溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何在Python中使用 import 機制遠程導入模塊,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
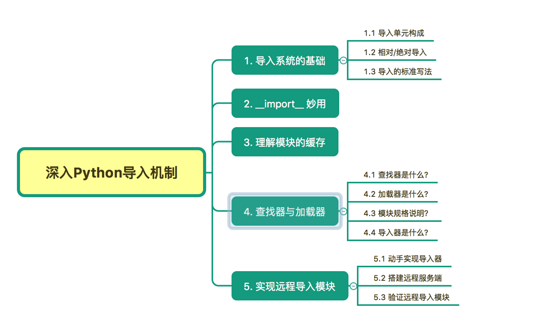
1.1 導入單元構成
導入單元有多種,可以是模塊、包及變量等。
對于這些基礎的概念,對于新手還是有必要介紹一下它們的區別。
模塊:類似 *.py,*.pyc, *.pyd ,*.so,*.dll 這樣的文件,是 Python 代碼載體的最小單元。
包還可以細分為兩種:
__init__.py
關于 Namespace packages,有的人會比較陌生,我這里摘抄官方文檔的一段說明來解釋一下。
Namespace packages 是由多個 部分 構成的,每個部分為父包增加一個子包。 各個部分可能處于文件系統的不同位置。 部分也可能處于 zip 文件中、網絡上,或者 Python 在導入期間可以搜索的其他地方。 命名空間包并不一定會直接對應到文件系統中的對象;它們有可能是無實體表示的虛擬模塊。
命名空間包的 __path__ 屬性不使用普通的列表。 而是使用定制的可迭代類型,如果其父包的路徑 (或者最高層級包的 sys.path) 發生改變,這種對象會在該包內的下一次導入嘗試時自動執行新的對包部分的搜索。
命名空間包沒有 parent/__init__.py 文件。 實際上,在導入搜索期間可能找到多個 parent 目錄,每個都由不同的部分所提供。 因此 parent/one 的物理位置不一定與 parent/two 相鄰。 在這種情況下,Python 將為頂級的 parent 包創建一個命名空間包,無論是它本身還是它的某個子包被導入。
1.2 相對/絕對導入
當我們 import 導入模塊或包時,Python 提供兩種導入方式:
相對導入(relative import ):from . import B 或 from ..A import B,其中.表示當前模塊,..表示上層模塊
絕對導入(absolute import):import foo.bar 或者 form foo import bar
你可以根據實際需要進行選擇,但有必要說明的是,在早期的版本( Python2.6 之前),Python 默認使用的相對導入。而后來的版本中( Python2.6 之后),都以絕對導入為默認使用的導入方式。
使用絕對路徑和相對路徑各有利弊:
當你在開發維護自己的項目時,應當使用相對路徑導入,這樣可以避免硬編碼帶來的麻煩。
而使用絕對路徑,會讓你模塊導入結構更加清晰,而且也避免了重名的包沖突而導入錯誤。
1.3 導入的標準寫法
在 PEP8 中對模塊的導入提出了要求,遵守 PEP8規范能讓你的代碼更具有可讀性,我這邊也列一下:
import 語句應當分行書寫
# bad import os,sys # good import os import sys
import語句應當使用absolute import
# bad from ..bar import Bar # good from foo.bar import test
import語句應當放在文件頭部,置于模塊說明及docstring之后,全局變量之前
import語句應該按照順序排列,每組之間用一個空格分隔,按照內置模塊,第三方模塊,自己所寫的模塊調用順序,同時每組內部按照字母表順序排列
# 內置模塊 import os import sys # 第三方模塊 import flask # 本地模塊 from foo import bar
1.4 幾個有用的 sys 變量
sys.path 可以列出 Python 模塊查找的目錄列表
>>> import sys >>> from pprint import pprint >>> pprint(sys.path) ['', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python36.zip', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/lib-dynload', '/Users/MING/Library/Python/3.6/lib/python/site-packages', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages'] >>>
sys.meta_path 存放的是所有的查找器。
>>> import sys >>> from pprint import pprint >>> pprint(sys.meta_path) [<class '_frozen_importlib.BuiltinImporter'>, <class '_frozen_importlib.FrozenImporter'>, <class '_frozen_importlib_external.PathFinder'>]
sys.path_importer_cache 比 sys.path 會更大點, 因為它會為所有被加載代碼的目錄記錄它們的查找器。 這包括包的子目錄,這些通常在 sys.path 中是不存在的。
>>> import sys
>>> from pprint import pprint
>>> pprint(sys.path_importer_cache)
{'/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6': FileFinder('/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6'),
'/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/collections': FileFinder('/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/collections'),
