溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
在開發帶數據庫的.NET系統中我使用過各種方式,包括直接使用ADO.NET、使用基于ADO.NET封裝的各類工具(其中有自己封裝的)、還有各類ORM類庫,比如NHibernate、MyBatisNet、Linq to SQL、Entity Framwrok等,在上面的工具或類庫中,MyBatisNet一段時間曾是我的最愛:由于它基于XML的配置可以靈活適應一些特殊的場景,不過有時候在面對中小型項目時又覺得MyBatisNet有些大材小用,此外還有一個原因是MyBatisNet這個基于Java的MyBatis改造而來的項目最近幾乎沒有更新了。
很早就聽說過Dapper這個類庫了,只不過一直沒有嘗試使用,但是很早就知道它是國外大型IT問答社區StackOverFlow最早開發并開源的。最近用了一下,感覺確實很方便。Dapper的源代碼放在github上托管,并且可以用NuGet方式添加到項目中,只不過我現在開發的桌面軟件有一部分用戶還在使用WindowsXP系統,因此不能使用高于.NET Framrwork4.5以上版本開發且開發工具是Visual Studio 2015,這也限制了我不能使用最新版本的Dapper,于是我選擇了Dapper 1.50.2這個版本。
我們可以在Visual Studio 2015中直接使用NuGet來添加,具體辦法就是“工具”-“NuGet包管理器”-“管理解決方案的BuGet程序包”,如下圖所示: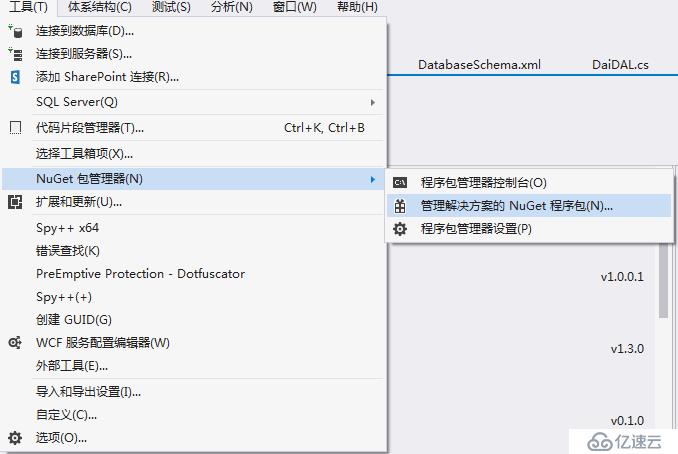
然后在彈出的窗口中搜索“Dapper”,如下圖所示: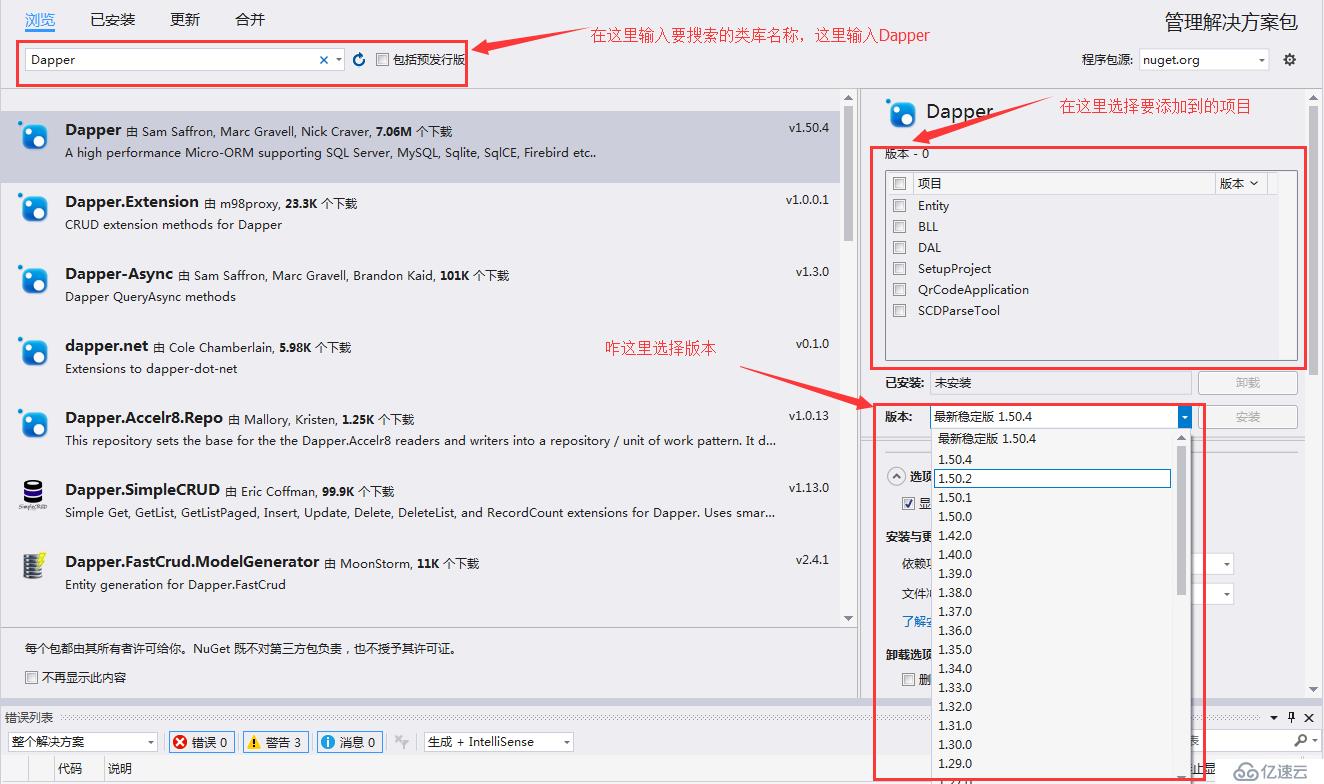
在上述界面中可以選擇安裝到當前解決方案的那些項目中,并且還可以指定Dapper的版本。
本文的描述都是針對Dapper 1.50.2版本。
擴展方法介紹
在介紹Dapper之前首先要介紹一下.NE中的擴展方法。擴展方法是.NET3.5添加的一個特性,使用擴展方法可以讓你為現有的類擴展方法而無需創建新的派生類。下面以一個例子來說明:
在我解析某個XML文件節點時,需要讀取某個節點的屬性,但是這個節點并不是一直有這個屬性值,如下:
<SubNetwork name="SF-SubNetWork" type="">
為了避免name屬性不存在時拋出異常,我必須先進行判斷,如下:
string name=string.Empty;
if (subNetworkNode.Attributes["name"] != null)
{
name=subNetworkNode.Attributes["name"].Value;
}如果一個XML節點里有幾個可能不存在的屬性時,就需要處處這樣判斷了,于是我對代碼進行了改進,針對此類情況定義了擴展方法,方法如下:
public static class ExtendMethodClass
{
/// <summary>
/// 獲取指定屬性的值,如果沒有設置指定屬性名,則返回空字符串
/// </summary>
/// <param name="attributes">XML節點的屬性集合</param>
/// <param name="attributeName">屬性名</param>
/// <returns></returns>
public static string GetAttributeValue(this XmlAttributeCollection attributes,string attributeName)
{
if (string.IsNullOrEmpty(attributeName))
{
throw new ArgumentNullException("attributeName", "不能為空");
