溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
面試題
為什么使用消息隊列?
消息隊列有什么優點和缺點?
Kafka、ActiveMQ、RabbitMQ、RocketMQ 都有什么區別,以及適合哪些場景?
面試官心理分析
其實面試官主要是想看看:
第一,你知不知道你們系統里為什么要用消息隊列這個東西?
不少候選人,說自己項目里用了 Redis、MQ,但是其實他并不知道自己為什么要用這個東西。其實說白了,就是為了用而用,或者是別人設計的架構,他從頭到尾都沒思考過。
沒有對自己的架構問過為什么的人,一定是平時沒有思考的人,面試官對這類候選人印象通常很不好。因為面試官擔心你進了團隊之后只會木頭木腦的干呆活兒,不會自己思考。
第二,你既然用了消息隊列這個東西,你知不知道用了有什么好處&壞處?
你要是沒考慮過這個,那你盲目弄個 MQ 進系統里,后面出了問題你是不是就自己溜了給公司留坑?你要是沒考慮過引入一個技術可能存在的弊端和風險,面試官把這類候選人招進來了,基本可能就是挖坑型選手。就怕你干 1 年挖一堆坑,自己跳槽了,給公司留下無窮后患。
第三,既然你用了 MQ,可能是某一種 MQ,那么你當時做沒做過調研?
你別傻乎乎的自己拍腦袋看個人喜好就瞎用了一個 MQ,比如 Kafka,甚至都從沒調研過業界流行的 MQ 到底有哪幾種。每一個 MQ 的優點和缺點是什么。每一個 MQ 沒有絕對的好壞,但是就是看用在哪個場景可以揚長避短,利用其優勢,規避其劣勢。
如果是一個不考慮技術選型的候選人招進了團隊,leader 交給他一個任務,去設計個什么系統,他在里面用一些技術,可能都沒考慮過選型,最后選的技術可能并不一定合適,一樣是留坑。
面試題剖析
為什么使用消息隊列
其實就是問問你消息隊列都有哪些使用場景,然后你項目里具體是什么場景,說說你在這個場景里用消息隊列是什么?
面試官問你這個問題,期望的一個回答是說,你們公司有個什么業務場景,這個業務場景有個什么技術挑戰,如果不用 MQ 可能會很麻煩,但是你現在用了 MQ 之后帶給了你很多的好處。
先說一下消息隊列常見的使用場景吧,其實場景有很多,但是比較核心的有 3 個:解耦、異步、削峰。
看這么個場景。A 系統發送數據到 BCD 三個系統,通過接口調用發送。如果 E 系統也要這個數據呢?那如果 C 系統現在不需要了呢?A 系統負責人幾乎崩潰......
解耦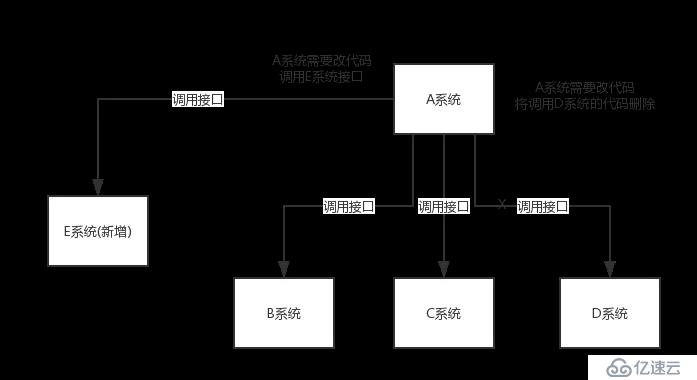
在這個場景中,A 系統跟其它各種亂七八糟的系統嚴重耦合,A 系統產生一條比較關鍵的數據,很多系統都需要 A 系統將這個數據發送過來。A 系統要時時刻刻考慮 BCDE 四個系統如果掛了該咋辦?要不要重發,要不要把消息存起來?頭發都白了啊!
