溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“Python中pandas統計分析的案例”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Python中pandas統計分析的案例”這篇文章吧。
pandas模塊為我們提供了非常多的描述性統計分析的指標函數,如總和、均值、最小值、最大值等,我們來具體看看這些函數:
1、隨機生成三組數據
import numpy as np import pandas as pd np.random.seed(1234) d1 = pd.Series(2*np.random.normal(size = 100)+3) d2 = np.random.f(2,4,size = 100) d3 = np.random.randint(1,100,size = 100)
2、統計分析用到的函數
d1.count() #非空元素計算 d1.min() #最小值 d1.max() #最大值 d1.idxmin() #最小值的位置,類似于R中的which.min函數 d1.idxmax() #最大值的位置,類似于R中的which.max函數 d1.quantile(0.1) #10%分位數 d1.sum() #求和 d1.mean() #均值 d1.median() #中位數 d1.mode() #眾數 d1.var() #方差 d1.std() #標準差 d1.mad() #平均絕對偏差 d1.skew() #偏度 d1.kurt() #峰度 d1.describe() #一次性輸出多個描述性統計指標
必須注意的是,descirbe方法只能針對序列或數據框,一維數組是沒有這個方法的
自定義一個函數,將這些統計指標匯總在一起:
def status(x) : return pd.Series([x.count(),x.min(),x.idxmin(),x.quantile(.25),x.median(), x.quantile(.75),x.mean(),x.max(),x.idxmax(),x.mad(),x.var(), x.std(),x.skew(),x.kurt()],index=['總數','最小值','最小值位置','25%分位數', '中位數','75%分位數','均值','最大值','最大值位數','平均絕對偏差','方差','標準差','偏度','峰度'])
執行該函數,查看一下d1數據集的這些統計函數值:
df = pd.DataFrame(status(d1))
df
結果:
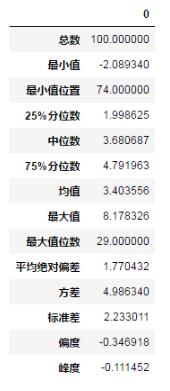
在實際的工作中,我們可能需要處理的是一系列的數值型數據框,如何將這個函數應用到數據框中的每一列呢?可以使用apply函數,這個非常類似于R中的apply的應用方法。
將之前創建的d1,d2,d3數據構建數據框:
df = pd.DataFrame(np.array([d1,d2,d3]).T, columns=['x1','x2','x3']) df.head() df.apply(status)
結果:
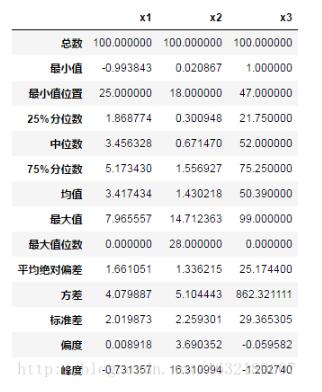
3、加載CSV數據
import numpy as np
import pandas as pd
bank = pd.read_csv("D://bank/bank-additional-train.csv")
bank.head() #查看前5行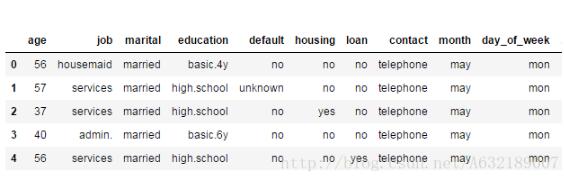
描述性統計1:describe()
result = bank['age'].describe()
pd.DataFrame(result ) #格式化成DataFrame
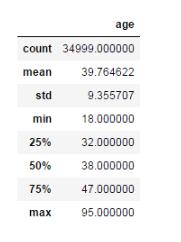
描述性統計2:describe(include=[‘number'])
include中填寫的是數據類型,若想查看所有數據的統計數據,則可填寫object,即include=['object'];若想查看float類型的數據,則為include=['float']。
result = bank.describe(include=['object'])
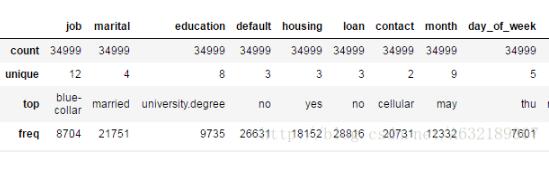
含義:
count:指定字段的非空總數。
unique:該字段中保存的值類型數量,比如性別列保存了男、女兩種值,則unique值則為2。
top:數量最多的值。
freq:數量最多的值的總數。
bank.describe(include=['number'])

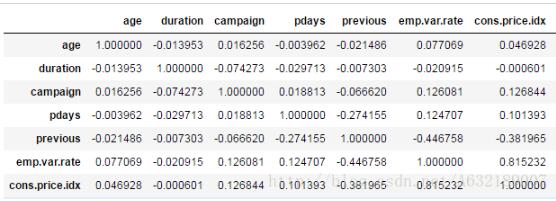
連續變量的相關系數(corr)
bank.corr()
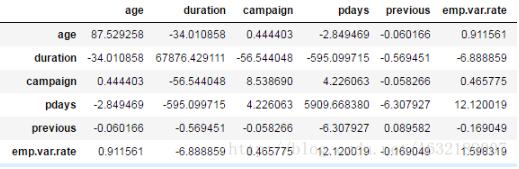
協方差矩陣(cov)
bank.cov()
刪除列
bank.drop('job', axis=1) #刪除年齡列,axis=1必不可少
排序
bank.sort_values(by=['job','age']) #根據工作、年齡升序排序
bank.sort_values(by=['job','age'], ascending=False) #根據工作、年齡降序排序
多表連接
準備數據:
import numpy as np
import pandas as pd
student = {'Name':['Bob','Alice','Carol','Henry','Judy','Robert','William'],
'Age':[12,16,13,11,14,15,24],
'Sex':['M','F','M','M','F','M','F']}
