溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹Loss function函數如何在Pytorch中使用,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
1.損失函數
損失函數,又叫目標函數,是編譯一個神經網絡模型必須的兩個要素之一。另一個必不可少的要素是優化器。
損失函數是指用于計算標簽值和預測值之間差異的函數,在機器學習過程中,有多種損失函數可供選擇,典型的有距離向量,絕對值向量等。
損失Loss必須是標量,因為向量無法比較大小(向量本身需要通過范數等標量來比較)。
損失函數一般分為4種,平方損失函數,對數損失函數,HingeLoss 0-1 損失函數,絕對值損失函數。
我們先定義兩個二維數組,然后用不同的損失函數計算其損失值。
import torch from torch.autograd import Variable import torch.nn as nn import torch.nn.functional as F sample = Variable(torch.ones(2,2)) a=torch.Tensor(2,2) a[0,0]=0 a[0,1]=1 a[1,0]=2 a[1,1]=3 target = Variable (a)
sample 的值為:[[1,1],[1,1]]。
target 的值為:[[0,1],[2,3]]。
1 nn.L1Loss
L1Loss 計算方法很簡單,取預測值和真實值的絕對誤差的平均數即可。
criterion = nn.L1Loss() loss = criterion(sample, target) print(loss)
最后結果是:1。
它的計算邏輯是這樣的:
先計算絕對差總和:|0-1|+|1-1|+|2-1|+|3-1|=4;
然后再平均:4/4=1。
2 nn.SmoothL1Loss
SmoothL1Loss 也叫作 Huber Loss,誤差在 (-1,1) 上是平方損失,其他情況是 L1 損失。
criterion = nn.SmoothL1Loss() loss = criterion(sample, target) print(loss)
最后結果是:0.625。
3 nn.MSELoss
平方損失函數。其計算公式是預測值和真實值之間的平方和的平均數。

criterion = nn.MSELoss() loss = criterion(sample, target) print(loss)
最后結果是:1.5。
4 nn.CrossEntropyLoss
交叉熵損失函數
花了點時間才能看懂它。
首先,先看幾個例子,
需要注意的是,target輸入必須是 tensor long 類型(int64位)
import torch # cross entropy loss pred = np.array([[0.8, 2.0, 1.2]]) CELoss = torch.nn.CrossEntropyLoss() for k in range(3): target = np.array([k]) loss2 = CELoss(torch.from_numpy(pred), torch.from_numpy(target).long()) print(loss2)
Output:
tensor(1.7599, dtype=torch.float64) tensor(0.5599, dtype=torch.float64) tensor(1.3599, dtype=torch.float64)
如果,改成pred = np.array([[0.8, 2.0, 2.0]]),輸出,
tensor(2.0334, dtype=torch.float64) tensor(0.8334, dtype=torch.float64) tensor(0.8334, dtype=torch.float64)
后面兩個輸出一樣。
先看它的公式,就明白怎么回事了:

(這個應該是有兩個標準交叉熵組成了,后面一個算是預測錯誤的交叉熵?反正,數值會變大了)
使用 numpy來實現是這樣的:
pred = np.array([[0.8, 2.0, 2.0]]) nClass = pred.shape[1] target = np.array([0]) def labelEncoder(y): tmp = np.zeros(shape = (y.shape[0], nClass)) for i in range(y.shape[0]): tmp[i][y[i]] = 1 return tmp def crossEntropy(pred, target): target = labelEncoder(target) pred = softmax(pred) H = -np.sum(target*np.log(pred)) return H H = crossEntropy(pred, target)
輸出:
2.0334282107562287
對上了!