如果使用 MQ,A 系統產生一條數據,發送到 MQ 里面去,哪個系統需要數據自己去 MQ 里面消費。如果新系統需要數據,直接從 MQ 里消費即可;如果某個系統不需要這條數據了,就取消對 MQ 消息的消費即可。這樣下來,A 系統壓根兒不需要去考慮要給誰發送數據,不需要維護這個代碼,也不需要考慮人家是否調用成功、失敗超時等情況。
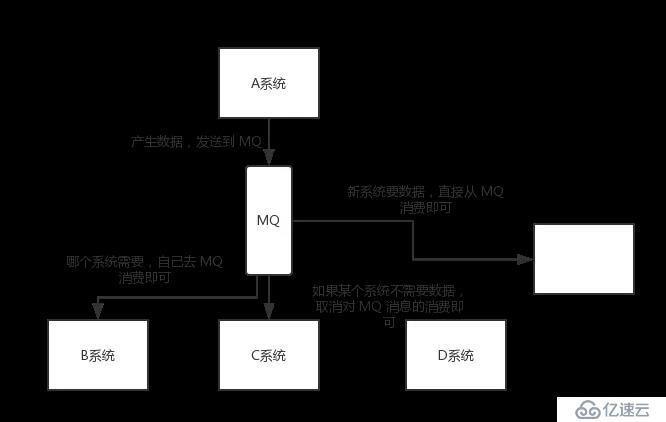
總結:通過一個 MQ,Pub/Sub 發布訂閱消息這么一個模型,A 系統就跟其它系統徹底解耦了。
面試技巧:你需要去考慮一下你負責的系統中是否有類似的場景,就是一個系統或者一個模塊,調用了多個系統或者模塊,互相之間的調用很復雜,維護起來很麻煩。但是其實這個調用是不需要直接同步調用接口的,如果用 MQ 給它異步化解耦,也是可以的,你就需要去考慮在你的項目里,是不是可以運用這個 MQ 去進行系統的解耦。在簡歷中體現出來這塊東西,用 MQ 作解耦。
異步
再來看一個場景,A 系統接收一個請求,需要在自己本地寫庫,還需要在 BCD 三個系統寫庫,自己本地寫庫要 3ms,BCD 三個系統分別寫庫要 300ms、450ms、200ms。最終請求總延時是 3 + 300 + 450 + 200 = 953ms,接近 1s,用戶感覺搞個什么東西,慢死了慢死了。用戶通過瀏覽器發起請求,等待個 1s,這幾乎是不可接受的。
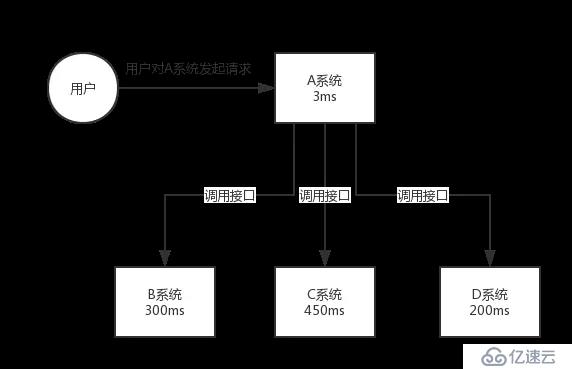 一般互聯網類的企業,對于用戶直接的操作,一般要求是每個請求都必須在 200 ms 以內完成,對用戶幾乎是無感知的。
一般互聯網類的企業,對于用戶直接的操作,一般要求是每個請求都必須在 200 ms 以內完成,對用戶幾乎是無感知的。
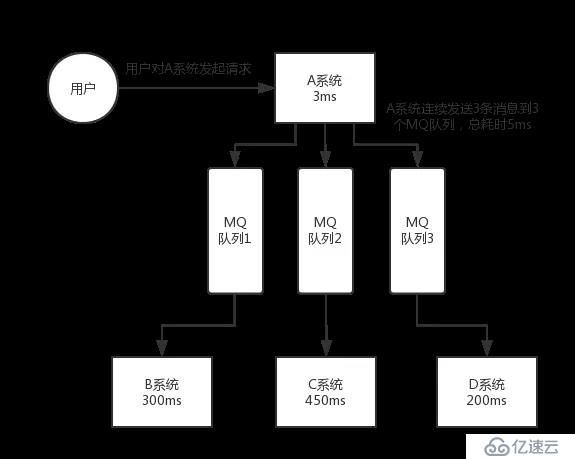
如果使用 MQ,那么 A 系統連續發送 3 條消息到 MQ 隊列中,假如耗時 5ms,A 系統從接受一個請求到返回響應給用戶,總時長是 3 + 5 = 8ms,對于用戶而言,其實感覺上就是點個按鈕,8ms 以后就直接返回了,爽!網站做得真好,真快!
