溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
分享一個簡單的小需求應該怎么設計實現以及有關Redis的使用
Redis在實際應用中使用的非常廣泛,本篇文章就從一個簡單的需求說起,為你講述一個需求是如何從頭到尾開始做的,又是如何一步步完善的。之前寫過一篇《如何實現頁面廣告隨時上下線、過期自動下線及到時自動上線》,也涉及到了Redis在項目中的實際應用,有興趣的可以看一下。
設定,現在我們有一個APP,產品新提出一個叫“程序員樹洞”的功能,具體功能就不說了,其中這個功能有一點需要做的是在使用該功能時,如果是首次進入會展示一個協議頁面,用戶需要勾選后點確定才能進入功能,此后再進該功能,不再顯示協議頁直接進入該功能。如下圖所示,
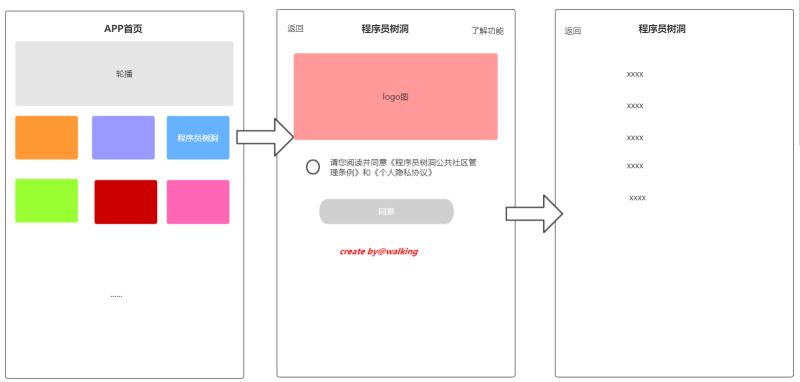
原型圖
需求就是這么的簡單,我們來分析一下。
1、用戶點擊該功能時前端需要知道該給用戶顯示哪個頁面,這一步需要請求后端接口,后臺告訴前端這個用戶有沒有同意過協議。
2、用戶勾選協議點確定,后端需要記錄這步操作(記錄用戶已經同意協議),這一步需在點確定時前端請求后端接口。
