溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
首先:文章用到的解析庫介紹
BeautifulSoup:
Beautiful Soup提供一些簡單的、python式的函數用來處理導航、搜索、修改分析樹等功能。
它是一個工具箱,通過解析文檔為用戶提供需要抓取的數據,因為簡單,所以不需要多少代碼就可以寫出一個完整的應用程序。
Beautiful Soup自動將輸入文檔轉換為Unicode編碼,輸出文檔轉換為utf-8編碼。
你不需要考慮編碼方式,除非文檔沒有指定一個編碼方式,這時,Beautiful Soup就不能自動識別編碼方式了。然后,你僅僅需要說明一下原始編碼方式就可以了。
Beautiful Soup已成為和lxml、html6lib一樣出色的python解釋器,為用戶靈活地提供不同的解析策略或強勁的速度。
爬取小說原因背景:
以前很喜歡看起點網上面的小說,但是很多都要錢,窮學生沒多少錢,就發現了筆趣網。
筆趣看是一個小說網站,這里有很多起點中文網的免費小說,而且這個網站只能在線瀏覽,不支持小說打包下載。
所以本次爬取呢,就是從該網站爬取并保存一個名為《一念永恒》的小說。
另外本次爬取只是做例子演示,請支持正版資源!!!!!!!!!!!
那么簡單的爬取開始:
①打開url鏈接,按F12或者右鍵- 檢查 進入開發者工具
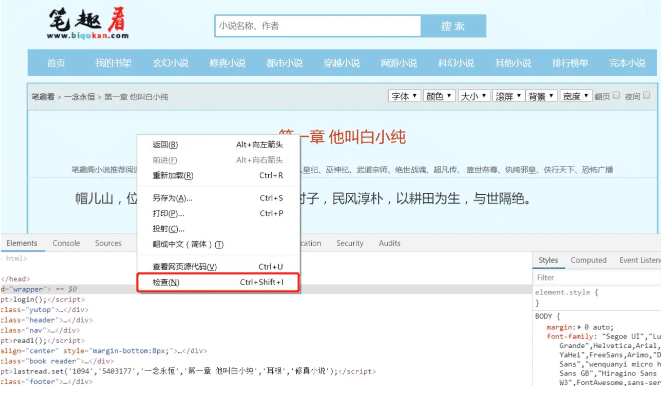
② 在開發者工具中,捕獲我們要找到的請求條目信息
選擇主文章的一部分內容,選擇復制粘貼那一部分,
然后再打開開發者工具欄:
“network—選擇放大鏡圖標sreach—然后再搜索欄粘貼我們要搜索的內容”
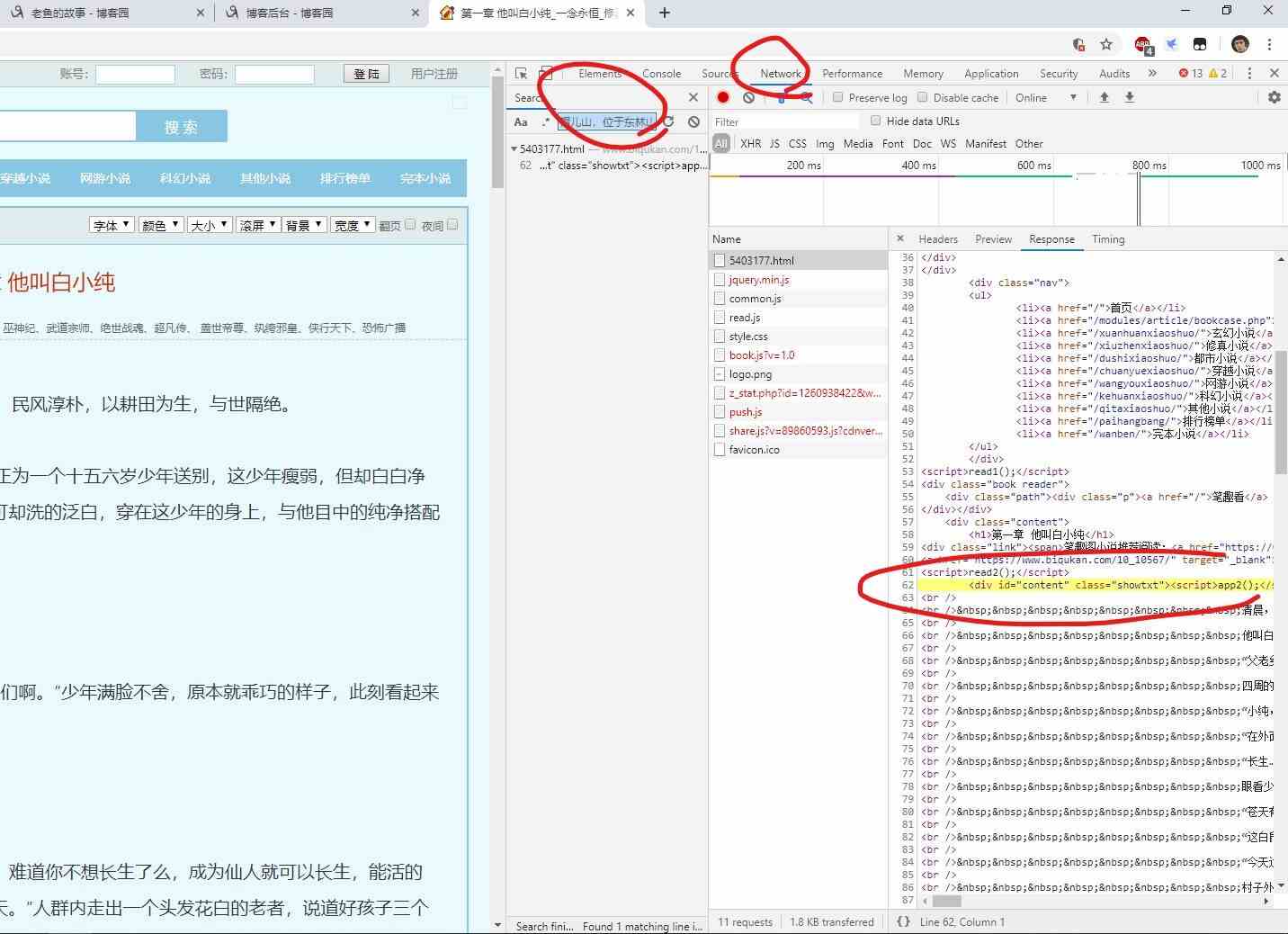
然后會在下方得到條目信息,點擊,頁面會跳轉到加載正文的請求響應條目中。
我們可以看到:
正文部分是處于 id 為 content 和 class 為 showtxt 的 div 中。
③ 構造url請求
