溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
CFT(Crash Fault Tolerance),即故障容錯,是非拜占庭問題的容錯技術。
Paxos 問題是指分布式的系統中存在故障(crash fault),但不存在惡意(corrupt)節點的場景(即可能消息丟失或重復,但無錯誤消息)下的共識達成問題,是分布式共識領域最為常見的問題。最早由Leslie Lamport用 Paxon 島的故事模型來進行描述而得以命名。解決Paxos問題的算法主要有Paxos系列算法和Raft算法,Paxos算法和Raft算法都屬于強一致性算法。
在常見的分布式系統中,總會發生諸如機器宕機或網絡異常(包括消息的延遲、丟失、重復、亂序,網絡分區)等情況。Paxos算法需要解決的問題就是如何在一個可能發生異常的分布式系統中,快速且正確地在集群內部對某個數據的值達成一致,并且保證不論發生任何異常,都不會破壞整個系統的一致性。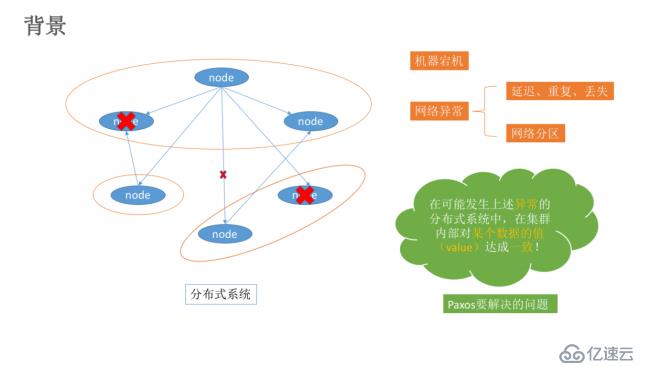
Paxos算法用于解決分布式系統的一致性問題。
1990年,Leslie Lamport 在論文《The Part-time Parliament》中提出了Paxos共識算法,在工程角度實現了一種最大化保障分布式系統一致性(存在極小的概率無法實現一致)的機制。Leslie Lamport作為分布式系統領域的早期研究者,因為相關成果獲得了2013年度圖靈獎。
Leslie Lamport在論文中將Paxos問題表述如下:
希臘島嶼Paxon上的執法者在議會大廳中表決通過法律(一次Paxos過程),并通過服務員(proposer)傳遞紙條的方式交流信息,每個執法者會將通過的法律記錄在自己的賬目上。問題在于執法者和服務員都不可靠,他們隨時會因為各種事情離開議會大廳(服務器拓機或網絡斷開),并隨時可能有新的執法者進入議會大廳進行法律表決(新加入機器),使用何種方式能夠使得表決過程正常進行,且通過的法律不發生矛盾(對一個值達成一致)。?
Paxos過程中不存在拜占庭將軍問題(消息不會被篡改)和兩將軍問題(信道可靠)。
Paxos是首個得到證明并被廣泛應用的共識算法,其原理類似兩階段提交算法,進行了泛化和擴展,通過消息傳遞來逐步消除系統中的不確定狀態。
作為后續很多共識算法(如 Raft、ZAB等)的基礎,Paxos算法基本思想并不復雜,但最初論文中描述比較難懂,甚至連發表也幾經波折。2001年,Leslie Lamport專門發表論文《Paxos Made Simple》進行重新解釋,其對Paxos算法的描述如下:
Phase1
(a) A proposer selects a proposal number n and sends a prepare request with number n to a majority of acceptors.
(b) If an acceptor receives a prepare request with number n greater than that of any prepare request to which it has already responded, then it responds to the request with a promise not to accept any more proposals numbered less than n and with the highest-numbered pro-posal (if any) that it has accepted.
Phase 2
(a) If the proposer receives a response to its prepare requests (numbered n) from a majority of acceptors, then it sends an accept request to each of those acceptors for a proposal numbered n with a value v , where v is the value of the highest-numbered proposal among the responses, or is any value if the responses reported no proposals.
(b) If an acceptor receives an accept request for a proposal numbered n, it accepts the proposal unless it has already responded to a prepare request having a number greater than n.
