溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關redis中主從復制原理的的示例分析,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
1.復制過程
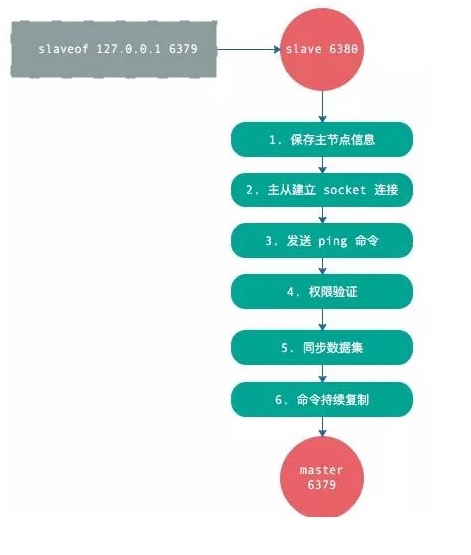
從節點執行 slaveof 命令。
從節點只是保存了 slaveof 命令中主節點的信息,并沒有立即發起復制。
從節點內部的定時任務發現有主節點的信息,開始使用 socket 連接主節點。
連接建立成功后,發送 ping 命令,希望得到 pong 命令響應,否則會進行重連。
如果主節點設置了權限,那么就需要進行權限驗證,如果驗證失敗,復制終止。
權限驗證通過后,進行數據同步,這是耗時最長的操作,主節點將把所有的數據全部發送給從節點。
當主節點把當前的數據同步給從節點后,便完成了復制的建立流程。接下來,主節點就會持續的把寫命令發送給從節點,保證主從數據一致性。
2.數據間的同步
上面說的復制過程,其中有一個步驟是“同步數據集”,這個就是現在講的“數據間的同步”。
redis 同步有 2 個命令:sync 和 psync,前者是 redis 2.8 之前的同步命令,后者是 redis 2.8 為了優化 sync 新設計的命令。我們會重點關注 2.8 的 psync 命令。
psync 命令需要 3 個組件支持:
主從節點各自復制偏移量
主節點復制積壓緩沖區
主節點運行 ID
主從節點各自復制偏移量:
參與復制的主從節點都會維護自身的復制偏移量。
主節點在處理完寫入命令后,會把命令的字節長度做累加記錄,統計信息在 info replication 中的 masterreploffset 指標中。
從節點每秒鐘上報自身的的復制偏移量給主節點,因此主節點也會保存從節點的復制偏移量。
從節點在接收到主節點發送的命令后,也會累加自身的偏移量,統計信息在 info replication 中。
通過對比主從節點的復制偏移量,可以判斷主從節點數據是否一致。
主節點復制積壓緩沖區:
復制積壓緩沖區是一個保存在主節點的一個固定長度的先進先出的隊列,默認大小 1MB。
這個隊列在 slave 連接是創建。這時主節點響應寫命令時,不但會把命令發送給從節點,也會寫入復制緩沖區。
他的作用就是用于部分復制和復制命令丟失的數據補救。通過 info replication 可以看到相關信息。
主節點運行 ID:
每個 redis 啟動的時候,都會生成一個 40 位的運行 ID。
運行 ID 的主要作用是用來識別 Redis 節點。如果使用 ip+port 的方式,那么如果主節點重啟修改了 RDB/AOF 數據,從節點再基于偏移量進行復制將是不安全的。所以,當運行 id 變化后,從節點將進行全量復制。也就是說,redis 重啟后,默認從節點會進行全量復制。
如果在重啟時不改變運行 ID 呢?