}
if (attributes == null||attributes[attributeName]==null)
{
return string.Empty;
}
return attributes[attributeName].Value;
}
}這樣一來,原來的代碼就可以寫成如下了:
string name = subNetworkNode.Attributes.GetAttributeValue("name");初一看,就像是XmlAttributeCollection這類原來就有GetAttributeValue(string attributeName)這樣一個方法,其實這個方式是我們自己擴展的。
定義擴展方法有幾點:
1、定義擴展方法的類必須用static修飾,即必須為靜態類。
2、定義的擴展方法必須用static修飾,即必須為靜態方法,同時方法的第一個參數前必須加this修飾,this后必須是類名,表示為this后的類添加擴展方法,如本例中this XmlAttributeCollection attributes表示為XmlAttributeCollection這個類添加擴展方法,如果需要在方法體內訪問XmlAttributeCollection這個類的實例,通過后面的attributes參數即可(注意這個參數的名稱可以隨便取)。
Dapper介紹
通過上面的介紹,大家可以初步了解擴展方法是怎么回事。其實Dapper主要也是用了擴展方法為IDbConnection和IDataReader添加擴展方法,比如在SqlMapper.cs中有如下代碼為IDbConnection添加擴展方法(節選):
// <summary>
/// Execute parameterized SQL.
/// </summary>
/// <param name="cnn">The connection to query on.</param>
/// <param name="sql">The SQL to execute for this query.</param>
/// <param name="param">The parameters to use for this query.</param>
/// <param name="transaction">The transaction to use for this query.</param>
/// <param name="commandTimeout">Number of seconds before command execution timeout.</param>
/// <param name="commandType">Is it a stored proc or a batch?</param>
/// <returns>The number of rows affected.</returns>
public static int Execute(this IDbConnection cnn, string sql, object param = null, IDbTransaction transaction = null, int? commandTimeout = null, CommandType? commandType = null)
{
var command = new CommandDefinition(sql, param, transaction, commandTimeout, commandType, CommandFlags.Buffered);
return ExecuteImpl(cnn, ref command);
}
/// <summary>
/// Execute parameterized SQL.
