溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
下文主要給大家帶來MySQL優化嵌套和分頁查詢流程的實例介紹,希望這些內容能夠帶給大家實際用處,這也是我編輯MySQL優化嵌套和分頁查詢流程的實例介紹這篇文章的主要目的。好了,廢話不多說,大家直接看下文吧。
優化嵌套查詢
嵌套查詢(子查詢)可以使用SELECT語句來創建一個單列的查詢結果,然后把這個結果作為過濾條件用在另一個查詢中。嵌套查詢寫起來簡單,也容易理解。但是,有時候可以被更有效率的連接(JOIN)替代。
現在假如要找出從來沒有在網站中消費的客戶,也就是查詢在客戶customer表中但是不在支付payment表中的客戶信息。
嵌套查詢:
explain select * from customer where customer_id not in (select customer_id from payment);

連接改寫:
explain select * from customer a left join payment b on a.customer_id = b.customer_id where b.customer_id is null;

畫外音:連接查詢效率更高的原因,是因為MySQL不需要在內存中創建臨時表來完成這個邏輯上需要兩個步驟的查詢工作;并且Not exists表示MYSQL優化了LEFT JOIN,一旦它找到了匹配LEFT JOIN標準的行, 就不再搜索了。
優化分頁查詢
在MySQL中做分頁查詢,MySQL 并不是跳過 offset 行,而是取 offset+N 行,然后返回放棄前 offset 行,返回 N 行,那當 offset 特別大的時候,效率就非常的低下。例如“limit 1000,20”,此時MySQL排序出前1020條數據后僅僅需要第1001到1020條記錄,前1000條數據都會被拋棄,查詢和排序的代價非常高。由此可見MySQL的分頁處理并不是十分完美,需要我們在分頁SQL上做一些優化,要么控制返回的總頁數,要么對超過特定閾值的頁數進行 SQL 改寫。
畫外音:控制返回的總頁數并不是那么靠譜,畢竟每頁的數據量也不能過大,數據多起來之后,控制返回的總頁數就變的不現實了。所以還是要對超過特定閾值的頁數進行 SQL 改寫。歡迎大家加入659270626,一起討論技術問題。
現在假設要對電影表film排序后取某一頁數據
explain select * from film order by title limit 50,5;

可以看到優化器實際上做了全表掃描,處理效率不高。
第一種優化思路
在索引上完成排序分頁的操作,最后根據主鍵關聯回表查詢所需要的其他列內容。
畫外音:此處涉及到了SQL優化的兩個重要概念,索引覆蓋和回表,我在前面的文章中詳細介紹過這兩個概念。通過索引覆蓋在索引上完成掃描和排序(索引有序),最后通過主鍵(InnoDB引擎索引會通過主鍵回表)回表查詢,最大限度減少回表查詢的I/O次數。
explain select * from film a inner join (select film_id from film order by title limit 50,5)b on a.film_id = b.film_id;

第二種優化思路
把LIMIT查詢轉換成某個位置的查詢,減少分頁翻頁的壓力。
假設現在每頁10條數據,要取第42頁的數據。
explain select * from film order by title limit 410,10;

現在需要多傳一個參數,就是上一頁(第41頁)的最后一條數據的主題title,
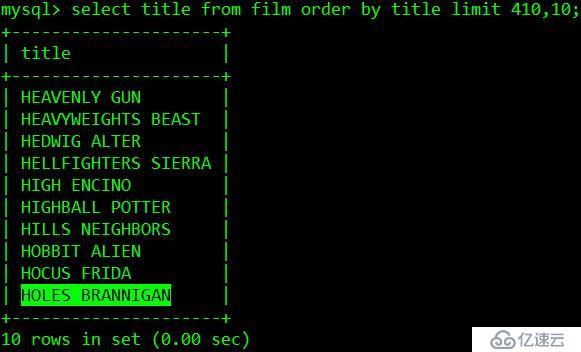
SQL可以改寫為:
explain select * from film where title>'HOLES BRANNIGAN' order by title limit 10;

這樣就把LIMIT m,n 轉換成了LIMIT n的查詢,但是這種方案只適合在不會出現重復值的特定環境,否則分頁結果可能會丟失數據。
對于以上關于MySQL優化嵌套和分頁查詢流程的實例介紹,大家是不是覺得非常有幫助。如果需要了解更多內容,請繼續關注我們的行業資訊,相信你會喜歡上這些內容的。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