可以通過 debug reload 命令重新加載 RDB 并保持運行 ID 不變,從而有效的避免不必要的全量復制。
缺點是:debug reload 命令會阻塞當前 Redis 節點主線程,因此對于大數據量的主節點或者無法容忍阻塞的節點,需要謹慎使用。一般通過故障轉移機制可以解決這個問題。
psync 命令的使用方式:
命令格式為psync{runId}{offset}
runId:從節點所復制主節點的運行 id
offset:當前從節點已復制的數據偏移量
psync 執行流程:
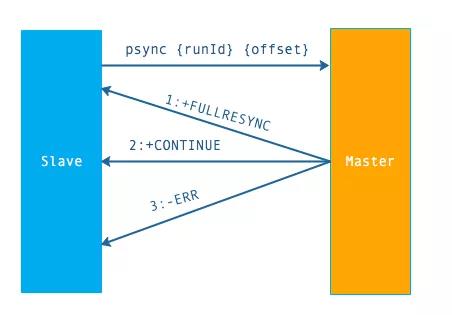
流程說明:
從節點發送 psync 命令給主節點,runId 就是目標主節點的 ID,如果沒有默認為 -1,offset 是從節點保存的復制偏移量,如果是第一次復制則為 -1.
主節點會根據 runid 和 offset 決定返回結果:
如果回復 +FULLRESYNC {runId} {offset} ,那么從節點將觸發全量復制流程。
如果回復 +CONTINUE,從節點將觸發部分復制。
如果回復 +ERR,說明主節點不支持 2.8 的 psync 命令,將使用 sync 執行全量復制。
到這里,數據之間的同步就講的差不多了,篇幅還是比較長的。主要是針對 psync 命令相關之間的介紹。
3.全量復制
全量復制是 Redis 最早支持的復制方式,也是主從第一次建立復制時必須經歷的的階段。觸發全量復制的命令是 sync 和 psync。之前說過,這兩個命令的分水嶺版本是 2.8,redis 2.8 之前使用 sync 只能執行全量不同,2.8 之后同時支持全量同步和部分同步。
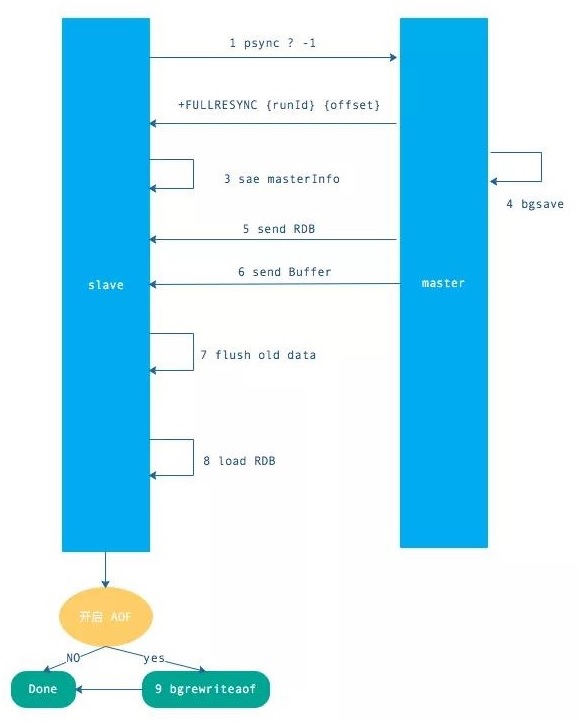
流程如下:
發送 psync 命令(spync ? -1)
主節點根據命令返回 FULLRESYNC
從節點記錄主節點 ID 和 offset
發送 psync 命令(spync ? -1)
主節點根據命令返回 FULLRESYNC
從節點記錄主節點 ID 和 offset
主節點 bgsave 并保存 RDB 到本地
主節點發送 RBD 文件到從節點
從節點收到 RDB 文件并加載到內存中
主節點在從節點接受數據的期間,將新數據保存到“復制客戶端緩沖區”,當從節點加載 RDB 完畢,再發送過去。(如果從節點花費時間過長,將導致緩沖區溢出,最后全量同步失敗)
從節點清空數據后加載 RDB 文件,如果 RDB 文件很大,這一步操作仍然耗時,如果此時客戶端訪問,將導致數據不一致,可以使用配置slave-server-stale-data 關閉.