'/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/encodings': FileFinder('/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/encodings'),
'/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/lib-dynload': FileFinder('/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/lib-dynload'),
'/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages': FileFinder('/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages'),
'/Library/Frameworks/Python.framework/Versions/3.6/lib/python36.zip': None,
'/Users/MING': FileFinder('/Users/MING'),
'/Users/MING/Library/Python/3.6/lib/python/site-packages': FileFinder('/Users/MING/Library/Python/3.6/lib/python/site-packages')}import 關鍵字的使用,可以說是基礎中的基礎。
但這不是模塊唯一的方法,還有 importlib.import_module() 和 __import__() 等。
和 import 不同的是, __import__ 是一個函數,也正是因為這個原因,使得 __import__ 的使用會更加靈活,常常用于框架中,對于插件的動態加載。
實際上,當我們調用 import 導入模塊時,其內部也是調用了 __import__ ,請看如下兩種導入方法,他們是等價的。
# 使用 import
import os
# 使用 __import__
os = __import__('os')通過舉一反三,下面兩種方法同樣也是等價的。
# 使用 import .. as ..
import pandas as pd
# 使用 __import__
pd = __import__('pandas')上面我說 __import__ 常常用于插件的動態,事實上也只有它能做到(相對于 import 來說)。
插件 通常會位于某一特定的文件夾下,在使用過程中,可能你并不會用到全部的插件,也可能你會新增插件。
如果使用 import 關鍵字這種硬編碼的方式,顯然太不優雅了,當你要新增/修改插件的時候,都需要你修改代碼。更合適的做法是,將這些插件以配置的方式,寫在配置文件中,然后由代碼去讀取你的配置,動態導入你要使用的插件,即靈活又方便,也不容易出錯。
假如我的一個項目中,有 plugin01 、 plugin02 、 plugin03 、 plugin04 四個插件,這些插件下都會實現一個核心方法 run() 。但有時候我不想使用全部的插件,只想使用 plugin02 、 plugin04 ,那我就在配置文件中寫我要使用的兩個插件。
# my.conf custom_plugins=['plugin02', 'plugin04']
那我如何使用動態加載,并運行他們呢?
# main.py for plugin in conf.custom_plugins: __import__(plugin) sys.modules[plugin].run()
在一個模塊內部重復引用另一個相同模塊,實際并不會導入兩次,原因是在使用關鍵字 import 導入模塊時,它會先檢索 sys.modules 里是否已經載入這個模塊了,如果已經載入,則不會再次導入,如果不存在,才會去檢索導入這個模塊。
來實驗一下,在 my_mod02 這個模塊里,我 import 兩次 my_mod01 這個模塊,按邏輯每一次 import 會一次 my_mod01 里的代碼(即打印 in mod01 ),但是驗證結果是,只打印了一次。
$ cat my_mod01.py
print('in mod01')
$ cat my_mod02.py
import my_mod01
import my_mod01
$ python my_mod02.py
in mod01該現象的解釋是:因為有 sys.modules 的存在。
sys.modules 是一個字典(key:模塊名,value:模塊對象),它存放著在當前 namespace 所有已經導入的模塊對象。
# test_module.py
import sys
print(sys.modules.get('json', 'NotFound'))
import json
print(sys.modules.get('json', 'NotFound'))運行結果如下,可見在 導入后 json 模塊后, sys.modules 才有了 json 模塊的對象。
$ python test_module.py NotFound <module 'json' from 'C:\Python27\lib\json\__init__.pyc'>
由于有緩存的存在,使得我們無法重新載入一個模塊。
但若你想反其道行之,可以借助 importlib 這個神奇的庫來實現。事實也確實有此場景,比如在代碼調試中,在發現代碼有異常并修改后,我們通常要重啟服務再次載入程序。這時候,若有了模塊重載,就無比方便了,修改完代碼后也無需服務的重啟,就能繼續調試。
還是以上面的例子來理解, my_mod02.py 改寫成如下
# my_mod02.py import importlib import my_mod01 importlib.reload(my_mod01)
使用 python3 來執行這個模塊,與上面不同的是,這邊執行了兩次 my_mod01.py
$ python3 my_mod02.py in mod01 in mod01
如果指定名稱的模塊在 sys.modules 找不到,則將發起調用 Python 的導入協議以查找和加載該模塊。
此協議由兩個概念性模塊構成,即 查找器 和 加載器 。
一個 Python 的模塊的導入,其實可以再細分為兩個過程:
由查找器實現的模塊查找
由加載器實現的模塊加載
4.1 查找器是什么?