Paxos算法目前在Google的Chubby、MegaStore、Spanner等系統中得到了應用,Hadoop中的ZooKeeper也使用了Paxos算法,但使用的算法是原始Paxos算法的改進算法。通常以Paxos算法為基礎,在實現過程中處理實際應用場景中的具體細節,可以得到一個Paxos改進算法。
Paxos算法的基本思路類似兩階段提交:多個提案者先要爭取到提案的權利(得到大多數接受者的支持);成功的提案者發送提案給所有人進行確認,得到大部分人確認的提案成為批準的結案。
Paxos協議有三種角色:Proposer(提議者),Acceptor(決策者),Learner(決策學習者)。
Paxos?是一個兩階段的通信協議,Paxos算法的基本流程如下: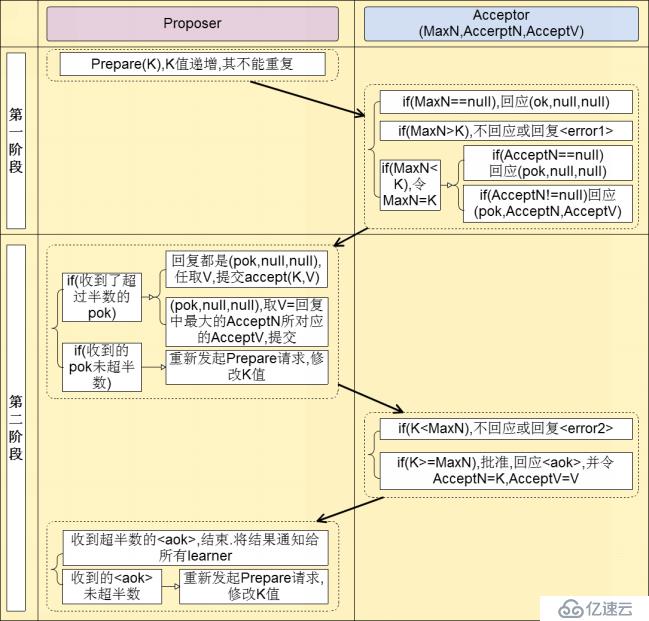
第一階段Prepare:
A、Proposer生成一個全局唯一的提案編號N,然后向所有Acceptor發送編號為N的Prepare請求。
B、如果一個Acceptor收到一個編號為N的Prepare請求,且N大于本Acceptor已經響應過的所有Prepare請求的編號,那么本Acceptor就會將其已經接受過的編號最大的提案(如果有的話)作為響應反饋給Proposer,同時本Acceptor承諾不再接受任何編號小于N的提案。
第二階段 Accept
A、如果Proposer收到半數以上Acceptor對其發出的編號為N的Prepare請求的響應,那么Proposer就會發送一個針對[N,V]提案的Accept請求給半數以上的Acceptor。V就是收到的響應中編號最大的提案的value,如果響應中不包含任何提案,那么V由Proposer自己決定。
B、如果Acceptor收到一個針對編號為N的提案的Accept請求,只要該Acceptor沒有對編號大于N的Prepare請求做出過響應,Acceptor就接受該提案。
Paxos 并不保證系統總處在一致的狀態。但由于每次達成共識至少有超過一半的節點參與,最終整個系統都會獲知共識結果。如果提案者在提案過程中出現故障,可以通過超時機制來緩解。
Paxos 能保證在超過一半的節點正常工作時,系統總能以較大概率達成共識。
對于提案ID的選擇,《Paxos made simple》中提到的是讓所有的Proposer都從不相交的數據集合中進行選擇。
Google的Chubby論文中給出提案ID的生成算法如下:假設有n個Proposer,每個編號為
ir(0<=ir<n),Proposal編號的任何值s都應該大于它已知的最大值,并且滿足:
s %n = ir??? =>???? s = m*n + ir????Proposer已知的最大值來自兩部分:Proposer自己對編號自增后的值和接收到Acceptor的拒絕后所得到的值。
以3個Proposer P1、P2、P3為例,開始m=0,編號分別為0,1,2。
1)?P1提交的時候發現了P2已經提交,P2編號為1 >P1的0,因此P1重新計算編號:new P1 = 1*3+1 = 4;
2)?P3以編號2提交,發現小于P1的4,因此P3重新編號:new P3 = 1*3+2 = 5。
如果兩個提案者恰好依次提出更新的提案,則導致活鎖,系統會永遠無法達成共識(實際發生概率很小)。活鎖沒有產生阻塞,但是一直無法達成一致。
活鎖有三種解決方案:
A、在被打回第一階段再次發起PrepareRequest請求前加入隨機等待時間。
B、設置一個超時時間,到達超時時間后,不再接收PrepareRequest請求。
C、在Proposer中選舉出一個leader,通過leader統一發出PrepareRequest和AcceptRequest。
