溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Python爬蟲爬取煎蛋網圖片代碼實例,文中通過示例代碼介紹的非常詳細,對大家的學習或者工作具有一定的參考學習價值,需要的朋友可以參考下
今天,試著爬取了煎蛋網的圖片。
用到的包:
分別使用幾個函數,來控制下載的圖片的頁數,獲取圖片的網頁,獲取網頁頁數以及保存圖片到本地。過程簡單清晰明了
直接上源代碼:
import urllib.request
import os
def url_open(url):
req = urllib.request.Request(url)
req.add_header('user-agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36')
response = urllib.request.urlopen(url)
html = response.read()
return html
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page')+23
b = html.find(']',a)
return html[a:b]
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while a != -1:
b = html.find('.jpg',a ,a+255)
if b != -1:
img_addrs.append('https:'+html[a+9:b+4]) # 'img src='為9個偏移 '.jpg'為4個偏移
else:
b = a+9
a = html.find('img src=', b)
return img_addrs
def save_imgs(folder, img_addrs):
for each in img_addrs:
filename = each.split('/')[-1]
with open(filename, 'wb') as f:
img = url_open(each)
f.write(img)
print(img_addrs)
def download_mm(folder = 'xxoo', pages = 5):
os.mkdir(folder)
os.chdir(folder)
url = 'http://jandan.net/ooxx/'
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = url + 'page-'+ str(page_num) + '#comments'
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs)
if __name__ == '__main__':
download_mm()
其中在主函數download_mm()中,將pages設置在了5面。
本來設置的是10,但是在程序執行的過程中。出現了404ERROR錯誤
即imgae_url出現了錯誤。嘗試著在save_img()函數中加入了測試代碼:print(img_addrs),
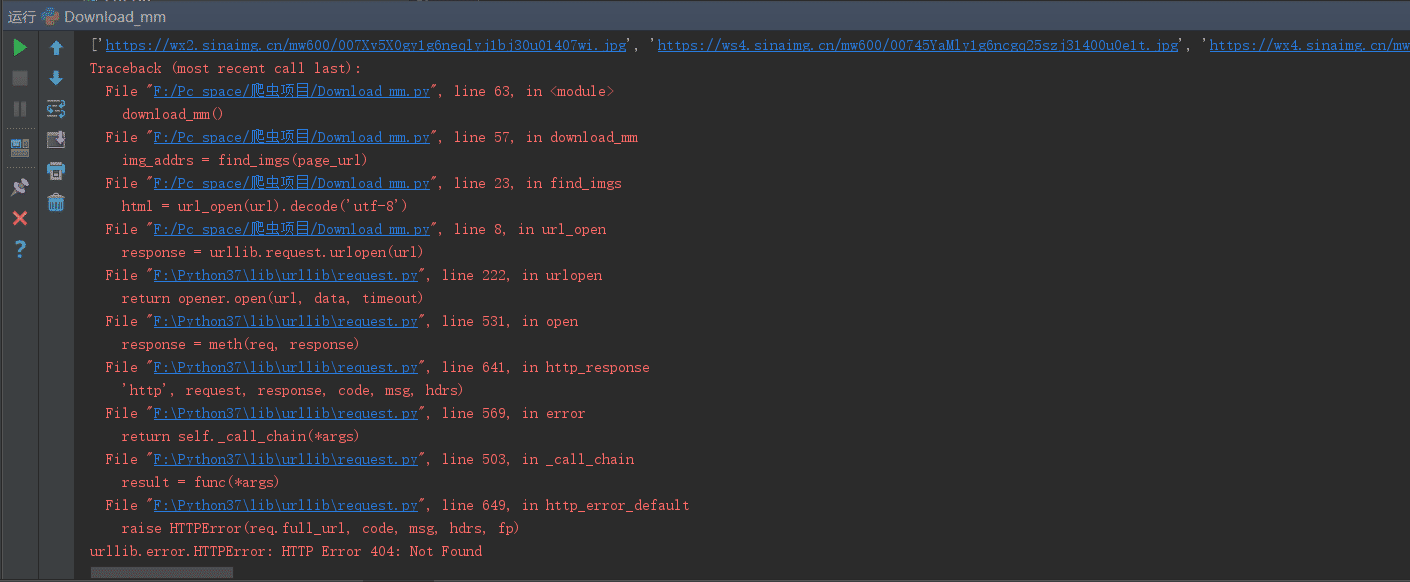
想到會不會是因為后面頁數的圖片,img_url的格式出現了改變,導致404,所以將pages改成5,
再次運行,結果沒有問題,圖片能正常下載:
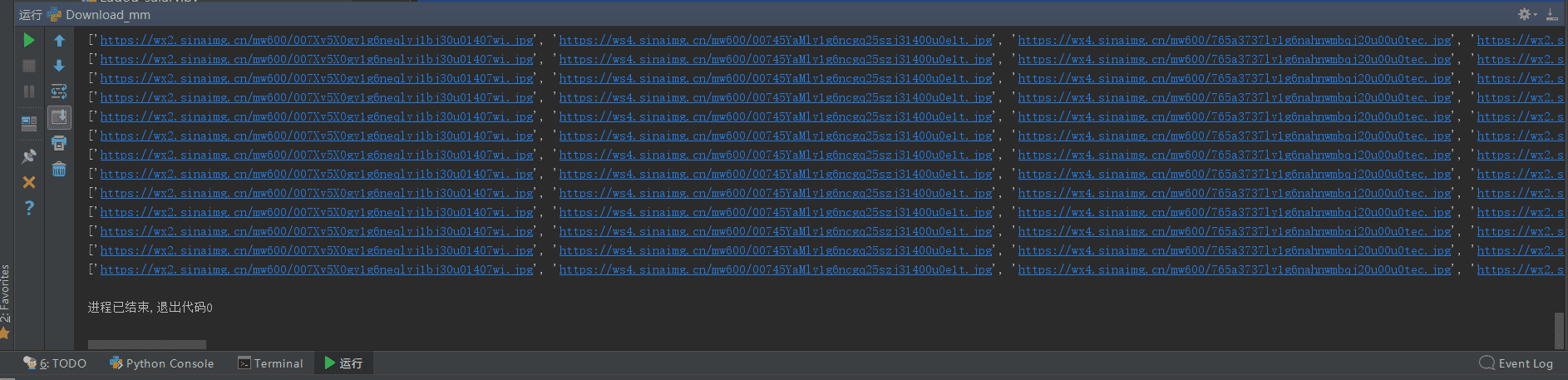
仔細觀察發現,剛好是在第五面的圖片往后,出現了不可下載的問題(404)。所以在煎蛋網上,我們直接跳到第6面查看圖片的url。

上圖是后5面的圖片url,下圖是前5面的圖片url

而源代碼中,尋找的圖片url為使用find()函數,進行定為<img src=‘'> <.jpg>中的圖片url,所以后5面出現的a href無法匹配,即出現了404 ERROR。如果想要下載后續的圖片,需要重新添加一個url定位
即在find中將 img src改成 a href,偏移量也需要更改。
總結:
使用find()來定位網頁標簽確實太過low,所以以后在爬蟲中要盡量使用正則表達式和Beautifulsoup包來提高效率,而這兩項我還不是特別熟,所以需要更多的訓練。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