再回頭看看,公式
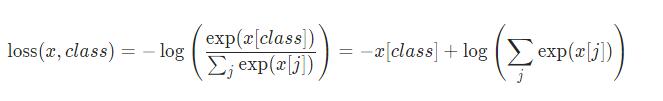
這里,就是class 就是索引,(調用 nn.CrossEntropyLoss需要注意),這里把Softmax求p 和 ylog(p)寫在一起,一開始還沒反應過來。
5.nn.BCELoss
二分類交叉熵的含義其實在交叉熵上面提過,就是把{y, 1-y}當做兩項分布,計算出來的loss就比交叉熵大(也就是包含的信息更多了,因為包含了正類和負類的loss了)。
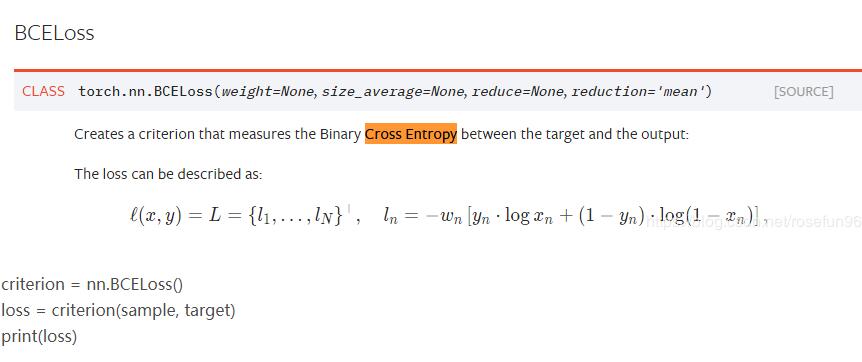
最后結果是:-13.8155。
6 nn.NLLLoss
負對數似然損失函數(Negative Log Likelihood)
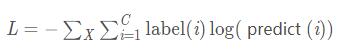
在前面接上一個 LogSoftMax 層就等價于交叉熵損失了。注意這里的 xlabel 和上個交叉熵損失里的不一樣,這里是經過 log 運算后的數值。這個損失函數一般也是用在圖像識別模型上。
NLLLoss 的 輸入 是一個對數概率向量和一個目標標簽(不需要是one-hot編碼形式的). 它不會為我們計算對數概率. 適合網絡的最后一層是log_softmax. 損失函數 nn.CrossEntropyLoss() 與 NLLLoss() 相同, 唯一的不同是它為我們去做 softmax.
Nn.NLLLoss 和 nn.CrossEntropyLoss 的功能是非常相似的!通常都是用在多分類模型中,實際應用中我們一般用 NLLLoss 比較多。
7 nn.NLLLoss2d
和上面類似,但是多了幾個維度,一般用在圖片上。
input, (N, C, H, W)
target, (N, H, W)
比如用全卷積網絡做分類時,最后圖片的每個點都會預測一個類別標簽。
criterion = nn.NLLLoss2d() loss = criterion(sample, target) print(loss)
最后結果是:報錯,看來不能直接這么用!
8 .BCEWithLogitsLoss 與 MultilabelSoftMarginLoss
BCEWithLogitsLoss :
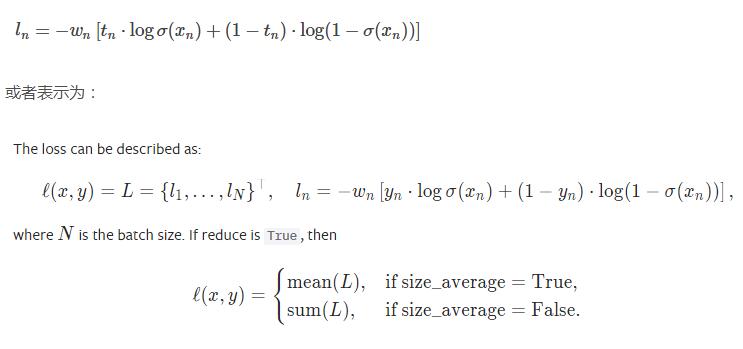
這里,主要x,y的順序,x為predict的輸出(還沒有sigmoid);y為真實標簽,一般是[0,1],但是真實標簽也可以是概率表示,如[0.1, 0.9].