Paxos算法在執行過程中會產生很多的異常情況:Proposer宕機,Acceptor在接收Proposal后宕機,Proposer接收消息后宕機,Acceptor在Accept后宕機,Learner宕機,存儲失敗等等。
為保證Paxos算法的正確性,Proposer、Aceptor、Learner都需要實現持久存儲,以做到Server恢復后仍能正確參與Paxos處理。
????Proposer存儲已提交的最大proposal編號、決議編號(instance id)。
????Acceptor存儲已承諾(promise)的最大編號、已接受(Accept)的最大編號和Value、決議編號。
????Learner存儲已學習過的決議和編號。
Paxos算法只有兩種情況下服務不可用:一是超過半數的Proposer異常,二是出現活鎖。前者可以通過增加Proposer的個數來降低由于Proposer異常影響服務的概率,后者本身發生的概率就極低。
Paxos是分布式系統一致性協議的基礎,其它的協議(raft、zab等)都是Paxos協議的改進版本。Paxos側重理論,實現Paxos非常困難。
微信后臺生產級Paxos類庫PhxPaxos實現:
https://github.com/Tencent/paxosstore
https://github.com/tencent-wechat/phxpaxos
基于Paxos算法的改進算法的資料集合:
https://github.com/dgryski/awesome-consensus
三軍問題的描述如下:
1) 1支紅軍在山谷里扎營,在周圍的山坡上駐扎著3支藍軍;
2) 紅軍比任意1支藍軍都要強大;如果1支藍軍單獨作戰,紅軍勝;如果2支或以上藍軍同時進攻,藍軍勝;
3) 三支藍軍需要同步他們的進攻時間;但他們惟一的通信媒介是派通信兵步行進入山谷,在那里他們可能被俘虜,從而將信息丟失;或者為了避免被俘虜,可能在山谷停留很長時間;
4) 每支軍隊有1個參謀負責提議進攻時間;每支軍隊也有1個將軍批準參謀提出的進攻時間;很明顯,1個參謀提出的進攻時間需要獲得至少2個將軍的批準才有意義;
5) 問題:是否存在一個協議,能夠使得藍軍同步他們的進攻時間?
三軍問題符合Paxos問題場景,參謀和將軍需要遵循一些基本的規則:
1) 參謀以兩階段提交(prepare/commit)的方式來發起提議,在Prepare階段需要給出一個提議編號;
2) 在Prepare階段產生沖突,將軍以提議編號大小來裁決,提議編號大的參謀勝出;
3) 參謀在Prepare階段如果收到將軍返回的已接受進攻時間,在Commit階段必須使用返回的進攻時間;
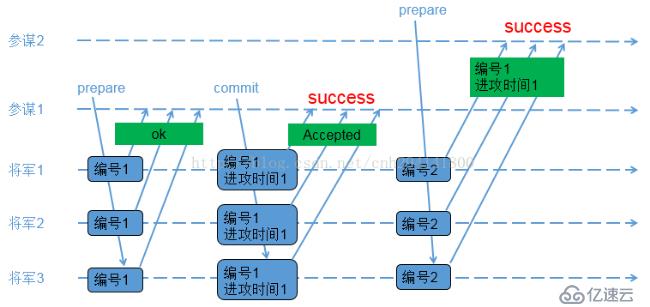
A、參謀1發起提議,派通信兵帶信給3個將軍,內容為(編號1);
B、3個將軍收到參謀1的提議,由于之前還沒有保存任何編號,因此把(編號1)保存下來,避免遺忘;同時讓通信兵帶信回去,內容為(ok);
C、參謀1收到至少2個將軍的回復,再次派通信兵帶信給3個將軍,內容為(編號1,進攻時間1);
D、3個將軍收到參謀1的時間,把(編號1,進攻時間1)保存下來,避免遺忘;同時讓通信兵帶信回去,內容為(Accepted);
E、參謀1收到至少2個將軍的(Accepted)內容,確認進攻時間已經被大家接收;
F、參謀2發起提議,派通信兵帶信給3個將軍,內容為(編號2);
G、3個將軍收到參謀2的提議,由于(編號2)比(編號1)大,因此把(編號2)保存下來,避免遺忘;又由于之前已經接受參謀1的提議,因此讓通信兵帶信回去,內容為(編號1,進攻時間1);
H、參謀2收到至少2個將軍的回復,由于回復中帶來了已接受的參謀1的提議內容,參謀2因此不再提出新的進攻時間,接受參謀1提出的時間;