概要設計
前面需求分析里說了,后端需要告訴前端用戶有沒有統一過協議,所以后端需要把這個信息記錄下來,最好是記錄到數據庫保存,那就需要一張表來記錄同意過協議的用戶。表結構大致是:id,客戶號,插入時間。
詳細設計
1、記錄客戶是否已同意過協議并提供查詢功能(查詢是否同意過協議)
2、沒有同意過的和同意過的用戶信息怎么存儲
3、如何高效的查詢是否同意過
4、怎么保證高并發下服務的可用性,數據庫的可用性
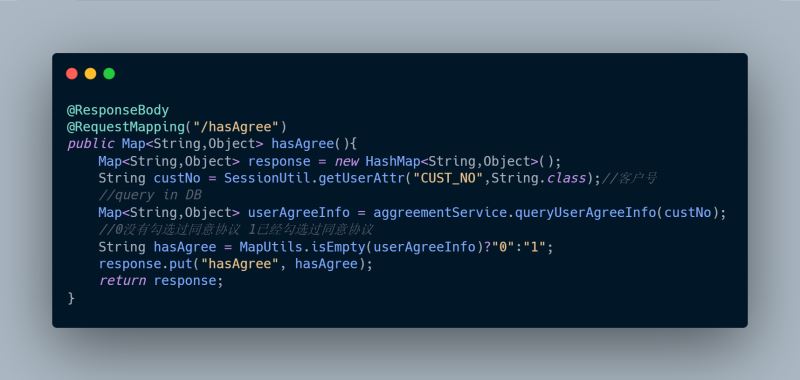
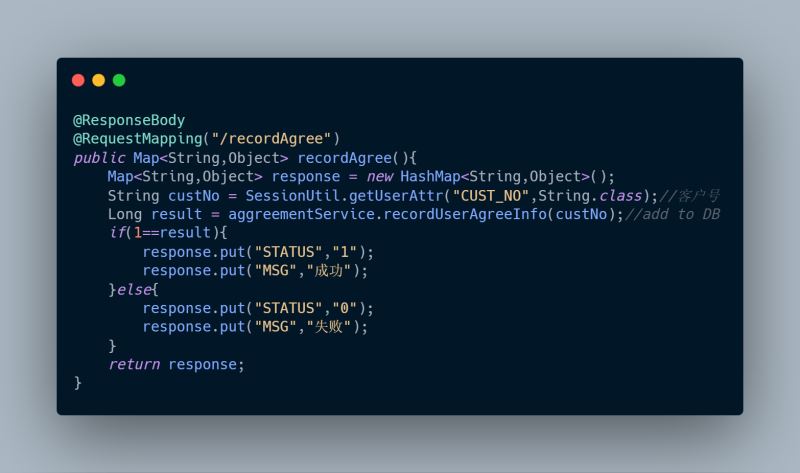
后端提供兩個接口,
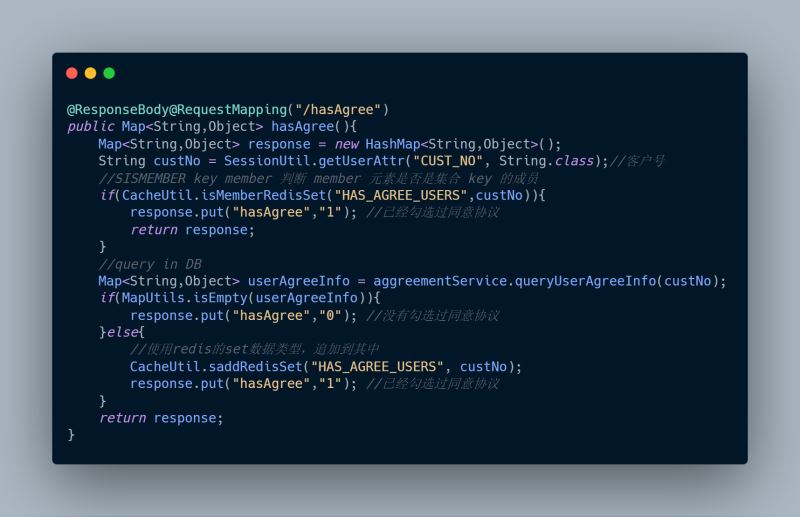
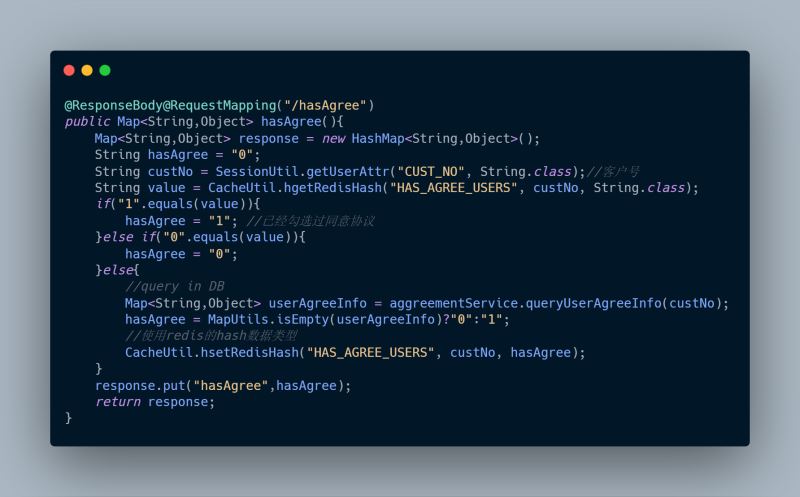
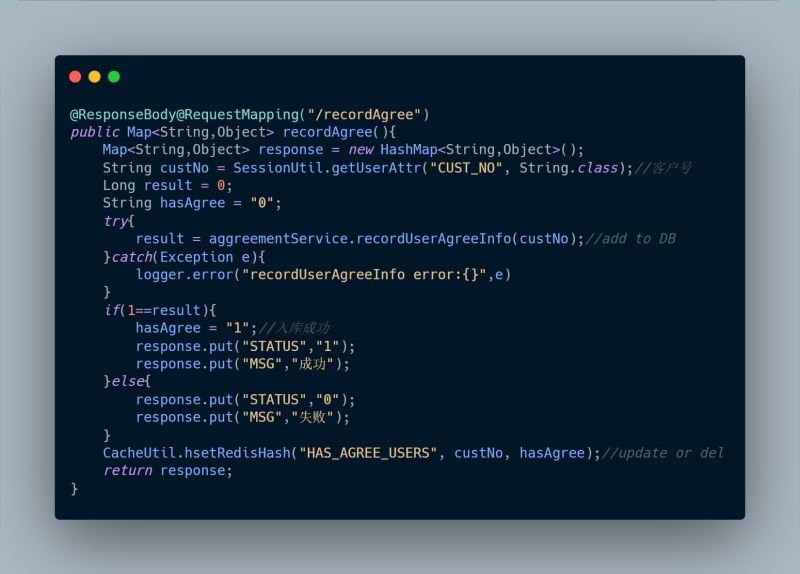
1、hasAgree(),查詢該用戶是否已同意協議
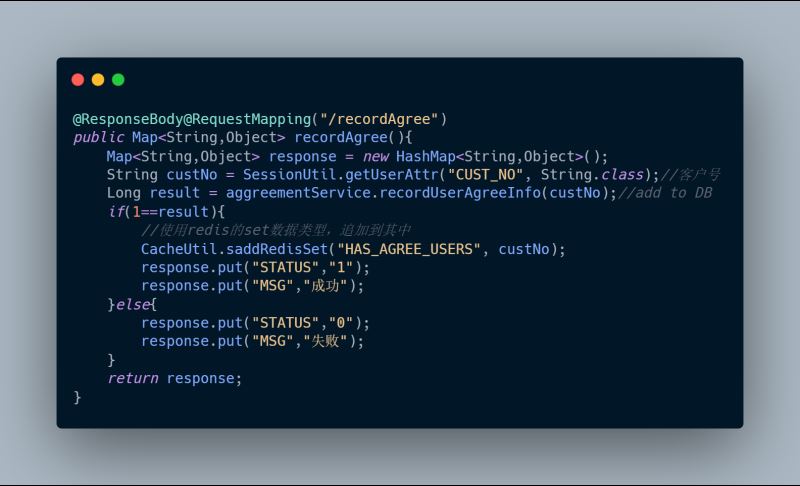
2、recordAgree(),記錄用戶已同意協議