/// </summary>
/// <param name="cnn">The connection to execute on.</param>
/// <param name="command">The command to execute on this connection.</param>
/// <returns>The number of rows affected.</returns>
public static int Execute(this IDbConnection cnn, CommandDefinition command) => ExecuteImpl(cnn, ref command);在SqlMapper.IDataReader.cs為IDataReader添加擴展方法的代碼(節選):
/// <summary>
/// Parses a data reader to a sequence of data of the supplied type. Used for deserializing a reader without a connection, etc.
/// </summary>
/// <typeparam name="T">The type to parse from the <paramref name="reader"/>.</typeparam>
/// <param name="reader">The data reader to parse results from.</param>
public static IEnumerable<T> Parse<T>(this IDataReader reader)
{
if (reader.Read())
{
var deser = GetDeserializer(typeof(T), reader, 0, -1, false);
do
{
yield return (T)deser(reader);
} while (reader.Read());
}
}
/// <summary>
/// Parses a data reader to a sequence of data of the supplied type (as object). Used for deserializing a reader without a connection, etc.
/// </summary>
/// <param name="reader">The data reader to parse results from.</param>
/// <param name="type">The type to parse from the <paramref name="reader"/>.</param>
public static IEnumerable<object> Parse(this IDataReader reader, Type type)
{
if (reader.Read())
{
var deser = GetDeserializer(type, reader, 0, -1, false);
do
{
yield return deser(reader);
} while (reader.Read());
}
}在本人2011年7月25日寫的一篇名為《利用ADO.NET的體系架構打造通用的數據庫訪問通用類》的博客當中介紹了ADO.NET的體系架構,如下圖: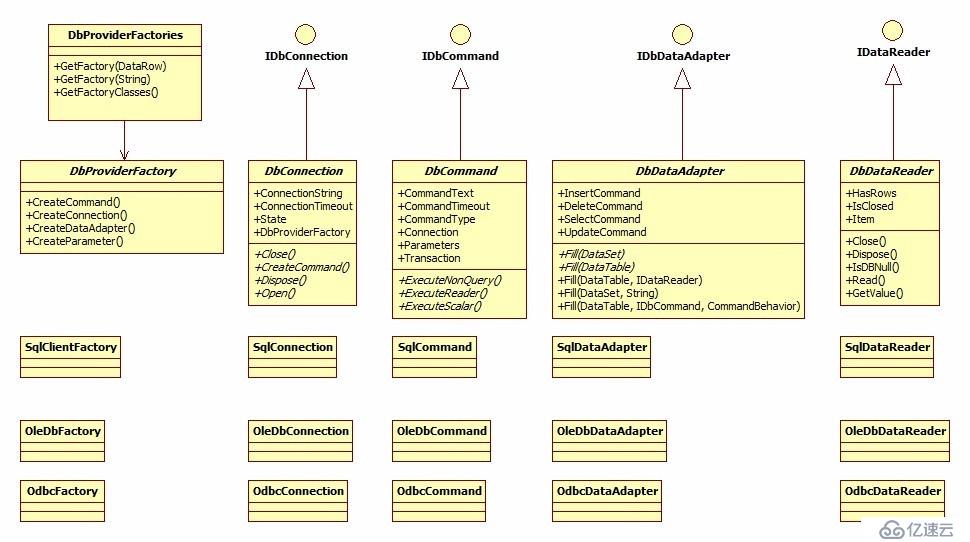
就是首先定義了一系列的借口,如IDbConnection之類的,任何基于數據庫訪問只要實現了接口的定義,就都能在.NET訪問,包括了微軟自己對SQL Server和Access等數據庫的實現以及MySQL和Oracle針對這個定義的第三方實現(其實JDBC也是這個道理,只不過是基于Java實現罷了)。因為包括SQL Server/MySQL/Oracle/PostgreSQL/SQLite在內的數據庫都實現了IDbConnection的定義,而Dapper又是基于IDbConnection的擴展,因此使用Dapper理論上可以訪問任何支持ADO.NET訪問的數據庫(前提是需要相關的數據庫驅動,dll形式)。
在使用Dapper的實際開發中,用得較多的還是針對IDbConnection的擴展方法,主要有:
int Execute():相當于Command.ExecuteNonQuery(),指定增加、刪除、修改SQL語句,返回受影響的行數。
object ExecuteScalar():相當于Command. ExecuteScalar(),返回結果集第一行第一列,用于聚合函數等。
T ExecuteScalar<T>():相當于Command. ExecuteScalar(),返回結果集第一行第一列,不過返回的結果指定了具體類型。
IDataReader ExecuteReader():相當于Command. ExecuteReader()。
IEnumerable<dynamic> Query()
IEnumerable<T> Query<T>()
IEnumerable<object> Query()
IEnumerable<dynamic> Query()
dynamic QueryFirst()
dynamic QueryFirstOrDefault()
dynamic QuerySingle()
dynamic QuerySingleOrDefault()
IEnumerable<T> Query<T>()
T QueryFirst<T>()
T QueryFirstOrDefault<T>()
T QuerySingle<T>()
T QuerySingleOrDefault<T>()
IEnumerable<object> Query()
object QueryFirst()
object QueryFirstOrDefault()
object QuerySingle()
object QuerySingleOrDefault()