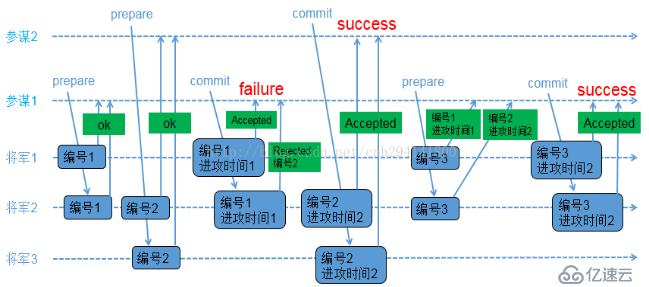
1) 參謀1發起提議,派通信兵帶信給3個將軍,內容為(編號1);
2) 3個將軍的情況如下
A、將軍1和將軍2收到參謀1的提議,將軍1和將軍2把(編號1)記錄下來,如果有其他參謀提出更小的編號,將被拒絕;同時讓通信兵帶信回去,內容為(ok);
B、負責通知將軍3的通信兵被抓,因此將軍3沒收到參謀1的提議;
3) 參謀2在同一時間也發起了提議,派通信兵帶信給3個將軍,內容為(編號2);
4) 3個將軍的情況如下
A、將軍2和將軍3收到參謀2的提議,將軍2和將軍3把(編號2)記錄下來,如果有其他參謀提出更小的編號,將被拒絕;同時讓通信兵帶信回去,內容為(ok);
B、負責通知將軍1的通信兵被抓,因此將軍1沒收到參謀2的提議;
5) 參謀1收到至少2個將軍的回復,再次派通信兵帶信給有答復的2個將軍,內容為(編號1,進攻時間1);
6) 2個將軍的情況如下
A、將軍1收到了(編號1,進攻時間1),和自己保存的編號相同,因此把(編號1,進攻時間1)保存下來;同時讓通信兵帶信回去,內容為(Accepted);
B、將軍2收到了(編號1,進攻時間1),由于(編號1)小于已經保存的(編號2),因此讓通信兵帶信回去,內容為(Rejected,編號2);
7) 參謀2收到至少2個將軍的回復,再次派通信兵帶信給有答復的2個將軍,內容為(編號2,進攻時間2);
8) 將軍2和將軍3收到了(編號2,進攻時間2),和自己保存的編號相同,因此把(編號2,進攻時間2)保存下來,同時讓通信兵帶信回去,內容為(Accepted);
9) 參謀2收到至少2個將軍的(Accepted)內容,確認進攻時間已經被多數派接受;
10) 參謀1只收到了1個將軍的(Accepted)內容,同時收到一個(Rejected,編號2);參謀1重新發起提議,派通信兵帶信給3個將軍,內容為(編號3);
11) 3個將軍的情況如下
A、將軍1收到參謀1的提議,由于(編號3)大于之前保存的(編號1),因此把(編號3)保存下來;由于將軍1已經接受參謀1前一次的提議,因此讓通信兵帶信回去,內容為(編號1,進攻時間1);
B、將軍2收到參謀1的提議,由于(編號3)大于之前保存的(編號2),因此把(編號3)保存下來;由于將軍2已經接受參謀2的提議,因此讓通信兵帶信回去,內容為(編號2,進攻時間2);
C、 負責通知將軍3的通信兵被抓,因此將軍3沒收到參謀1的提議;
12) 參謀1收到了至少2個將軍的回復,比較兩個回復的編號大小,選擇大編號對應的進攻時間作為最新的提議;參謀1再次派通信兵帶信給有答復的2個將軍,內容為(編號3,進攻時間2);
13) 將軍1和將軍2收到了(編號3,進攻時間2),和自己保存的編號相同,因此保存(編號3,進攻時間2),同時讓通信兵帶信回去,內容為(Accepted);
14) 參謀1收到了至少2個將軍的(accepted)內容,確認進攻時間已經被多數派接受;
Paxos是對一個值達成一致,Multi-Paxos是連續多個Paxos instance來對多個值達成一致。Multi-Paxos協議中有一個Leader。Leader是系統中唯一的Proposal,在lease租約周期內所有提案都有相同的ProposalId,可以跳過prepare階段,議案只有accept過程,一個ProposalId可以對應多個Value,所以稱為Multi-Paxos。
Multi-Paxos協議是經典的Paxos協議的簡化版本,將原來2-Phase過程簡化為了1-Phase,從而加快了提交速度。Multi-Paxos要求在各個Proposer中有唯一的Leader,并由Leader唯一地提交value給各Acceptor進行表決,在系統中僅有一個Leader進行value提交的情況下,Prepare的過程就可以被跳過,而Leader的選舉則可以由Paxos Lease來完成。
