溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何設定Keras - GPU ID 和顯存占用,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
初步嘗試 Keras (基于 Tensorflow 后端)深度框架時, 發現其對于 GPU 的使用比較神奇, 默認竟然是全部占滿顯存, 1080Ti 跑個小分類問題, 就一下子滿了. 而且是服務器上的兩張 1080Ti.
服務器上的多張 GPU 都占滿, 有點浪費性能.
因此, 需要類似于 Caffe 等框架的可以設定 GPU ID 和顯存自動按需分配.
實際中發現, Keras 還可以限制 GPU 顯存占用量.
這里涉及到的內容有:
GPU ID 設定
GPU 顯存占用按需分配
GPU 顯存占用限制
GPU 顯存優化
1. GPU ID 設定
#! -- coding: utf-8 --*-- import os os.environ["CUDA_VISIBLE_DEVICES"] = "1"
這里將 GPU ID 設為 1.
GPU ID 從 0 開始, GPUID=1 即表示第二塊 GPU.
2. GPU 顯存占用按需分配
#! -- coding: utf-8 --*-- import tensorflow as tf import keras.backend.tensorflow_backend as ktf # GPU 顯存自動調用 config = tf.ConfigProto() config.gpu_options.allow_growth=True session = tf.Session(config=config) ktf.set_session(session)
3. GPU 顯存占用限制
#! -- coding: utf-8 --*-- import tensorflow as tf import keras.backend.tensorflow_backend as ktf # 設定 GPU 顯存占用比例為 0.3 config = tf.ConfigProto() config.gpu_options.per_process_gpu_memory_fraction = 0.3 session = tf.Session(config=config) ktf.set_session(session )
這里雖然是設定了 GPU 顯存占用的限制比例(0.3), 但如果訓練所需實際顯存占用超過該比例, 仍能正常訓練, 類似于了按需分配.
設定 GPU 顯存占用比例實際上是避免一定的顯存資源浪費.
4. GPU ID 設定與顯存按需分配
#! -- coding: utf-8 --*-- import os import tensorflow as tf import keras.backend.tensorflow_backend as ktf # GPU 顯存自動分配 config = tf.ConfigProto() config.gpu_options.allow_growth=True #config.gpu_options.per_process_gpu_memory_fraction = 0.3 session = tf.Session(config=config) ktf.set_session(session) # 指定GPUID, 第一塊GPU可用 os.environ["CUDA_VISIBLE_DEVICES"] = "0"
5. 利用fit_generator最小化顯存占用比例/數據Batch化
#! -- coding: utf-8 --*--
# 將內存中的數據分批(batch_size)送到顯存中進行運算
def generate_arrays_from_memory(data_train, labels_train, batch_size):
x = data_train
y=labels_train
ylen=len(y)
loopcount=ylen // batch_size
while True:
i = np.random.randint(0,loopcount)
