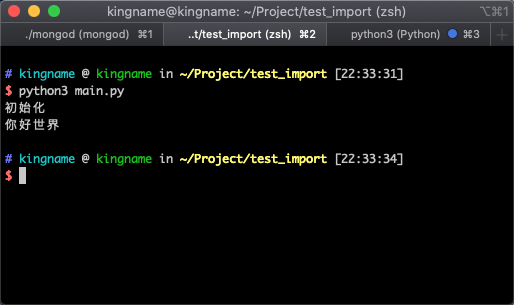
運行 main.py ,可以看到 pipelines.py 中的 Pipeline 類被成功執行了,如下圖所示:
總結
以上所述是小編給大家介紹的通過字符串導入 Python 模塊的方法詳解,希望對大家有所幫助,如果大家有任何疑問歡迎給我留言,小編會及時回復大家的!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





