溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一朋友在群里問有沒有什么辦法能夠一次性把這個鏈接 里的文章保存下來。點開可以看到,其實就是一個文章合集。所以需求就是,把這個文檔中的鏈接里的文章挨個保存下來。保存形式可以有很多種,可以是圖片,也可以是網頁。這里因為使用 puppeteer 庫的原因,故選擇保存格式格式為PDF。
需求解構
完成整個動作,主要分為這兩個部分。獲取文檔內所有文章的鏈接;把每個鏈接里的內容保存為PDF文件。
對于獲取鏈接,有兩條路,一是使用request模塊請求該網址獲取文檔;二是把網頁保存到本地使用fs模塊獲取文檔內容。拿到文檔也就是整個HTML文檔后,一開始沒想到什么好法子來拿到全部文章鏈接。如果直接在網頁那就好辦,直接DOM的 quertSelectorAll API配合CSS選擇器就可以非常方便地拿到所有 a 鏈接中的 href 屬性。但這里是Node,是DOM外之地。又想到的是直接使用正則匹配,后來還是放棄了這個做法。在google搜了下才發現竟然忘了 cheerio 這個好東西。 cheerio 是一個專門為服務端設計的快速靈活而簡潔得jQuery實現。
對于保存網頁內容,我所知道的常規操作是保存為PDF文件,恰巧之前剛知道的 puppeteer 滿足這樣的需求。 puppeteer 是一個由 chrome devtools 團隊維護的提供了控制chrome瀏覽器高級API的一個Node庫。除去爬取網頁內容保存為PDF文件外,它還可以作為服務端渲染的一個方案以及實現自動化測試的一個方案。
需求實現
獲取鏈接
先上這部分代碼
const getHref = function () {
let file = fs.readFileSync('./index.html').toString()
const $ = cheerio.load(file)
let hrefs = $('#sam').find('a')
for (e in hrefs) {
if (hrefs[e].attribs && hrefs[e].attribs['href']) {
hrefArr.push({
index: e,
href: hrefs[e].attribs['href']
})
}
}
fs.writeFileSync('hrefJson.json', JSON.stringify(hrefArr))
}
因為后面的代碼都依賴到讀取的文件,所以這里用的是readFileSync方法。如果沒有聲明返回內容的格式,那默認是Buffer格式。可以選擇填寫 utf8 格式,或者直接在該方法后面使用 toString 方法。
兩行代碼用cheerio拿到所有所有鏈接的DOM元素后,挨個將其處理為方便后面要用到的格式。考慮到可能存在a標簽沒有href屬性的情況,這里還對其進行了判斷,不過這也是后面調試程序時才發現的bug。
如果需要將所有的鏈接另外保存起來,使用 writeFile 方法。
存為PDF
同樣,先上這部分代碼。
const saveToPdf = function () {
async () => {
const browser = await puppeteer.launch({
executablePath: './chrome-win/chrome.exe',
});
// 鏈接計數
let i = 0
async function getPage() {
const page = await browser.newPage();
await page.goto(hrefArr[i]['href'], { waitUntil: 'domcontentloaded' });
// 網頁標題
let pageTitle
if (hrefArr[i]['href'].includes('weixin')) {
pageTitle = await page.$eval('meta[property="og:title"]', el => el.content)
} else {
pageTitle = await page.$eval('title', el => el.innerHTML)
}
let title = pageTitle.trim()
// 去掉斜桿
let titlea = title.replace(/\s*/g, "")
// 去掉豎線
let titleb = titlea.replace(/\|/g, "");
await page.pdf({ path: `${i}${titleb}.pdf` });
i++
if (i < hrefArr.length) {
getPage()
} else {
await browser.close();
}
}
getPage()
}
}
因為需要等待chrome瀏覽器的打開,以及其他可能的異步請求。最外層使用了async 配合箭頭函數將真正的執行代碼包住。
在用 npm 安裝 puppetter 時,因為默認會下載chrome瀏覽器,而服務器在國外,一般都無法下載成功。當然也有相應的解決方案,這里我就不展開了。如果安裝 puppeteer ,可以參開 這篇文章 或者直接谷歌搜下。
在前一部分說到,我們需要把不止一個鏈接里的內容保存為PDF,所以使用了變量 i 來標識每一次需要訪問的鏈接。
對于獲取網頁標題,當時確實費了點時間才處理好拿到已有鏈接的網頁標題。所以鏈接中主要有兩種網站的鏈接,一類是微信公眾號文章,另一類是新浪財新這種網站。微信文章里頭沒有像新浪這樣直接給出 title 內容。

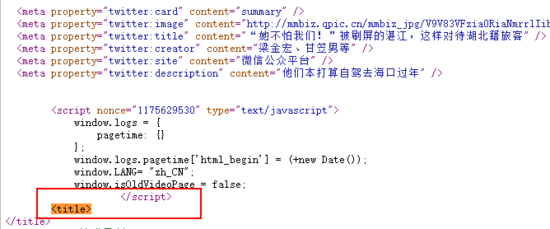
這個時候就要用到 page 類中的 $eval 方法, $eval 方法主要有兩個參數,一是選擇器,二是在瀏覽器上下文中執行的函數。$eval方法會頁面中運行document.querySelector方法,并將其返回值傳遞給第二個參數,也就是我們寫好的方法中。以獲取新浪網頁文章title為例, title 為傳入選擇器,我們需要的是其標簽內容。
pageTitle = await page.$eval('title', el => el.innerHTML)
在產生文件名的過程中,由于文件夾還是文件路徑的一部分。此時還需要考慮到windows文件路徑規范。但網頁中的標題并不受此規范限制,由此產生矛盾。這個問題也是后面調試的時候才發現,一開始寫代碼并沒有想到這個問題。即需要去除標題中的斜杠豎桿還有空格等字符。
每獲取完一個鏈接的內容后,就將鏈接位置標識 i + 1,知道所有鏈接內容保存完畢,關閉打開的網頁。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