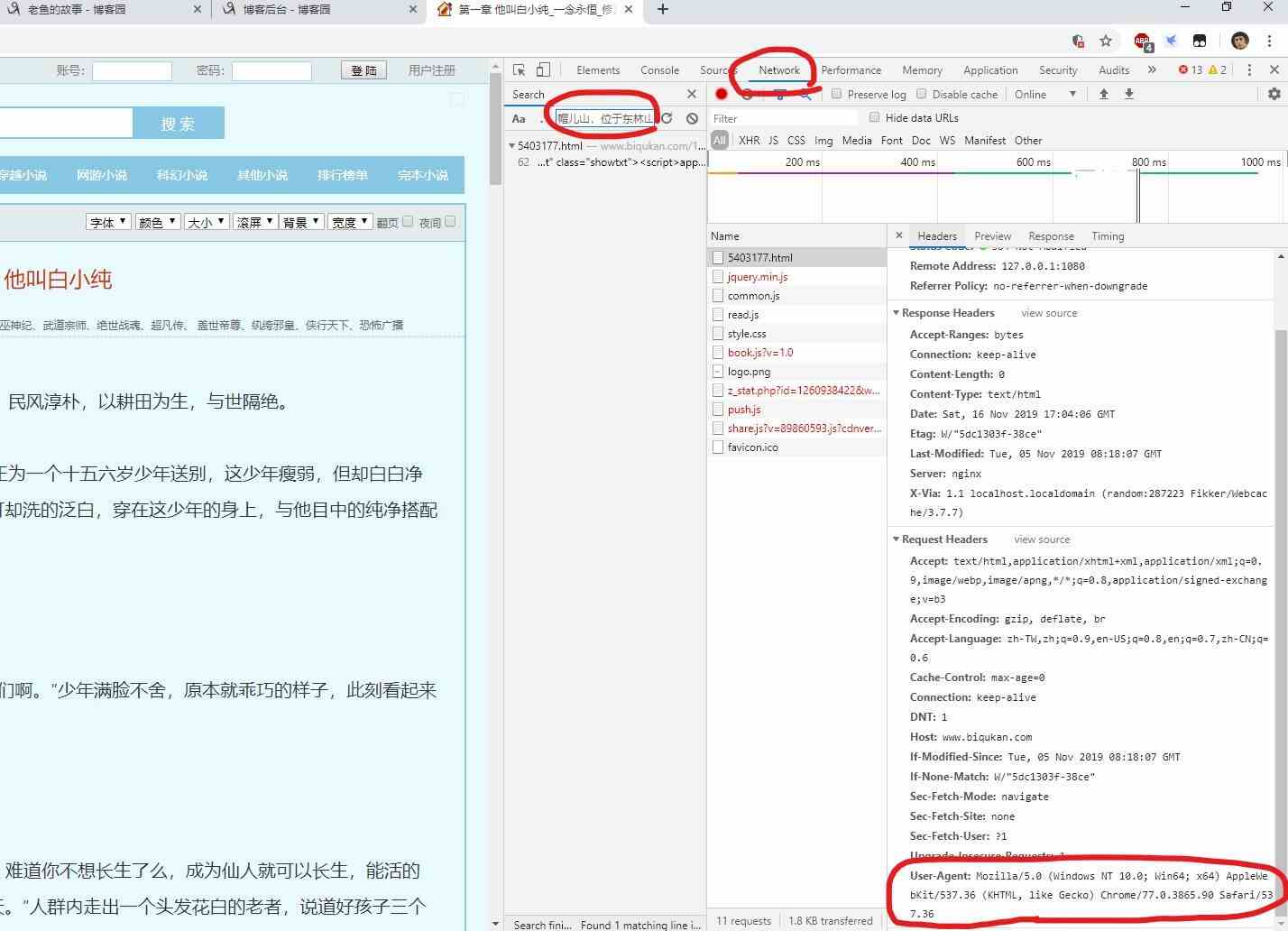
上面的信息是不夠的,因為現在的網站都有了反爬能力,我們所需要是模擬一條正常從瀏覽器中發出的url請求鏈接。
這里我們會用到: User-Agent(瀏覽器標識)
還是開發者工具,點擊Headers,就可以看到Request-Response條目明細。
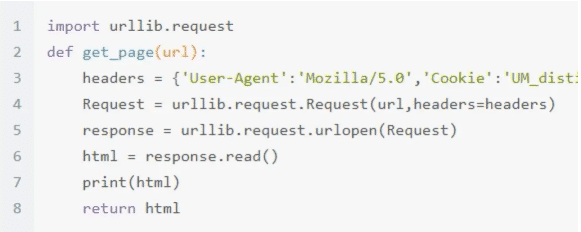
④ 發出請求:
有了字段的詳細內容,我們就可以編寫出請求網頁的代碼
⑤ 獲得相應內容,然后運行,得到內容如下:
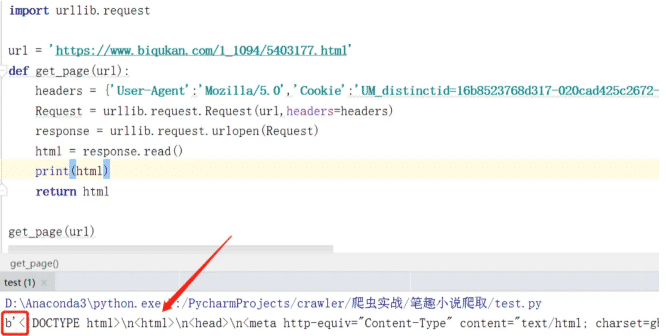
解析響應數據
下面,我們使用BeautifulSoup進行解析 運行….代碼結果如圖:
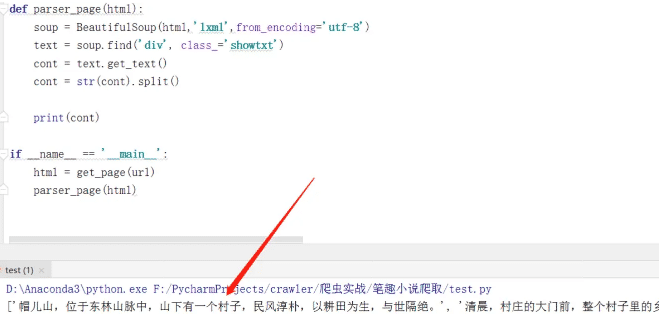
到這里,小說就爬取完成了。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