yield x[i*batch_size:(i+1)*batch_size],y[i*batch_size:(i+1)*batch_size]
# load數據到內存
data_train=np.loadtxt("./data_train.txt")
labels_train=np.loadtxt('./labels_train.txt')
data_val=np.loadtxt('./data_val.txt')
labels_val=np.loadtxt('./labels_val.txt')
hist=model.fit_generator(generate_arrays_from_memory(data_train,
labels_train,
batch_size),
steps_per_epoch=int(train_size/bs),
epochs=ne,
validation_data=(data_val,labels_val),
callbacks=callbacks )5.1 數據 Batch 化
#! -- coding: utf-8 --*--
def process_line(line):
tmp = [int(val) for val in line.strip().split(',')]
x = np.array(tmp[:-1])
y = np.array(tmp[-1:])
return x,y
def generate_arrays_from_file(path,batch_size):
while 1:
f = open(path)
cnt = 0
X =[]
Y =[]
for line in f:
# create Numpy arrays of input data
# and labels, from each line in the file
x, y = process_line(line)
X.append(x)
Y.append(y)
cnt += 1
if cnt==batch_size:
cnt = 0
yield (np.array(X), np.array(Y))
X = []
Y = []
f.close() 補充知識:Keras+Tensorflow指定運行顯卡以及關閉session空出顯存
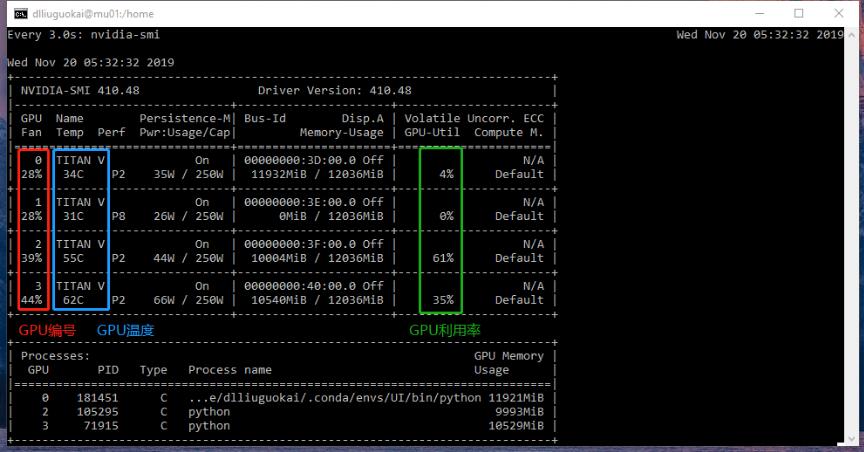
Step1: 查看GPU
watch -n 3 nvidia-smi #在命令行窗口中查看當前GPU使用的情況, 3為刷新頻率
Step2: 導入模塊
導入必要的模塊
import os import tensorflow as tf from keras.backend.tensorflow_backend import set_session from numba import cuda
Step3: 指定GPU
程序開頭指定程序運行的GPU
os.environ['CUDA_VISIBLE_DEVICES'] = '1' # 使用單塊GPU,指定其編號即可 (0 or 1or 2 or 3)
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2,3' # 使用多塊GPU,指定其編號即可 (引號中指定即可)
Step4: 創建會話,指定顯存使用百分比
創建tensorflow的Session
config = tf.ConfigProto() config.gpu_options.per_process_gpu_memory_fraction = 0.1 # 設定顯存的利用率 set_session(tf.Session(config=config))
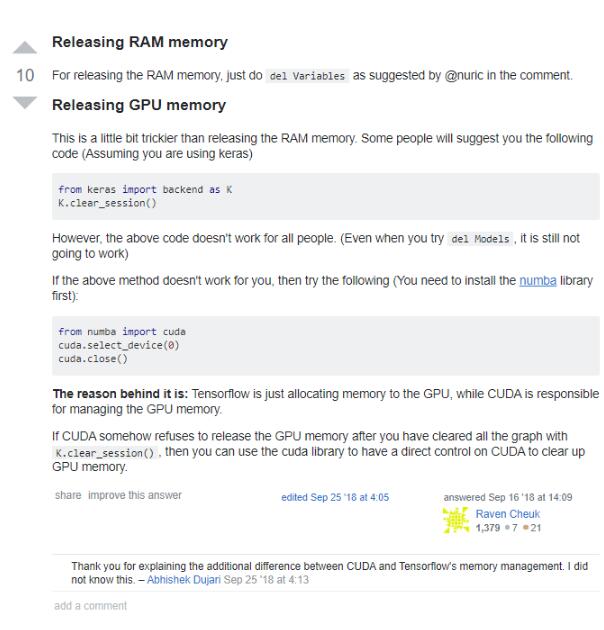
Step5: 釋放顯存
確保Volatile GPU-Util顯示0%
程序運行完畢,關閉Session
K.clear_session() # 方法一:如果不關閉,則會一直占用顯存 cuda.select_device(1) # 方法二:選擇GPU1 cuda.close() #關閉選擇的GPU
關于如何設定Keras - GPU ID 和顯存占用就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