在Paxos算法中,如果能夠選舉出一個leader,那么有助于提高投票的成功率。另外leader在多個決議的選舉中有很重要的作用(用于得到決議的連續id)。因此,如何通過某種方法得到一個leader就是PaxosLease所說明的。
Master選舉的過程如下:從眾多的Node中選擇一個作為Master,如果該Master 一直 alive則無需選舉,如果master crash,則其他的node進行選舉下一個master。選擇正確性的保證是:任何時刻最多只能有一個master。
邏輯上Master更像一把無形的鎖,任何一個節點拿到這個鎖,都可成為master,所以本質上Master選舉是個分布式鎖的問題,但完全靠鎖來解決選舉問題也是有風險的:如果一個Node拿到鎖,然后crash,會導致鎖無法釋放,即死鎖。一種可行的方案是給鎖加個時間(Lease),拿到鎖的Master只能在Lease有效期內訪問鎖定的資源,在Lease timeout后,其他Node可以繼續競爭鎖,從根本上避免了死鎖。
Master在拿到鎖后,如果一直alive,可以向其他node”續租“鎖,從而避免頻繁的選舉活動。
Paxos 算法的設計并沒有考慮到一些優化機制,同時論文中也沒有給出太多實現細節,因此后來出現了不少性能更優化的算法和實現,包括Fast Paxos、Multi-Paxos 等。
Raft算法由斯坦福大學的Diego Ongaro和John Ousterhout 2013年在論文《In Search of an Understandable Consensus Algorithm》中提出。Raft算法面向對多個決策達成一致的問題,是對Multi-Paxos的重新簡化設計和實現,分解了領導者選舉、日志復制和安全方面的考慮,并通過約束減少了不確定性的狀態空間。
Raft算法將一致性問題分解為領導選舉(leader election)、日志復制(log replication)、安全性(safety)三部分。
Raft算法包括領導者(Leader)、候選者(Candidate)和跟隨者(Follower)三種角色,決策前通過選舉一個全局的領導者來簡化后續的決策過程。領導者決定日志(log)的提交,日志只能由領導者向跟隨者單向復制。
Leader:集群中只有一個處于Leader狀態的服務器,負責響應所有客戶端的請求。
Follower:剛啟動時所有節點為Follower狀態,響應Leader的日志同步請求,響應Candidate的請求。
Candidate:Follower狀態服務器準備發起新的Leader選舉前需要轉換到的狀態,是Follower和Leader的中間狀態。
所有節點初始狀態都是Follower角色
超時時間內沒有收到Leader的請求則轉換為Candidate進行選舉
Candidate收到大多數節點的選票則轉換為Leader;發現Leader或者收到更高任期的請求則轉換為Follower
Leader在收到更高任期的請求后轉換為Follower
Term(任期):每個Leader都有自己的任期,任期到期就需要開始新一輪選舉,在每個任期內,可以沒有leader,但是不能出現大于兩個的leader。
Raft算法將整個系統執行時間劃分為若干個不同時間間隔長度的Term(任期)構成的序列,以遞增的數字來作為Term的編號;每個Term由Election開始,在任期內若干處于Candidate狀態的服務器競爭產生新的Leader,如果一個候選人贏得了選舉,就會在該任期的剩余時間擔任領導人;在某些情況下,選票會被瓜分,有可能沒有選出領導人,那么將會開始另一個任期,并且立刻開始下一次選舉。Raft算法保證在給定的一個任期最多只有一個領導人。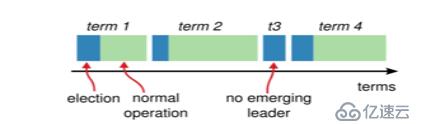