從節點成功加載完 RBD 后,如果開啟了 AOF,會立刻做 bgrewriteaof。
以上加粗的部分是整個全量同步耗時的地方。
注意:
如過 RDB 文件大于 6GB,并且是千兆網卡,Redis 的默認超時機制(60 秒),會導致全量復制失敗。可以通過調大 repl-timeout 參數來解決此問題。 Redis 雖然支持無盤復制,即直接通過網絡發送給從節點,但功能不是很完善,生產環境慎用。
4.部分復制
當從節點正在復制主節點時,如果出現網絡閃斷和其他異常,從節點會讓主節點補發丟失的命令數據,主節點只需要將復制緩沖區的數據發送到從節點就能夠保證數據的一致性,相比較全量復制,成本小很多。
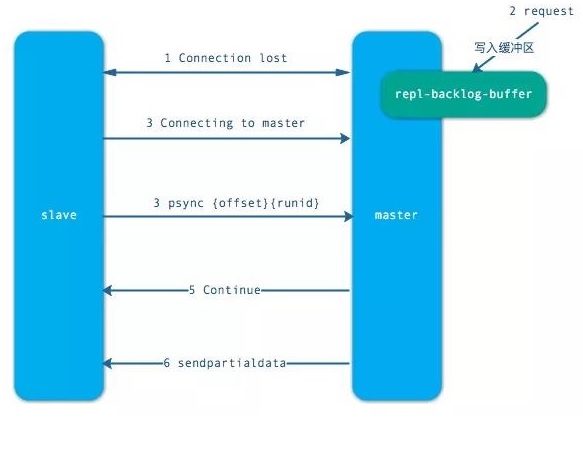
當從節點出現網絡中斷,超過了 repl-timeout 時間,主節點就會中斷復制連接。
主節點會將請求的數據寫入到“復制積壓緩沖區”,默認 1MB。
當從節點恢復,重新連接上主節點,從節點會將 offset 和主節點 id 發送到主節點。
主節點校驗后,如果偏移量的數后的數據在緩沖區中,就發送 cuntinue 響應 —— 表示可以進行部分復制。
主節點將緩沖區的數據發送到從節點,保證主從復制進行正常狀態。
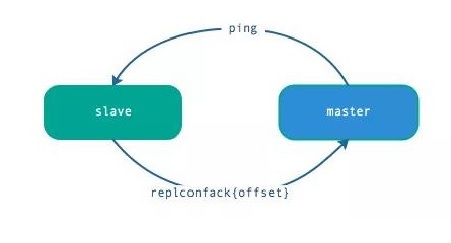
5.心跳
主從節點在建立復制后,他們之間維護著長連接并彼此發送心跳命令。
心跳的關鍵機制如下:
中從都有心跳檢測機制,各自模擬成對方的客戶端進行通信,通過 client list 命令查看復制相關客戶端信息,主節點的連接狀態為 flags = M,從節點的連接狀態是 flags = S。
主節點默認每隔 10 秒對從節點發送 ping 命令,可修改配置 repl-ping-slave-period 控制發送頻率。
從節點在主線程每隔一秒發送 replconf ack{offset} 命令,給主節點上報自身當前的復制偏移量。
主節點收到 replconf 信息后,判斷從節點超時時間,如果超過 repl-timeout 60 秒,則判斷節點下線。
注意:
為了降低主從延遲,一般把 redis 主從節點部署在相同的機房/同城機房,避免網絡延遲帶來的網絡分區造成的心跳中斷等情況。
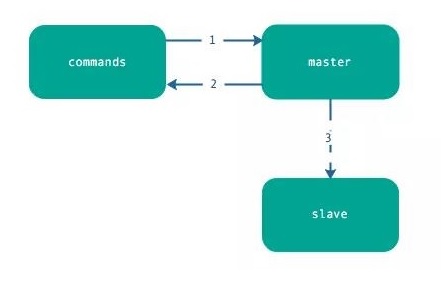
6.異步復制
主節點不但負責數據讀寫,還負責把寫命令同步給從節點,寫命令的發送過程是異步完成,也就是說主節點處理完寫命令后立即返回客戶度,并不等待從節點復制完成。
異步復制的步驟很簡單,如下:
主節點接受處理命令。
主節點處理完后返回響應結果 。
對于修改命令,異步發送給從節點,從節點在主線程中執行復制的命令。
關于“redis中主從復制原理的的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