很容易嘛!不就是CRUD嗎,小意思。用戶進來先查數據庫有沒有記錄,沒有返回用戶沒有同意過協議,前端給用戶展示協議頁,否則展示功能頁;用戶點同意后,后臺記錄用戶已點了同意協議,記錄到庫。一個查詢一個插入,5分鐘搞定嘛。

直接甩代碼
第一版代碼如上,我覺得剛入門的程序員都能夠寫出來。如果用戶量不大,該功能的點擊量不大的話,這么做還是勉強說得過去。為什么說勉強說得過去,因為存在隱患,你看啊如果每次點擊都會去查庫,假如有人惡意攻擊,仿造高并發,瞬時大量請求過來都去查庫,很可能數據庫頂不住就掛了。或者就算數據庫沒掛,每次查庫也都是浪費啊。所以這是個隱患,或者潛在的危險,那么第二版我們就去解決這個問題。
考慮到每次查庫很浪費,那我們使用緩存好不好? 進來先查緩存有沒有對應的數據,緩存里有就直接返回,沒有則查庫,庫里有就存緩存。這樣redis就分擔了一部分數據庫的壓力。
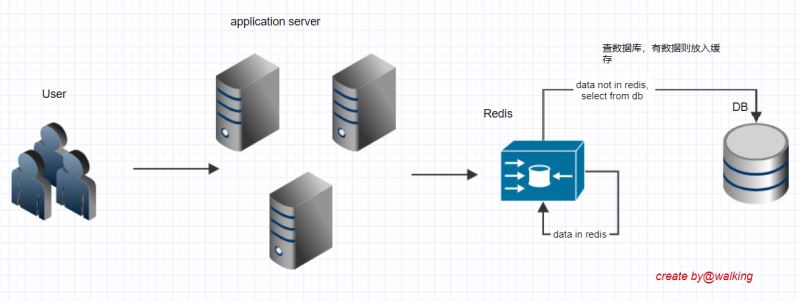
代碼呈上
這一版好一點了,部分請求分攤到redis了,減輕了數據庫的壓力。
隨著客戶量的增加,點擊這個功能的次數、頻率越來越高,假如有人頻繁點擊該功能,彈出協議后,退出,再點,再退出…就是不點確定

這樣會有啥問題?