score = {'Name':['Bob','Alice','Carol','Henry','William'],
'Score':[75,35,87,86,57]}
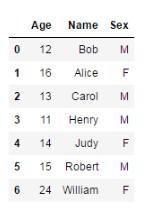
df_student = pd.DataFrame(student)
df_student
df_score = pd.DataFrame(score)
df_scorestudent:
score:
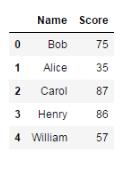
內連接
stu_score1 = pd.merge(df_student, df_score, on='Name')
stu_score1
注意,默認情況下,merge函數實現的是兩個表之間的內連接,即返回兩張表中共同部分的數據。可以通過how參數設置連接的方式,left為左連接;right為右連接;outer為外連接。
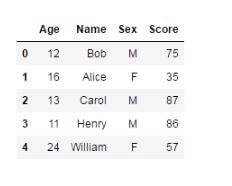
左連接
stu_score2 = pd.merge(df_student, df_score, on='Name',how='left')
stu_score2
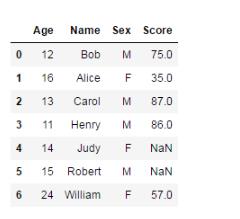
左連接中,沒有Score的學生Score為NaN
缺失值處理
現實生活中的數據是非常雜亂的,其中缺失值也是非常常見的,對于缺失值的存在可能會影響到后期的數據分析或挖掘工作,那么我們該如何處理這些缺失值呢?常用的有三大類方法,即刪除法、填補法和插值法。
刪除法
當數據中的某個變量大部分值都是缺失值,可以考慮刪除改變量;當缺失值是隨機分布的,且缺失的數量并不是很多是,也可以刪除這些缺失的觀測。
替補法
對于連續型變量,如果變量的分布近似或就是正態分布的話,可以用均值替代那些缺失值;如果變量是有偏的,可以使用中位數來代替那些缺失值;對于離散型變量,我們一般用眾數去替換那些存在缺失的觀測。
插補法
插補法是基于蒙特卡洛模擬法,結合線性模型、廣義線性模型、決策樹等方法計算出來的預測值替換缺失值。
此處測試使用上面學生成績數據進行處理
查詢某一字段數據為空的數量
sum(pd.isnull(stu_score2['Score']))
結果:2
直接刪除缺失值
stu_score2.dropna()
刪除前:
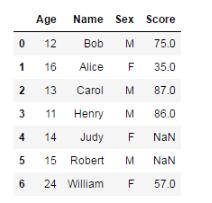
刪除后:
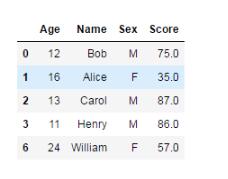
默認情況下,dropna會刪除任何含有缺失值的行
刪除所有行為缺失值的數據
import numpy as np import pandas as pd df = pd.DataFrame([[1,2,3],[3,4,np.nan], [12,23,43],[55,np.nan,10], [np.nan,np.nan,np.nan],[np.nan,1,2]], columns=['a1','a2','a3'])
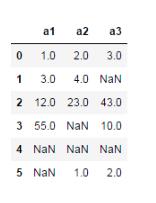
df.dropna() #該操作會刪除所有有缺失值的行數據
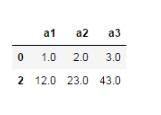
df.dropna(how='all') #該操作僅會刪除所有列均為缺失值的行數據
填充數據
使用一個常量來填補缺失值,可以使用fillna函數實現簡單的填補工作:
1、用0填補所有缺失值
df.fillna(0)
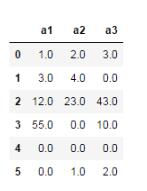
2、采用前項填充或后向填充
df.fillna(method='ffill') #用前一個值填充
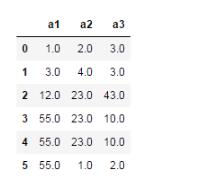
df.fillna(method='bfill') #用后一個值填充
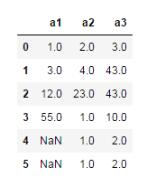
3、使用常量填充不同的列
df.fillna({'a1':100,'a2':200,'a3':300})
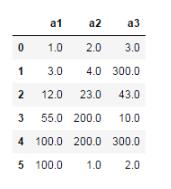
4、用均值或中位數填充各自的列
a1_median = df['a1'].median() #計算a1列的中位數
a1_median=7.5
a2_mean = df['a2'].mean() #計算a2列的均值
a2_mean = 7.5
a3_mean = df['a3'].mean() #計算a3列的均值
a3_mean = 14.5
df.fillna({'a1':a1_median,'a2':a2_mean,'a3':a3_mean}) #填充值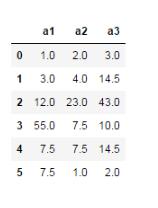
很顯然,在使用填充法時,相對于常數填充或前項、后項填充,使用各列的眾數、均值或中位數填充要更加合理一點,這也是工作中常用的一個快捷手段。
數據打亂(shuffle)
實際工作中,經常會碰到多個DataFrame合并后希望將數據進行打亂。在pandas中有sample函數可以實現這個操作。
df = df.sample(frac=1)
這樣對可以對df進行shuffle。其中參數frac是要返回的比例,比如df中有10行數據,我只想返回其中的30%,那么frac=0.3。
有時候,我們可能需要打混后數據集的index(索引)還是按照正常的排序。我們只需要這樣操作
df = df.sample(frac=1).reset_index(drop=True)
以上是“Python中pandas統計分析的案例”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