削峰
每天 0:00 到 12:00,A 系統風平浪靜,每秒并發請求數量就 50 個。結果每次一到 12:00 ~ 13:00 ,每秒并發請求數量突然會暴增到 5k+ 條。但是系統是直接基于 MySQL 的,大量的請求涌入 MySQL,每秒鐘對 MySQL 執行約 5k 條 SQL。
一般的 MySQL,扛到每秒 2k 個請求就差不多了,如果每秒請求到 5k 的話,可能就直接把 MySQL 給打死了,導致系統崩潰,用戶也就沒法再使用系統了。
但是高峰期一過,到了下午的時候,就成了低峰期,可能也就 1w 的用戶同時在網站上操作,每秒中的請求數量可能也就 50 個請求,對整個系統幾乎沒有任何的壓力。
如果使用 MQ,每秒 5k 個請求寫入 MQ,A 系統每秒鐘最多處理 2k 個請求,因為 MySQL 每秒鐘最多處理 2k 個。A 系統從 MQ 中慢慢拉取請求,每秒鐘就拉取 2k 個請求,不要超過自己每秒能處理的最大請求數量就 ok,這樣下來,哪怕是高峰期的時候,A 系統也絕對不會掛掉。而 MQ 每秒鐘 5k 個請求進來,就 2k 個請求出去,結果就導致在中午高峰期(1 個小時),可能有幾十萬甚至幾百萬的請求積壓在 MQ 中。
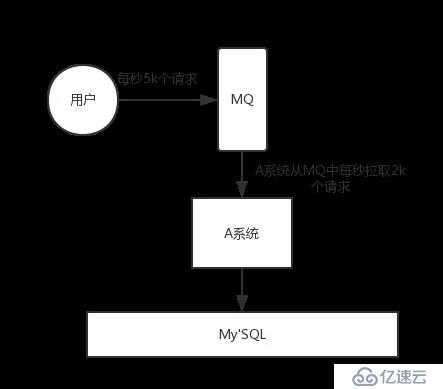
這個短暫的高峰期積壓是 ok 的,因為高峰期過了之后,每秒鐘就 50 個請求進 MQ,但是 A 系統依然會按照每秒 2k 個請求的速度在處理。所以說,只要高峰期一過,A 系統就會快速將積壓的消息給解決掉。
消息隊列有什么優缺點
優點上面已經說了,就是在特殊場景下有其對應的好處,解耦、異步、削峰。
缺點有以下幾個:
系統可用性降低
系統引入的外部依賴越多,越容易掛掉。本來你就是 A 系統調用 BCD 三個系統的接口就好了,人 ABCD 四個系統好好的,沒啥問題,你偏加個 MQ 進來,萬一 MQ 掛了咋整,MQ 一掛,整套系統崩潰的,你不就完了?
系統復雜度提高
硬生生加個 MQ 進來,你怎么保證消息沒有重復消費?怎么處理消息丟失的情況?怎么保證消息傳遞的順序性?頭大頭大,問題一大堆,痛苦不已。
一致性問題
A 系統處理完了直接返回成功了,人都以為你這個請求就成功了;但是問題是,要是 BCD 三個系統那里,BD 兩個系統寫庫成功了,結果 C 系統寫庫失敗了,咋整?你這數據就不一致了。
所以消息隊列實際是一種非常復雜的架構,你引入它有很多好處,但是也得針對它帶來的壞處做各種額外的技術方案和架構來規避掉,做好之后,你會發現,媽呀,系統復雜度提升了一個數量級,也許是復雜了 10 倍。但是關鍵時刻,用,還是得用的。
Kafka、ActiveMQ、RabbitMQ、RocketMQ 有什么優缺點?