這樣的話后臺緩存中沒有,數據庫中也沒有,每次都會走數據庫,繞過了緩存,直接都走數據庫,這類請求量多了也是個問題,這就是緩存穿透。所以第三版,我們來解決緩存穿透的問題。
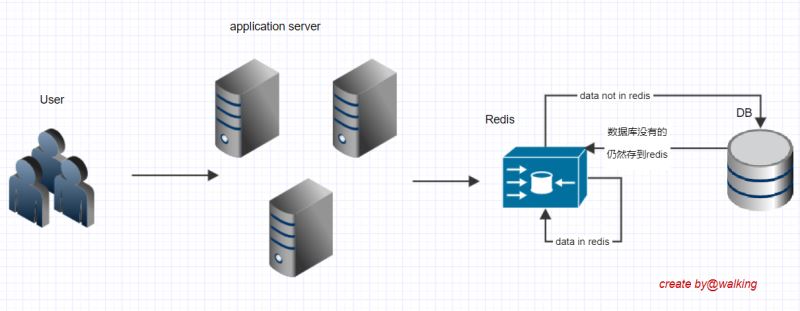
解決緩存穿透:因為是數據庫和緩存都沒有,我們可以讓數據庫沒有的也存到redis。需要改變redis的數據類型,由set改為map,目的是記錄狀態值。
可以看到,我們的這個key-field-value沒有設置過期時間,因為可以認為這個key是一個熱點key,對于熱點key我們的處理方式是,永久有效或過期時間盡量長一點。
另一個關于緩存的問題,那就是緩存擊穿。
何為緩存擊穿?假如該功能在前期宣傳力度比較大,或預計該功能上線后點擊量比較大的話,那么在功能上線后很可能就會一瞬間大量用戶來點擊這個功能,因為我們前面的邏輯是首次進入該功能的用戶展示協議頁,我們的后臺處理雖然加了redis緩存,但是新上的功能所有用戶都沒有點過,那么redis里就沒有緩存,是不是所有用戶的請求都落到數據庫了?一旦瞬間流量非常大,數據庫安全性就存在隱患,有被搞垮的可能。
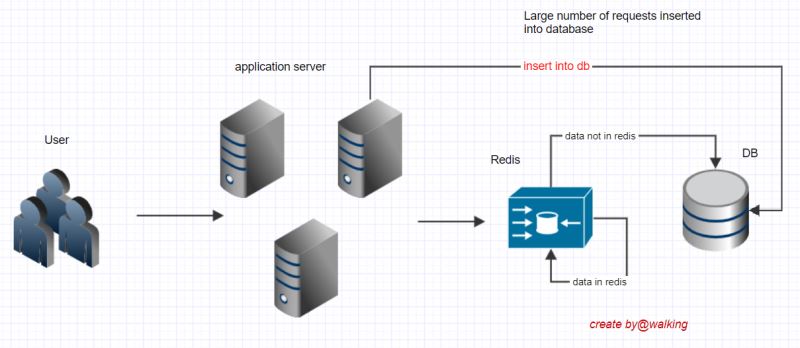
這個問題就是可以理解為緩存擊穿。(實際的緩存擊穿是某個key在緩存里不存在或是失效后,某一瞬間很多請求都來訪問這個key,都判定為redis里沒有這個key,就都去查庫。)
所以怎么解決呢?我們可以在該功能上線前,提前將需要做緩存的數據放入redis,即緩存預熱。
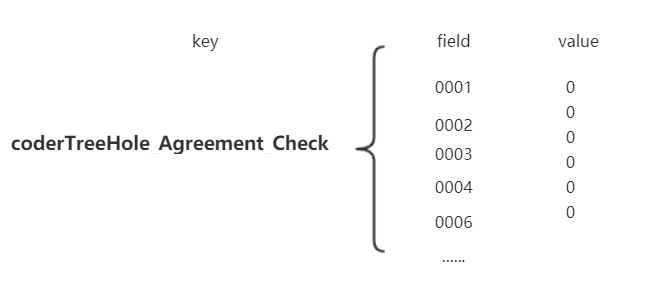
如何預熱?將所有用戶的信息都放到redis.舉個栗子(也許不是最佳的),我們使用Redis的hash數據結構,key-field-value。key我們可以固定一個字符串如coderTreeHole_Agreement_Check,field我們可以用客戶號(唯一),value是個標志位,用0代表沒同意過協議,1代表同意過。一般在電商大促前都會對熱點key進行預熱,不然真的扛不住。
and,用戶量很大的時候redis里的coderTreeHole_Agreement_Check這個key是不是很大?在redis集群部署模式下,這個key是不是都放在一個節點上?why?