查找器(finder),簡單點說,查找器定義了一個模塊查找機制,讓程序知道該如何找到對應的模塊。
其實 Python 內置了多個默認查找器,其存在于 sys.meta_path 中。
但這些查找器對應使用者來說,并不是那么重要,因此在 Python 3.3 之前, Python 解釋將其隱藏了,我們稱之為隱式查找器。
# Python 2.7 >>> import sys >>> sys.meta_path [] >>>
由于這點不利于開發者深入理解 import 機制,在 Python 3.3 后,所有的模塊導入機制都會通過 sys.meta_path 暴露,不會在有任何隱式導入機制。
# Python 3.6 >>> import sys >>> from pprint import pprint >>> pprint(sys.meta_path) [<class '_frozen_importlib.BuiltinImporter'>, <class '_frozen_importlib.FrozenImporter'>, <class '_frozen_importlib_external.PathFinder'>]
觀察一下 Python 默認的這幾種查找器 (finder),可以分為三種:
一種知道如何導入內置模塊
一種知道如何導入凍結模塊
一種知道如何導入來自 import path 的模塊 (即 path based finder )。
那我們能不能自已定義一個查找器呢?當然可以,你只要
定義一個實現了 find_module 方法的類(py2和py3均可),或者實現 find_loader 類方法(僅 py3 有效),如果找到模塊需要返回一個 loader 對象或者 ModuleSpec 對象(后面會講),沒找到需要返回 None
定義完后,要使用這個查找器,必須注冊它,將其插入在 sys.meta_path 的首位,這樣就能優先使用。
import sys
class MyFinder(object):
@classmethod
def find_module(cls, name, path, target=None):
print("Importing", name, path, target)
# 將在后面定義
return MyLoader()
# 由于 finder 是按順序讀取的,所以必須插入在首位
sys.meta_path.insert(0, MyFinder)查找器可以分為兩種:
object +-- Finder (deprecated) +-- MetaPathFinder +-- PathEntryFinder
這里需要注意的是,在 3.4 版前,查找器會直接返回 加載器(Loader)對象,而在 3.4 版后,查找器則會返回模塊規格說明(ModuleSpec),其中 包含加載器。
而關于什么是 加載器 和 模塊規格說明, 請繼續往后看。
4.2 加載器是什么?
查找器只負責查找定位找模,而真正負責加載模塊的,是加載器(loader)。
一般的 loader 必須定義名為 load_module() 的方法。
為什么這里說一般,因為 loader 還分多種:
object +-- Finder (deprecated) | +-- MetaPathFinder | +-- PathEntryFinder +-- Loader +-- ResourceLoader --------+ +-- InspectLoader | +-- ExecutionLoader --+ +-- FileLoader +-- SourceLoader
通過查看源碼可知,不同的加載器的抽象方法各有不同。
加載器通常由一個 finder 返回。詳情參見 PEP 302,對于 abstract base class 可參見 importlib.abc.Loader。
那如何自定義我們自己的加載器呢?
你只要
定義一個實現了 load_module 方法的類
對與導入有關的屬性( 點擊查看詳情 )進行校驗
創建模塊對象并綁定所有與導入相關的屬性變量到該模塊上
將此模塊保存到 sys.modules 中(順序很重要,避免遞歸導入)
然后加載模塊(這是核心)
若加載出錯,需要能夠處理拋出異常( ImportError)
若加載成功,則返回 module 對象
若你想看具體的例子,可以接著往后看。
4.3 模塊規格說明
導入機制在導入期間會使用有關每個模塊的多種信息,特別是加載之前。 大多數信息都是所有模塊通用的。 模塊規格說明的目的是基于每個模塊來封裝這些導入相關信息。
模塊的規格說明會作為模塊對象的 __spec__ 屬性對外公開。 有關模塊規格的詳細內容請參閱 ModuleSpec 。
在 Python 3.4 后,查找器不再返回加載器,而是返回 ModuleSpec 對象,它儲存著更多的信息
模塊名
加載器
模塊絕對路徑
那如何查看一個模塊的 ModuleSpec ?