對于上面各種類型的Query和返回結果,就是分幾種情況:返回一個實現IEnumerable接口的結果集,返回單個結果,返回單個結果或在沒有找到匹配結果下返回默認值(引用類型、數值類型、枚舉、日期等的默認值)
基本用法
使用了Dapper之后,在插入或者查詢時默認是按照數據庫字段名與類屬性名不區分大小寫的情況下對應。
加入有在SQL Server中有如下表:
CREATE TABLE IF NOT EXISTS tblBay (
Id integer NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
Name nvarchar(50) not null,
Desc nvarchar(100) not null
)同時有如下類定義:
public class Bay
{
public int ID { get; set; }
public string Name { get; set; }
public string Desc { get; set; }
}那么插入可以這么寫:
string connectionString = ".";//將這里改成你自己的數據庫連接字符串
string sqlInsert = "INSERT INTO tblBay(Name,Desc)VALUES(@Name,@Desc)";
SqlConnection connection = new SqlConnection(connectionString);
Bay bay = new Bay { Name = "test", Desc = "desc" };
connection.Execute(sqlInsert, bay);查詢可以這么寫:
string connectionString = ".";//將這里改成你自己的數據庫連接字符串
string sqlQuery = "select * from tblBay where Id=@Id";
int id = 1;
SqlConnection connection = new SqlConnection(connectionString);
IEnumerable<Bay> bayList = connection. QueryFirstOrDefault<Bay>(sqlQuery,new { @Id = id });字段與屬性不一致情況下關聯
但是在某些情況下,比如使用MySQL數據庫時我們可能會在由多個單詞構成的字段名之間以下劃線分割,如”user_id”、”user_name”等,而定義實體類時我們又將實體類的屬性定義為UserId、UserName,那么就需要為他們之間建立關聯,比較簡單的一種方式就是在select的時候使用as。
假定在MySQL中存在如下表:
CREATE TABLE IF NOT EXISTS tblperson (
user_id integer NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
user_name nvarchar(50) not null,
email nvarchar(100) not null
)而對應的實體類為:
public class Person
{
public int UserId { get; set; }
public string UserName { get; set; }
public string Email { get; set; }
}那么插入可以這么寫:
string connectionString = ".";//將這里改成你自己的數據庫連接字符串
string sqlInsert = "INSERT INTO tblperson(user_name,email)VALUES(@Name,@Email)";
SqlConnection connection = new SqlConnection(connectionString);
Person person = new Person { UserName = "test", Email = "email@email.com" };
DynamicParameters parameters = = new DynamicParameters();
parameters.Add("@Name", person.UserName);
parameters.Add("@Email", person.Email);
connection.Execute(sqlInsert, parameters);查詢可以這么寫:
string connectionString = ".";//將這里改成你自己的數據庫連接字符串
string sqlQuery = "select user_id as userId,user_name as username,email from tblperson where user_id=@UserId";
int userId = 1;
SqlConnection connection = new SqlConnection(connectionString);
DynamicParameters parameters = = new DynamicParameters();
parameters.Add("@UserId ", userId);
IEnumerable<Person> bayList = connection. QueryFirstOrDefault<Person>(sqlQuery, parameters);也就是數據庫字段名與實體類屬性名如果忽略大小寫的情況下是一致的,則我們無需單獨處理它們之間的映射關系,如果數據庫字段名與實體類屬性在忽略大小寫的情況下仍然不一致,那么我們需要手動處理映射:在INSERT、DELETE、UPDATE時可以通過DynamicParameters來處理;在SELECT時可以通過在SQL語句中使用AS來處理。
有關Dapper的更進一步用法可以查看Dapper的用戶手冊或直接查看源代碼。
周金橋
2018/04/22
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