redis3.0上加入了cluster模式,實現的redis的分布式存儲,也就是說每臺redis節點上存儲不同的內容。在redis的每一個節點上,都有這么兩個東西,一個是插槽(slot),它的的取值范圍是:0-16383。還有一個就是cluster,可以理解為是一個集群管理的插件。當我們的存取的key到達的時候,redis會根據crc16的算法得出一個結果,然后把結果對16384求余數,這樣每個key都會對應一個編號在0-16383之間的哈希槽,通過這個值,去找到對應的插槽所對應的節點,然后直接自動跳轉到這個對應的節點上進行存取操作。
看了上面這段話,明白了吧。那對于這個大key而且是熱點key的請求,是不是都落到某一個redis節點上了?大key會帶來很多問題,篇幅原因以后再來細說,跑題了。。。
針對這個需求,你還有什么方法防治緩存擊穿?
可以看到我們上面的設計其實都是實時對數據庫進行操作的。
例如,當用戶點了同意,前端就調后臺的recordAgree方法將該記錄記錄到數據庫,即這條記錄是立馬插入到數據庫的。
如果剛上線這個功能,大量用戶同時點這個功能,并發量大的話,請求走到后臺,那么寫庫的操作就非常多,數據庫連接數突然激增,數據庫會頂不住吧。
所以為避免流量集中落到數據庫,此時我們可以使用消息隊列MQ。將插入操作的請求發往消息隊列,使插入操作以一定的速率到數據庫執行,使得對數據庫的請求數盡量平滑,消息發給消息隊列立即返回給前端成功,不用等待插庫完成,用MQ實現了異步解耦,削峰填谷。
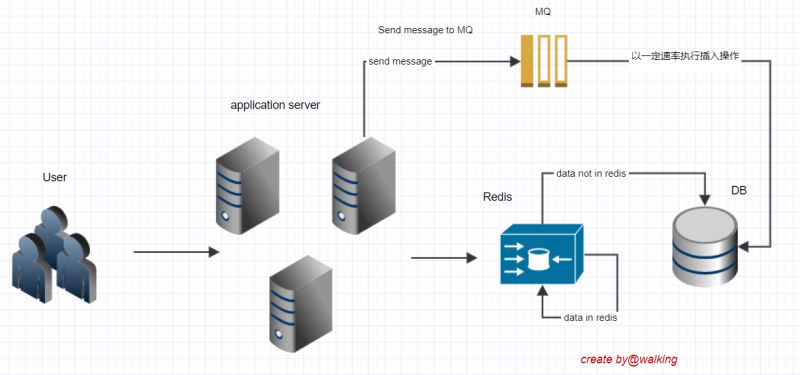
到這你是不是忍不住說設計的真贊~~

另外MQ的使用注意的點還是非常多的,如:消息隊列的消息重復消費問題,順序問題,事務消息等。
對于這個需求設計到哪種程度取決于你的用戶量和并發量,如果是像雙十一那樣,肯定是要用消息隊列的,那一般小的例如,用戶量1千萬,日活10萬,請求最集中的也就是中午9-12點,下午13-17點吧,差不多8個小時,平均一個小時1.25萬,用戶都來點這個功能的話,每分鐘208,每秒3.5,算不上高并發,數據庫完全扛得住。
總結一下,這個需求我們用到的知識點(敲黑板),redis數據緩存,redis緩存穿透,緩存擊穿,熱點key問題,redis大key問題(沒具體講),消息隊列異步解耦等。
畫圖碼字不易,如果覺得我寫的還可以,記得點贊鼓勵一下哦,如果覺得有問題歡迎指正。

好了,就給大家介紹這么多。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