這邊舉個例子
$ cat my_mod02.py import my_mod01 print(my_mod01.__spec__) $ python3 my_mod02.py in mod01 ModuleSpec(name='my_mod01', loader=<_frozen_importlib_external.SourceFileLoader object at 0x000000000392DBE0>, origin='/home/MING/my_mod01.py')
從 ModuleSpec 中可以看到,加載器是包含在內的,那我們如果要重新加載一個模塊,是不是又有了另一種思路了?
來一起驗證一下。
現在有兩個文件:
一個是 my_info.py
# my_info.py name='wangbm'
另一個是:main.py
# main.py import my_info print(my_info.name) # 加一個斷點 import pdb;pdb.set_trace() # 再加載一次 my_info.__spec__.loader.load_module() print(my_info.name)
在 main.py 處,我加了一個斷點,目的是當運行到斷點處時,我修改 my_info.py 里的 name 為 ming ,以便驗證重載是否有效?
$ python3 main.py wangbm > /home/MING/main.py(9)<module>() -> my_info.__spec__.loader.load_module() (Pdb) c ming
從結果來看,重載是有效的。
4.4 導入器是什么?
導入器(importer),也許你在其他文章里會見到它,但其實它并不是個新鮮的東西。
它只是同時實現了查找器和加載器兩種接口的對象,所以你可以說導入器(importer)是查找器(finder),也可以說它是加載器(loader)。
由于 Python 默認的 查找器和加載器 僅支持本地的模塊的導入,并不支持實現遠程模塊的導入。
為了讓你更好的理解 Python Import Hook 機制,我下面會通過實例演示,如何自己實現遠程導入模塊的導入器。
5.1 動手實現導入器
當導入一個包的時候,Python 解釋器首先會從 sys.meta_path 中拿到查找器列表。
默認順序是:內建模塊查找器 -> 凍結模塊查找器 -> 第三方模塊路徑(本地的 sys.path)查找器
若經過這三個查找器,仍然無法查找到所需的模塊,則會拋出ImportError異常。
因此要實現遠程導入模塊,有兩種思路。
一種是實現自己的元路徑導入器;
另一種是編寫一個鉤子,添加到sys.path_hooks里,識別特定的目錄命名模式。
我這里選擇第一種方法來做為示例。
實現導入器,我們需要分別查找器和加載器。
首先是查找器
由源碼得知,路徑查找器分為兩種
MetaPathFinder
PathEntryFinder
這里使用 MetaPathFinder 來進行查找器的編寫。
在 Python 3.4 版本之前,查找器必須實現 find_module() 方法,而 Python 3.4+ 版,則推薦使用 find_spec() 方法,但這并不意味著你不能使用 find_module() ,但是在沒有 find_spec() 方法時,導入協議還是會嘗試 find_module() 方法。
我先舉例下使用 find_module() 該如何寫。
from importlib import abc class UrlMetaFinder(abc.MetaPathFinder): def __init__(self, baseurl): self._baseurl = baseurl def find_module(self, fullname, path=None): if path is None: baseurl = self._baseurl else: # 不是原定義的url就直接返回不存在 if not path.startswith(self._baseurl): return None baseurl = path try: loader = UrlMetaLoader(baseurl) loader.load_module(fullname) return loader except Exception: return None
若使用 find_spec() ,要注意此方法的調用需要帶有兩到三個參數。
第一個是被導入模塊的完整限定名稱,例如 foo.bar.baz 。 第二個參數是供模塊搜索使用的路徑條目。 對于最高層級模塊,第二個參數為 None ,但對于子模塊或子包,第二個參數為父包 __path__ 屬性的值。 如果相應的 __path__ 屬性無法訪問,將引發 ModuleNotFoundError 。 第三個參數是一個將被作為稍后加載目標的現有模塊對象。 導入系統僅會在重加載期間傳入一個目標模塊。
from importlib import abc from importlib.machinery import ModuleSpec class UrlMetaFinder(abc.MetaPathFinder): def __init__(self, baseurl): self._baseurl = baseurl def find_spec(self, fullname, path=None, target=None): if path is None: baseurl = self._baseurl else: # 不是原定義的url就直接返回不存在 if not path.startswith(self._baseurl): return None baseurl = path try: loader = UrlMetaLoader(baseurl) return ModuleSpec(fullname, loader, is_package=loader.is_package(fullname)) except Exception: return None
接下來是加載器
由源碼得知,路徑查找器分為三種
FileLoader
SourceLoader
按理說,兩種加載器都可以實現我們想要的功能,我這里選用 SourceLoader 來示范。
在 SourceLoader 這個抽象類里,有幾個很重要的方法,在你寫實現加載器的時候需要注意
module.__dict__
在一些老的博客文章中,你會經常看到 加載器 要實現 load_module() ,而這個方法早已在 Python 3.4 的時候就被廢棄了,當然為了兼容考慮,你若使用 load_module() 也是可以的。