Raft算法典型的過程包括兩個主要階段:
(1)Leader選舉
當整個系統啟動時,所有服務器都處于Follower狀態;如果系統中存在Leader,Leader會周期性的發送心跳(AppendEntries RPC)來告訴其它服務器自己是Leader;如果Follower經過一段時間沒有收到任何心跳信息,則可以認為Leader不存在,需要進行Leader選舉。
在選舉前,Follower增加其Term編號并改變狀態為Candidate狀態,然后向集群內的其它服務器發出RequestVote RPC,Candidate狀態持續到發生下面三個中的任意事件:
A、贏得選舉:Candidate接受了大多數服務器的投票,成為Leader,然后向其它服務器發送心跳(AppendEntries RPC)告訴其它服務器。
B、其它服務器獲得選舉:Candidate在等待的過程中接收到自稱為Leader的服務器發送來的心跳(AppendEntries RPC),如果RPC的Term編號大于等于Candidate自身的Term編號,則Candidate承認Leader,自身狀態變成Follower;否則拒絕承認Leader,狀態依然為Candidate。
C、一段時間過后,如果沒有新的Leader產生,則Term遞增,重新發起選舉(因為有可能同時有多個Follower轉為Candidate狀態,導致分流,都沒有獲得多數票)。
(2)日志復制
Log復制主要作用是用于保證節點的一致性,所做的操作是為了保證一致性與高可用性;當Leader選舉出來后便開始負責客戶端的請求,所有請求都必須先經過Leader處理。Leader接受到客戶端請求后,將其追加到Log的尾部,然后向集群內其它服務器發出AppendEntries RPC,引發其它服務器復制新請求的操作,當大多數服務器復制完后,Leader將請求應用到內部狀態機,并將執行結果返回給客戶端。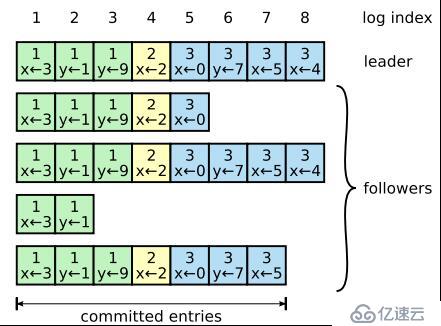
每個Log中的項目包含2個內容:操作命令本身和Term編號;還有一個全局的Log Index來指示Log項目在Log中的順序編號。當大多數服務器在Log中存儲了Log項目,則可認為Log項目是可以提交的,上圖中的Log Index為7前的Log項目都可以提交。
(3)安全性
安全性是用來保證每個節點都執行相同序列的安全機制,如當某個Follower在當前Leader提交命令時不可用,稍后可能該Follower又會被選舉為Leader,這時新Leader可能會用新的Log覆蓋先前已提交的Log,這就是導致節點執行不同序列;安全性就是用于保證選舉出來的Leader一定包含先前已經提交Log的機制。
為了達到安全性,Raft算法增加了兩個約束條件:
A、要求只有其Log包含了所有已經提交的操作命令的那些服務器才有權被選為Leader。
B、對于新Leader來說,只有它自己已經提交過當前Term的操作命令才被認為是真正的提交。
Raft算法已經被多種語言實現,如Go語言、C++、Python等主流開發語言。
Raft算法原理動畫演示:
http://thesecretlivesofdata.com/raft/
Raft共識算法資源如下:
https://raft.github.io/
Raft算法的Go語言實現:
https://github.com/goraft/raft
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