可以看出,這里與 BCELoss相比,它幫你做sigmoid 操作,不需要你輸出時加激活函數。
MultiLabelSoftMarginLoss :

可以看出, 后者是前者權值為1時的特例。
import torch
from torch.autograd import Variable
from torch import nn
x = Variable(torch.randn(10, 3))
y = Variable(torch.FloatTensor(10, 3).random_(2))
# double the loss for class 1
class_weight = torch.FloatTensor([1.0, 2.0, 1.0])
# double the loss for last sample
element_weight = torch.FloatTensor([1.0]*9 + [2.0]).view(-1, 1)
element_weight = element_weight.repeat(1, 3)
bce_criterion = nn.BCEWithLogitsLoss(weight=None, reduce=False)
multi_criterion = nn.MultiLabelSoftMarginLoss(weight=None, reduce=False)
bce_criterion_class = nn.BCEWithLogitsLoss(weight=class_weight, reduce=False)
multi_criterion_class = nn.MultiLabelSoftMarginLoss(weight=class_weight,
reduce=False)
bce_criterion_element = nn.BCEWithLogitsLoss(weight=element_weight, reduce=False)
multi_criterion_element = nn.MultiLabelSoftMarginLoss(weight=element_weight,
reduce=False)
bce_loss = bce_criterion(x, y)
multi_loss = multi_criterion(x, y)
bce_loss_class = bce_criterion_class(x, y)
multi_loss_class = multi_criterion_class(x, y)
print(bce_loss_class)
print(multi_loss_class)
print('bce_loss',bce_loss)
print('bce loss mean', torch.mean(bce_loss, dim = 1))
print('multi_loss', multi_loss)9.比較BCEWithLogitsLoss和TensorFlow的 sigmoid_cross_entropy_with_logits;softmax_cross_entropy_with_logits
pytorch BCEwithLogitsLoss 參考前面8的介紹。
from torch import nn from torch.autograd import Variable bce_criterion = nn.BCEWithLogitsLoss(weight = None, reduce = False) y = Variable(torch.tensor([[1,0,0],[0,1,0],[0,0,1],[1,1,0],[0,1,0]],dtype=torch.float64)) logits = Variable(torch.tensor([[12,3,2],[3,10,1],[1,2,5],[4,6.5,1.2],[3,6,1]],dtype=torch.float64)) bce_criterion(logits, y)
result:
tensor([[6.1442e-06, 3.0486e+00, 2.1269e+00], [3.0486e+00, 4.5399e-05, 1.3133e+00], [1.3133e+00, 2.1269e+00, 6.7153e-03], [1.8150e-02, 1.5023e-03, 1.4633e+00], [3.0486e+00, 2.4757e-03, 1.3133e+00]], dtype=torch.float64)
如果使用 TensorFlow的sigmoid_cross_entropy_with_logits,
y = np.array([[1,0,0],[0,1,0],[0,0,1],[1,1,0],[0,1,0]]) logits = np.array([[12,3,2],[3,10,1],[1,2,5],[4,6.5,1.2],[3,6,1]]).astype(np.float32) sess =tf.Session() y = np.array(y).astype(np.float32) # labels是float64的數據類型 E2 = sess.run(tf.nn.sigmoid_cross_entropy_with_logits(labels=y,logits=logits)) print(E2)
result
[[6.1441933e-06 3.0485873e+00 2.1269281e+00] [3.0485873e+00 4.5398901e-05 1.3132617e+00] [1.3132617e+00 2.1269281e+00 6.7153485e-03] [1.8149929e-02 1.5023102e-03 1.4632825e+00] [3.0485873e+00 2.4756852e-03 1.3132617e+00]]
從結果來看,兩個是等價的。
其實,兩個損失函數都是,先預測結果sigmoid,再求交叉熵。
Keras binary_crossentropy 也是調用 Tf sigmoid_cross_entropy_with_logits.
keras binary_crossentropy 源碼;
def loss_fn(y_true, y_pred, e=0.1): bce_loss = K.binary_crossentropy(y_true, y_pred) return K.mean(bce_loss, axis = -1) y = K.variable([[1,0,0],[0,1,0],[0,0,1],[1,1,0],[0,1,0]]) logits = K.variable([[12,3,2],[3,10,1],[1,2,5],[4,6.5,1.2],[3,6,1]]) res = loss_fn(logits, y) print(K.get_value(res)) from keras.losses import binary_crossentropy print(K.get_value(binary_crossentropy(logits, y)))
result:
[-31.59192 -26.336359 -5.1384177 -38.72286 -5.0798492] [-31.59192 -26.336359 -5.1384177 -38.72286 -5.0798492]
同樣,如果是softmax_cross_entropy_with_logits的話,
y = np.array([[1,0,0],[0,1,0],[0,0,1],[1,1,0],[0,1,0]]) logits = np.array([[12,3,2],[3,10,1],[1,2,5],[4,6.5,1.2],[3,6,1]]).astype(np.float32) sess =tf.Session() y = np.array(y).astype(np.float32) # labels是float64的數據類型 E2 = sess.run(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=logits)) print(E2)
result:
[1.6878611e-04 1.0346780e-03 6.5883912e-02 2.6669841e+00 5.4985214e-02]
發現維度都已經變了,這個是 N*1維了。
即使,把上面sigmoid_cross_entropy_with_logits的結果維度改變,也是 [1.725174 1.4539648 1.1489683 0.49431157 1.4547749 ],兩者還是不一樣。
關于選用softmax_cross_entropy_with_logits還是sigmoid_cross_entropy_with_logits,使用softmax,精度會更好,數值穩定性更好,同時,會依賴超參數。
2 其他不常用loss
| 函數 | 作用 |
|---|---|
| AdaptiveLogSoftmaxWithLoss | 用于不平衡類 |
關于Loss function函數如何在Pytorch中使用就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