from importlib import abc class UrlMetaLoader(abc.SourceLoader): def __init__(self, baseurl): self.baseurl = baseurl def get_code(self, fullname): f = urllib2.urlopen(self.get_filename(fullname)) return f.read() def load_module(self, fullname): code = self.get_code(fullname) mod = sys.modules.setdefault(fullname, imp.new_module(fullname)) mod.__file__ = self.get_filename(fullname) mod.__loader__ = self mod.__package__ = fullname exec(code, mod.__dict__) return None def get_data(self): pass def execute_module(self, module): pass def get_filename(self, fullname): return self.baseurl + fullname + '.py'
當你使用這種舊模式實現自己的加載時,你需要注意兩點,很重要:
execute_module 必須重載,而且不應該有任何邏輯,即使它并不是抽象方法。
load_module,需要你在查找器里手動執行,才能實現模塊的加載。。
做為替換,你應該使用 execute_module() 和 create_module() 。由于基類里已經實現了 execute_module 和 create_module() ,并且滿足我們的使用場景。我這邊可以不用重復實現。和舊模式相比,這里也不需要在設查找器里手動執行 execute_module() 。
import urllib.request as urllib2 class UrlMetaLoader(importlib.abc.SourceLoader): def __init__(self, baseurl): self.baseurl = baseurl def get_code(self, fullname): f = urllib2.urlopen(self.get_filename(fullname)) return f.read() def get_data(self): pass def get_filename(self, fullname): return self.baseurl + fullname + '.py'
查找器和加載器都有了,別忘了往sys.meta_path 注冊我們自定義的查找器(UrlMetaFinder)。
def install_meta(address): finder = UrlMetaFinder(address) sys.meta_path.append(finder)
所有的代碼都解析完畢后,我們將其整理在一個模塊(my_importer.py)中
# my_importer.py import sys import importlib import urllib.request as urllib2 class UrlMetaFinder(importlib.abc.MetaPathFinder): def __init__(self, baseurl): self._baseurl = baseurl def find_module(self, fullname, path=None): if path is None: baseurl = self._baseurl else: # 不是原定義的url就直接返回不存在 if not path.startswith(self._baseurl): return None baseurl = path try: loader = UrlMetaLoader(baseurl) return loader except Exception: return None class UrlMetaLoader(importlib.abc.SourceLoader): def __init__(self, baseurl): self.baseurl = baseurl def get_code(self, fullname): f = urllib2.urlopen(self.get_filename(fullname)) return f.read() def get_data(self): pass def get_filename(self, fullname): return self.baseurl + fullname + '.py' def install_meta(address): finder = UrlMetaFinder(address) sys.meta_path.append(finder)
5.2 搭建遠程服務端
最開始我說了,要實現一個遠程導入模塊的方法。
我還缺一個在遠端的服務器,來存放我的模塊,為了方便,我使用python自帶的 http.server 模塊用一條命令即可實現。
$ mkdir httpserver && cd httpserver
$ cat>my_info.py<EOF
name='wangbm'
print('ok')
EOF
$ cat my_info.py
name='wangbm'
print('ok')
$
$ python3 -m http.server 12800
Serving HTTP on 0.0.0.0 port 12800 (http://0.0.0.0:12800/) ...
...一切準備好,我們就可以驗證了。
>>> from my_importer import install_meta
>>> install_meta('http://localhost:12800/') # 往 sys.meta_path 注冊 finder
>>> import my_info # 打印ok,說明導入成功
ok
>>> my_info.name # 驗證可以取得到變量
'wangbm'關于如何在Python中使用 import 機制遠程導入模塊就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