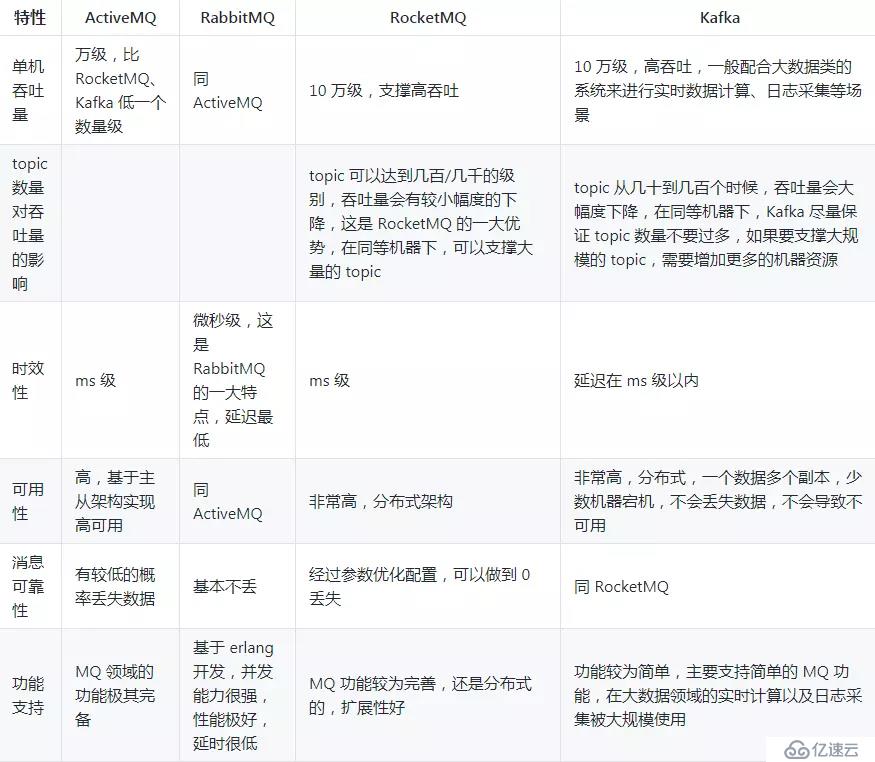
綜上,各種對比之后,有如下建議:
一般的業務系統要引入 MQ,最早大家都用 ActiveMQ,但是現在確實大家用的不多了,沒經過大規模吞吐量場景的驗證,社區也不是很活躍,所以大家還是算了吧,我個人不推薦用這個了;
后來大家開始用 RabbitMQ,但是確實 erlang 語言阻止了大量的 Java 工程師去深入研究和掌控它,對公司而言,幾乎處于不可控的狀態,但是確實人家是開源的,比較穩定的支持,活躍度也高;
不過現在確實越來越多的公司會去用 RocketMQ,確實很不錯,畢竟是阿里出品,但社區可能有突然黃掉的風險(目前 RocketMQ 已捐給 Apache,但 GitHub 上的活躍度其實不算高)對自己公司技術實力有絕對自信的,推薦用 RocketMQ,否則回去老老實實用 RabbitMQ 吧,人家有活躍的開源社區,絕對不會黃。
所以中小型公司,技術實力較為一般,技術挑戰不是特別高,用 RabbitMQ 是不錯的選擇;大型公司,基礎架構研發實力較強,用 RocketMQ 是很好的選擇。
如果是大數據領域的實時計算、日志采集等場景,用 Kafka 是業內標準的,絕對沒問題,社區活躍度很高,絕對不會黃,何況幾乎是全世界這個領域的事實性規范。
覺得不錯請點贊支持,歡迎留言或進我的個人群855801563領取【架構資料專題目合集90期】、【BATJTMD大廠JAVA面試真題1000+】,本群專用于學習交流技術、分享面試機會,拒絕廣告,我也會在群內不定期答題、探討。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





